
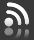
9 de Julio – Independencia Argentina
julio 9, 2020
Leer el artículo completo:
Principios-Fundamentales-de-la-Argentina

Información de Criptomonedas al alcance del IRS y la DEA
julio 8, 2020
EL MÁS GRANDE VENDEDOR DE «DÓLARES DIGITALES» TRAICIONÓ A SUS CLIENTES: REVELÓ TODA LA INFORMACIÓN Y HAY PÁNICO EN LA CITY
COINBASE PERDIÓ US$ 214 MILLONES: TRAICIONÓ A SUS CLIENTES Y VENDIÓ TODOS SUS DATOS PERSONALES A LA DEA Y AL GOBIERNO DE EE.UU.

La compañía de criptomonedas Coinbase confirmó nuevas regulaciones del Gobierno estadounidense. Desde ahora, la información personal será compartida con entes gubernamentales: Coinbase acordó la venta de su software de análisis y vigilancia de criptomonedas llamado “Coinbase Analytics” a dos agencias gubernamentales de EE.UU. La nueva exigencia provocó que una marea de clientes se retire de las criptomonedas.
Las dos agencias serán la DEA (Drug Enforcement Administration) y la Internal Revenue Service (IRS). Este software “desnuda” quién está detrás de la compra de criptomonedas: su nombre, su dirección, su edad, sus datos financieros, entre otros datos sensibles. Estas dos agencias tienen alcance no solo en EE.UU. sino a nivel mundial, por lo tanto, otras agencias podrán solicitar datos de transacciones en criptomonedas.
Coinbase cuenta con 14 millones de usuarios regulares y es uno de los exchanges más grandes de Estados unidos. Además, es una de las casas de cambio de criptomonedas más respetadas y reconocidas a nivel mundial. Por esta medida, los clientes dejaron de confiar en Coinbase y comenzaron a migrar a otros exchanges como Binance y Bitstamp: ya retiraron 22.000 Bitcoins y la empresa perdió más de US$ 214 millones en menos de siete días. Una caída récord para la compañía de Exchange cripto.
La compañía intentó calmar a sus clientes con un anuncio oficial: «Esta herramienta solo les ofrece acceso simplificado a los datos disponibles públicamente en la Blockchain. En ningún momento tienen acceso a los datos internos o de clientes de Coinbase», declararon.
Son propuestas ideales para aprovecharlas en cuarentena. Se trata de algunos cursos completos cuya duración promedio ronda las 7 semanas. Por qué conviene aprovecharlos
Luego de un informe oficial, dos tercios de los clientes están insatisfechos con la medida y quieren retirar todo su dinero cripto de Coinbase para cerrar sus cuentas definitivamente.
La compañía negó públicamente vender datos sensibles de los usuarios. Sin embargo, los usuarios desconfían de la seguridad de sus datos.
Qué es blockchain, la tecnología que llegó para revolucionar las finanzas cripto
El Blockchain (o cadena de bloques) es una base de datos compartida que funciona como un libro para el registro de operaciones de compra-venta o cualquier otra transacción. Es la base tecnológica del funcionamiento del bitcoin, por ejemplo. Consiste en un conjunto de apuntes que están en una base de datos compartida on-line en la que se registran mediante códigos las operaciones, cantidades, fechas y participantes. Al utilizar claves criptográficas y al estar distribuido por muchos ordenadores (personas) presenta ventajas en la seguridad frente a manipulaciones y fraudes. Una modificación en una de las copias no serviría de nada, sino que hay que hacer el cambio en todas las copias porque la base es abierta y pública.
El blockchain es un método para registrar datos, una especie de archivo de Excel. Pero está compartido: existen copias en la Red y en los ordenadores de cada participante en la creación y modificación de ese archivo, al que no puede acceder cualquier persona sin permiso y en el que no se puede borrar información, solo añadir nuevos registros. Esto permite que la colectividad se encargue de proteger los datos que contiene, alertando de posibles faltas de concordancia derivadas de cada actualización. Gracias a ello, se protege la integridad del documento.
La forma en que funciona el blockchain permite que todos los participantes conozcan los movimientos y cambios que se han realizado en el documento, así como su autor. Al basarse en operaciones matemáticas, el blockchain es hasta ahora uno de los métodos más seguros que existen para crear, modificar, compartir y almacenar información, por lo que podría aplicarse a cualquier ámbito que necesitara realizar alguna de esas acciones, sobre todo si en ellas tienen que participan múltiples usuarios.
Fuente: infotechnology.com,07/07/20
Vincúlese a nuestras Redes Sociales:
LinkedIn YouTube Facebook Twitter


.
.
Biografía de Sherlock Holmes
julio 7, 2020
Valdemar y su Canon; elemental, querido Holmes
Por María José Solano.

«Pensar de tarde en tarde en Sherlock Holmes
es una de las buenas costumbres que nos quedan.»
Jorge Luis Borges, Los conjurados.
Sherlock Holmes de entre los muertos
Nieto de August Dupin, hijo del Dr. Joseph Belle e hijastro de Doyle, Sherlock Holmes nunca existió. Sin embargo Holmes entra en la exclusiva nómina de los personajes de carne y hueso más allá de la literatura. Se hace real porque el genio, el talento, la oportunidad y la grandeza confluyen en el tiempo y el espacio llenándolo de vida, como si nunca hubiese sido un mero producto de la imaginación de un médico escocés fracasado. Pero nada es casual. A Doyle, como a tantos de nosotros, lo salva la literatura. Hijo de padre borracho y depresivo, aprende a soportar el dolor gracias al refugio que su madre le inculca: la religión católica y los libros. De lo primero se termina curando sustituyendo a Dios por la Razón y la Ciencia. De lo segundo, afortunadamente nunca se repondría, muy al contrario, sus experiencias como cirujano en un ballenero y en un buque de la armada respectivamente, lo sentaron al otro lado de los libros no ya como lector sino como autor, escribiendo con tan solo 20 años sus primeros relatos.

Y así comenzó a forjarse el escritor en paralelo a su personaje: su gusto por la práctica del boxeo; sus estudios sobre venenos, su amistad con el médico forense Joseph Bell, y una fe cada vez más asentada en la inteligencia, la observación y la ciencia de la deducción, fueron dejando al azar, pieza bastante común en las novelas policiales de la época, fuera de la ecuación conandoyliana.
Todo esto, en fin, conduce a Sir Arthur frente su personaje, a la vez consagración universal y personal maldición: Sherlock Holmes, que es amado y odiado a partes iguales por su autor termina adueñándose del mismo al más puro estilo de novela gótica: la criatura fagocita al creador, lo supera y lo domina, y llega a ser tan poderoso que lo obliga incluso a bajar al inframundo y hacerlo regresar de entre los muertos.
Por eso no podía ser más que la Editorial Valdemar la que rescatara esta vez a los dos juntos, Sherlock Holmes y Doyle, de las turbulentas aguas del tiempo y tal vez, del olvido literario. Tantos apócrifos, guionistas, directores de cine, actores, aficionados y consagrados de las letras recurriendo una y otra vez a sus aventuras, terminaron por crear un universo a veces demasiado confuso, enredado y sucio de replicantes sherlockianos.
El Canon Sherlockiano de Valdemar con el impecable trabajo de Juan Antonio Molina Foix, revisa y ordena el conjunto de escritos (novelas y colecciones de relatos) de la autoría exclusiva de Arthur Conan Doyle, que componen la bibliografía del famoso detective.

Historia del Canon de Valdemar
En el año 2000 Valdemar se embarcó en lo que para alguno de nosotros es la aventura definitiva; única; imprescindible: la publicación de los 60 relatos (4 largos y 56 cortos) sherlockianos de Arthur Conan Doyle.
Esta colección de Sherlock Holmes/El Canon, con traducción, introducción y estudio a cargo de Juan Antonio Molina Foix, está compuesta por 9 volúmenes que son los que integran la narraciones completas originales del detective londinense siguiendo la prestigiosa edición de Oxford University Press, “The Oxford Sherlock Holmes” (1993).
Sherlock Holmes.
Este mes de abril de 2016 acaba de ver la luz el último volumen del Canon: El Archivo de Sherlock Holmes como sus antecesores, encuadernado en cartoné al cromo con las estupendas ilustraciones de portada de Cristina Belmonte Paccini, junto con numerosas notas y material gráfico. Y como no podía ser de otra manera, este último volumen nos reserva inquietantes sorpresas y giros narrativos inesperados. En los relatos que lo integran se aprecia un tono más duro y violento, cercano a la novela negra americana, como en Los tres Garrideb; aunque en otros podemos encontrar componentes de horror gótico (Shoscombe Old Place), elementos sobrenaturales (El vampiro de Sussex), o incluso de ciencia ficción (El hombre que reptaba), además de una novedad: en El soldado de la piel descolorida y La melena de león el narrador es el propio Holmes.
Con este objeto de 22×15 cm de felicidad absoluta, quizás el mejor libro del famoso detective, raro y difícil de encontrar en librerías hasta hoy, Valdemar cierra lo que sin duda es la edición definitiva de las aventuras completas de Sherlock Holmes en español.
Valdemar y sus hacedores
Constantes hasta la patología, frikis de lo imposible, perfeccionistas del terror, Rafael Díaz Santander y Juan Luis González componen una especie de monstruo bicéfalo cuyo cuerpo poderoso se llama Valdemar.
{kind=link}
La editorial Valdemar nace hace 27 años de la idea de dos chicos sin trabajo que se lanzan a la aventura de dedicarse a su pasión sin apenas medir las consecuencias de su osadía cambiando, como cualquier científico malévolo con su experimento, la vida de miles de personas; lectores a la caza de historias terroríficas contadas por los mejores autores cuyos nombres-una lista interminable-, quedarán ya para siempre ligados al de la editorial Valdemar: Poe, Maturin, Maupassant, De Quincey, Mary Shelley, E.T.A.Hoffmann, Bram Stoker, Gaston Leroux… .Los lectores españoles nos acostumbramos a buscar en las librerías aquellos libros bellamente encuadernados en tapa dura con sus portadas oscuras; sus títulos tentadores y sus sugerentes ilustraciones y a identificarlos como el portal de entrada hacia lugares insospechados y absolutamente deseables.
Porque al principio Valdemar era el misterio; lo prohibido; la literatura fantástica de adjetivos imposibles; de terribles desenlaces; de apocalípticos paisajes acogedores de donde nunca querías marchar; imposible abandonar sus páginas olorosas de buena tinta, de cuidada encuadernación y vibrantes ilustraciones pobladas de eruditos y de locos.
Los libros editados por Valdemar han tenido desde sus comienzos la capacidad de transformarse en objetos de singular belleza y calidad, reconocibles en los estantes de librerías y bibliotecas donde señorean sus lomos con dignidad de bibliófilo, orgullosos de su ya larga vida de más de un cuarto de siglo.
Con el tiempo y el entusiasmo suicida de Rafael y Juan Luis, Valdemar se descompone como un cadáver hermoso en fragmentos de inquietud literaria y así, la sombra inconfundible de la testa del macho cabrío se alarga para acoger a sus numerosas criaturas: el Club Diógenes; Clásicos; Avatares; Gran Difusión; Intempestivas; Planeta Maldito, Frontera, Grangaznate, Insomnia… Se trata de las colecciones que componen el catálogo de Valdemar, cada una con su especialidad y sus características singulares y reconocibles en continente y contenido; con sus títulos y autores cuidadosamente elegidos por estos editores para seguir alimentando la sed insaciable y vampírica de los diferentes lectores, aunque siempre con la intención común de abarcar un territorio literario a modo de Jano Bifronte, al rescate del autor histórico clásico u olvidado, tanto como al del escritor contemporáneo maldito y desconocido.
Ocho razones literarias para leer y releer a Sherlock Holmes
1) Fernando Savater confesó con fervor en su Infancia recuperada que “quizá no he amado a ningún personaje de ficción como a Sherlock Holmes”.
2) Borges no sólo reconoce su agrado por el héroe, sino que incluso le dedicó un bello poema donde registra, entre otras evocaciones, que “en Baker Street vive solo y aparte. Le es ajeno también ese otro arte, el olvido”.
3) Cuando T.S. Eliot murió, su viuda confesó a algunos amigos y biógrafos que su esposo solía leerle en voz alta las aventuras de Sherlock Holmes mientras ella le zurcía sus medias.
{kind=link}

4) Umberto Eco y Thomas Sebeok editaron un grueso volumen, El signo de los tres, donde concitaron a un conjunto de especialistas para analizar y evaluar las derivaciones literarias, semióticas, sociológicas, psicológicas, entre otras ramificaciones reflexivas, de la obra policíaca de Arthur Conan Doyle.
5) Pérez- Reverte recuperó al personaje de Irene Adler (La Mujer, querido Watson), envolviéndola en una personalidad diabólica y misteriosa, demostrando en la que sin duda es una de sus más perfectas novelas, El Club Dumas, que es posible la interpretación posmoderna del mito sherlockiano.
6) Además de Dickens, nadie había logrado comunicar la atmósfera victoriana con tanto realismo.
7) Richard Lancelyn Green se ocupó de la titánica tarea de seleccionar, de entre cientos de miles de cartas, una muestra representativa (Letters to Sherlock Holmes), ordenada en diez gruesas categorías, de aquellas misivas dirigidas a Sherlock Holmes en donde lo felicitan por su labor, solicitan su consejo o su presencia para resolver un problema o, sencillamente, lo requerían para conversar como si de una persona de carne y hueso se tratase.
8) Quizá uno de los homenajes modernos más entrañables es el que logró Eco con su novela El nombre de la rosa, donde apenas se disfraza la traslación de Holmes por Baskerville, tanto el detective londinense como el fraile de Oxford exhiben cualidades y rasgos prácticamente indistinguibles.
Fuente: hzendalibros.com
.
.
Los orígenes de la Ciencia Económica
julio 4, 2020
Los verdaderos fundadores de la economía: la Escuela de Salamanca

Por Llewellyn H. Rockwell Jr.
Los estudiantes de la libre empresa normalmente remontan los orígenes del pensamiento pro-mercado al profesor escocés Adam Smith (1723–1790). Esta tendencia a ver a Smith como origen de la economía está reforzada entre los estadounidenses porque su famoso libro Una investigación de la naturaleza y causa de la riqueza de las naciones fue publicado el año de la independencia estadounidense de Gran Bretaña.
Hay muchas cosas que olvida esta visión de la historia intelectual. Los fundadores reales de la ciencia económica en realidad escribieron cientos de años antes que Adam Smith. No eran economistas como tales, sino teólogos morales, formados en la tradición de Santo Tomás de Aquino y se los conoce colectivamente como los escolásticos tardíos. Estos hombres, la mayoría de los cuales enseñaron en España, eran al menos tan favorables al libre mercado como la tradición escocesa muy posterior. Además, sus fundamentos teóricos eran todavía más sólidos: anticiparon las teorías del valor y del precio de los “marginalistas” de la Austria de finales del siglo XIX.1
Si las ciudades-estado italianas iniciaron el Renacimiento en el siglo XV, España y Portugal investigaron el nuevo mundo en el XVI y emergieron como centros de comercio y empresa. Intelectualmente, las universidades españolas engendraron una recuperación del gran proyecto escolástico: partir de las tradiciones antigua y cristiana para investigar y expandir todas las ciencias, incluyendo la economía, sobre la base firme de la lógica y la ley natural.
Como la ley natural y la razón son ideas universales, el proyecto escolástico era una búsqueda de las leyes universales que gobiernan la manera en que funciona el mundo. Y aunque la economía no se consideraba una ciencia independiente, estos investigadores se dirigían hacia el razonamiento económico como una forma de explicar el mundo que les rodeaba. Buscaban regularidades en el orden social y producían patrones católicos de justicia para actuar sobre él.
Francisco de Vitoria
La Universidad de Salamanca era el centro del aprendizaje escolástico en la España del siglo XVI. El primero de los teólogos morales en investigar, escribir y enseñar allí fue Francisco de Vitoria (1485–1546). Bajo su guía, la universidad ofrecía unas extraordinarias 70 cátedras profesorales. Como ha pasado con otros grandes maestros en la historia, la mayoría de la obra publicada de Vitoria nos ha llegado en forma de apuntes tomados por sus alumnos.
En el trabajo de Vitoria cobre economía, argumentaba que el precio justo es el precio al que se ha llegado de común acuerdo entre productores y consumidores. es decir, cuando un precio se fija por la interacción de oferta y demanda, es un precio justo. Lo mismo pasa con el comercio internacional. Los gobiernos no deberían interferir con los precios y relaciones establecidos entre comerciantes a través de fronteras. Las lecciones de Vitoria sobre comercio entre españoles e indios (publicadas originalmente en 1542 y de nuevo en 1917 por el Carnegie Endowment) argumentaban que la intervención de gobierno en el comercio violaba la regla de oro.
Aun así, la mayor contribución de Vitoria fue producir alumnos capaces y prolíficos. Estos pasaron a explorar casi todos los aspectos, morales y teóricos, de la ciencia económica. Durante un siglo, estos pensadores formaron una fuerza poderosa a favor de la libre empresa y la lógica económica. Consideraban el precio de los bienes y servicios como una consecuencia de las acciones de los comerciantes. Los precios varían dependiendo de las circunstancias, dependiendo del valor que las personas dan a los bienes. Ese valor depende a su vez de dos factores: la disponibilidad del bien y su uso. El precio de bienes y servicios es el resultado del funcionamiento de estas fuerzas. Los precios no están fijados por la naturaleza, ni determinados por los costes de producción: los precios son el resultado de la estimación común de los hombres.
Martín de Azpilicueta
Un alumno fue Martín de Azpilicueta (1493–1586), monje dominico, el más importante jurista canónico de su tiempo y que acabó siendo asesor de tres papas sucesivos. Usando el razonamiento, Azpilicueta fue el primer pensador económico que dijo clara e inequívocamente que la fijación de precios por el gobierno es un error. Cuando abundan los bienes, no hay necesidad de fijar un precio máximo; cuando no es así, el control de precios hace más mal que bien. En un manual sobre teología moral de 1556, Azpilicueta señalaba que no es pecado vender a un precio superior al oficial cuando es acordado por todas las partes.
Azpilicueta fue también el primero en decir abiertamente que la cantidad de dinero es lo que más influye a la hora de determinar su poder adquisitivo. “En igualdad de condiciones”, escribía, “en los países en los que hay una gran escasez de dinero, todos los demás bienes vendibles, e incluso las manos y el trabajo de los hombres, se entregan por menos dinero que allí donde es abundante”.
Para que una moneda establezca su precio correcto en términos de otras monedas, se intercambia con beneficio, una actividad que era polémica entre algunos teóricos por razones morales. Pero Azpilicueta argumentaba que intercambiar moneda no iba en contra de la ley natural. Este no era el propósito principal del dinero, pero “sin embargo es un uso secundario importante”. Hacía una analogía con otro bien del mercado. El propósito de los zapatos, decía, es proteger nuestros pies, pero eso no significa que no deban venderse obteniendo un beneficio. En su opinión, sería un error terrible cerrar los mercados de intercambio de moneda, como pedían algunos. El resultado “sería llevar al reino a la pobreza”.
Diego de Covarrubias
El alumno más importante de Azpilicueta fue Diego de Covarrubias y Leiva (1512–1577), considerado el mejor jurista de España desde Vitoria. El emperador le nombró Canciller de Castilla y acabó convirtiéndose en obispo de Segovia. Su libro Variarum (1554) fue la explicación más clara del origen del valor económico hasta la fecha. “El valor de un artículo”, decía, “no depende de su naturaleza esencial, sino de la estimación de los hombres, aunque esa estimación sea absurda”. Parece algo muy sencillo, pero fue olvidado por economistas durante siglos, hasta que la Escuela Austriaca redescubrió esta “teoría subjetiva del valor” y la incorporó a la microeconomía.
Como todos estos teóricos españoles, Covarrubias creía que los dueños individuales de propiedades tenían derechos inviolables a esas propiedades. Una de las muchas polémicas del momento era si las plantas que producía medicinas tendrían que pertenecer a la comunidad. Algunos decían que había que señalar que la medicina no es el resultado de ningún trabajo o habilidad humanos. Pero Covarrubias decía que todo lo que crezca en un terreno debería pertenecer al propietario del terreno. Ese propietario incluso tiene derecho a impedir que medicinas valiosas lleguen al mercado y obligarle a venderlas es una violación de la ley natural.
Luis de Molina
Otro gran economista de la línea de pensadores de Vitoria fue Luis de Molina (1535–1601), uno de los primeros jesuitas en pensar sobre temas teóricos económicos. Aunque dedicado a la Escuela de Salamanca y sus logros, Molina enseñó en Portugal, en la Universidad de Coimbra. Fue el autor de un tratado en cinco tomos De Justitia et Jure (1593 y siguientes). Su contribución al derecho, la economía y la sociología fueron enormes y se realizaron varias ediciones de su tratado.
Entre todos los pensadores favorables al libre mercado de su generación, Molina fue el más coherente en su visión del valor económico. Como los demás escolásticos tardíos, estaba de acuerdo en que los bienes no se valoran “de acuerdo con su nobleza o perfección” sino según “su capacidad de servir a la utilidad humana”. Pero ofrecía este convincente ejemplo: las ratas, de acuerdo con su naturaleza son más “nobles” (están más altas en la jerarquía de la Creación) que el trigo. Pero las ratas “no son estimadas ni apreciadas por los hombres” porque “no son de utilidad para nada”.
El valor de uso de un bien concreto no es fijo entre las personas ni con el paso del tiempo. Cambia de acuerdo con las valoraciones individuales y la disponibilidad. Esta teoría también explica aspectos particulares de los bienes de lujo. Por ejemplo, ¿por qué una perla “que solo puede usarse para decorar”, tendría que ser más cara que el grano, el vino, la carne o los caballos? Parece que todas estas cosas son más útiles que una perla y son indudablemente más “nobles”. Como explicaba Molina, la valoración la realizan individuos y “podemos concluir que el precio justo para una perla depende del hecho de que algunos hombres quisieron concederle valor como objeto de decoración”.
Una paradoja similar que desconcertaba a los economistas clásicos era la paradoja de los diamantes y el agua. ¿Por qué el agua, que es más útil, tiene que tener un precio inferior al de los diamantes? Siguiendo la lógica escolástica, se debe a las valoraciones individuales y su relación con la escasez. La incomprensión de esto llevó a Adam Smith, entre otros, en la dirección equivocada.
Pero Molina entendía la importancia crucial de los precios de libre flotación y su relación con la empresa. Esto se debía en parte a sus muchos viajes y entrevistas con mercaderes de todo tipo. “Cuando un bien se vende en una región o lugar concreto a un precio concreto”, observaba, mientras esto se haga “sin fraude o monopolio o cualquier engaño”, entonces “ese precio debería considerarse como regla y medida para juzgar el justo precio de ese bien en esa región o lugar”. Sería, por tanto, injusto que el gobierno tratara de establecer un precio superior o inferior. Molina fue también el primero en explicar por qué los precios al detalle son más altos que los precios al por mayor: los consumidores compran en cantidades menores y están dispuestos a pagar más por unidades incrementales.
Los escritos más complejos de Molina se referían al dinero y el crédito. Como Azpilicueta antes que él, entendía la relación entre dinero y precios y sabía que la inflación derivaba de una mayor oferta monetaria. “Igual que la abundancia de los bienes hace que bajen los precios”, escribía (especificando que esto supone que la cantidad de dinero y el número de mercaderes permanecen igual), una “abundancia de dinero” hace que los precios aumenten (especificando que la cantidad de los bienes y el número de mercaderes permanecen igual). Llegaba a señalar cómo salarios, rentas e incluso dotes acaban aumentando en la misma proporción en la que aumenta la oferta monetaria.
Usaba este marco para rechazar los límites aceptados del cobro de intereses, o “usura”, un punto muy peliagudo para la mayoría de los economistas de este periodo. Argumentaba que debería ser permisible cobrar intereses sobre cualquier préstamo que implique una inversión de capital, incluso cuando el retorno no se llega a materializar.
La defensa de la propiedad privada de Molina se basaba en la creencia de que la propiedad estaba justificada en el mandamiento “no robarás”. Pero fue más allá que sus contemporáneos al dar también sólidos argumentos prácticos. Cuando la propiedad sea común, decía, no se cuidará y la gente luchará por consumirla. Lejos de promover el bien público, cuando la propiedad no se divida, las personas fuertes del grupo se aprovecharán de las débiles monopolizándola y consumiendo todos sus recursos.
Como Aristóteles, Molina también pensaba que la propiedad común garantizaría el fin de la generosidad y la caridad. Pero llegaba a argumentar que “las limosnas deberían darse a partir de los bienes privados y no de los comunes”.
En la mayoría de los escritos actuales sobre ética y pecado, se aplican distintos estándares al gobierno y a los individuos. Pero no en los escritos de Molina. Argumentaba que el rey puede, como rey, cometer diversos pecados mortales. Por ejemplo, si el rey concede un privilegio de monopolio a algunos, viola el derecho de los consumidores a comprar al vendedor más barato. Molina concluía que quienes se benefician están obligados por ley moral a compensar los daños que causan.
Vitoria, Azpilicueta, Covarrubias y Molina fueron cuatro de los más importantes entre más de una docena de pensadores extraordinarios que resolvieron difíciles problemas económicos mucho antes del periodo clásico. Formados en la tradición tomista, usaron la lógica para entender el mundo que les rodeaba y buscaron instituciones que promovieran la prosperidad y el bien común. Así que no es sorprendente que muchos de los escolásticos tardíos fueran apasionados defensores del libre mercado.
Los miembros de la Escuela de Salamanca no habrían sido engañados por las mentiras que dominan hoy la teoría y la política económicas modernas. Ojalá nuestra comprensión moderna pudiera de nuevo llevarnos a esa autopista abierta para nosotros hace más de 400 años.
[Publicado originalmente como “Free Market Economists: 400 Years Ago” en The Freeman, Septiembre de 1995]
- 1.El investigador que redescubrió a los escolásticos tardíos fue Raymond de Roover (1904-1972). Durante años sufrieron burlas e indiferencia e incluso se los llamó pre-socialistas en su pensamiento. Karl Marx era el “último de los escolásticos”, escribía R. H. Tawney. Pero de Roover demostró que casi toda la sabiduría convencional era errónea (Business, Banking, and Economic Thought, editado por Julius Kirchner [Chicago: University of Chicago Press, 1974]).
Joseph Schumpeter dio un enorme impulso a los escolásticos tardíos con su libro póstumo de 1954, Historia del análisis económico (Nueva York, Oxford University Press). “Fueron ellos”, escribía, “los que se acercaron más que cualquier otro grupo a ser los ‘fundadores’ de la economía científica”. Aproximadamente al mismo tiempo aparecía un libro de lecturas reunidas por Marjorie Grice-Hutchinson (The School of Salamanca [Oxford: Clarendon Press, 1952]). Más tarde apareció un trabajo interpretativo a escala completa (Early Economic Thought in Spain, 1177-1740 [Londres: Allen & Unwin, 1975]).
Author:
Contact Llewellyn H. Rockwell Jr.
Llewellyn H. Rockwell, Jr., is founder and chairman of the Mises Institute in Auburn, Alabama, and editor of LewRockwell.com.
Fuente: mises.org

.
.
El Impuesto de Sucesiones en Andalucía
julio 4, 2020
Crónicas del Robo Legalizado
La herencia socialista andaluza arruina a una familia: «Yo no he robado nada a nadie, sólo he heredado»
Por Borja Jiménez.
La Junta de Andalucía lleva diez años persiguiendo a Rocío por una deuda de medio millón de euros. Su delito: que su padre falleciera y le dejara una herencia. El impuesto de sucesiones ha arruinado la vida de esta joven que vive en la zona más pobre de Coria del Río (Sevilla), en una casa en la que se ganan la vida vendiendo comestibles y que nadie quiere comprar. La conflictiva zona, en la que las miradas persiguen a los forasteros, está llena de delincuencia y droga, lo que deja sin valor un inmueble por el que el Gobierno andaluz reclama a Rocío 500.000 euros.
El cambio de Gobierno en la Junta de Andalucía tras casi cuatro décadas de socialismo trajo consigo un gran avance en lo que respecta al impuesto de sucesiones: la bonificación del 99% del mismo a los familiares directos. En la práctica, supone la eliminación de este tributo a hijos y nietos del fallecido. Sin embargo, una de las tareas pendientes de Juanma Moreno es, según exigen desde Vox, la solución de los problemas de quienes ya viven arruinados por el impuesto socialista que, por cierto, la ministra de Hacienda, María Jesús Montero, quiere «armonizar», es decir, subir.
«Desde que falleció mi marido, hace ya diez años, ni duermo de noche ni duermo de día»
Quizás la ministra, que ha estado más de una década en la Junta socialista, debería conocer en primera persona casos como el de Rocío, a quien su Gobierno reclamaba, apenas una semana después de fallecer su padre, 210.000 euros por un inmueble que, en el mejor de los casos, se podría vender por 10.000 o 15.000 euros.

Al tratarse de una familia muy humilde, no pudieron pagar una deuda que, por intereses de demora, ya asciende a medio millón de euros. «Esto no está valorado en nada. Desde que falleció mi marido, hace ya diez años, ni duermo de noche ni duermo de día. Solo de pensar que estamos en la calle. Cualquier día Hacienda puede entrar y expropiarlo», explica a OKDIARIO Faviola, madre de Rocío y viuda, por tanto, también en deuda con el Gobierno andaluz.
«¿Cómo voy a pagar 500.000 euros?»
«Mi padre muere y nos deja una pequeña herencia. Nos deja esta casa, con un pequeño negocio de comestibles, y dos pequeños solares que no son urbanizables. Al fallecer mi padre, nos empiezan a mandar cartas, y la deuda era ya de 210.000 euros. Al no pagar esa deuda, porque no teníamos dinero, pues empezó a subir y ya van por 500.000 euros», explica a OKDIARIO Rocío.
«Esto ahora mismo no vale nada. Yo vivo en un barrio humilde», suspira Rocío, que subraya que «esta casa no tiene el valor que ellos piden porque no me la compran». «Esta casa no me la compra nadie hoy en día», insiste.
Rocío pide a Juanma Moreno «que nos ayuden, que nos bajen la deuda, que no somos ricos… Que nosotros no nos negamos a pagar, pero que nos bajen la deuda para poder afrontar esta situación. Que no vivimos, no comemos… Estamos amargados. No sabemos qué hacer». «Yo no le he robado nada a nadie, que yo solo he heredado», concluye.
La pareja de Rocío también lamenta la situación: «Yo lo veo y no me lo creo. Ella tiene su vida embargada. No puede tener un coche o casarse o tener cualquier otra cosa porque directamente se lo quitan todo».
Vox pide la eliminación total
Rocío recibía este sábado a varios políticos de Vox, entre los que se encontraban Reyes Romero, diputada en el Congreso de Vox, y Javier Cortés, presidente de la gestora de la formación en Sevilla, que reconocen a este periódico que se encuentran en plena campaña contra los okupas y también contra el impuesto de sucesiones.
«Me ha emocionado mucho conocer su historia. Su situación. La situación de esta familia y de tantas otras que están afectadas por un injusto impuesto como es el de sucesiones», explica a OKDIARIO Reyes Romero, que pide a la Administración que «revise estos casos» porque «son una injusticia».
«Nosotros pedimos la eliminación de este impuesto confiscatorio, tal y como dice la Constitución. Queremos que dejen vivir en paz a las familias de toda España», insiste Romero, que recuerda que, aunque en Andalucía la situación ha mejorado, «todavía queda mucho por conseguir, y sobre todo revisar expedientes como el de Rocío, u otros casos que iremos dando a conocer en las próximas semanas».
Fuente: okdiario.com, 29/06/20

Vincúlese a nuestras Redes Sociales: LinkedIn Twitter
.
.
La impronta del Imperio Español
julio 2, 2020
El Imperio Español fue estupendo
Tal vez es una batalla poco reconfortante el tratar de oponer un discurso a las imágenes. La potencia visual del “black lives matter” no es argumentativa, sino que de algún modo va del hecho al razonamiento, algo por otro lado muy típico del pensamiento progresista. Es decir, si alguien incendia una ciudad, obliga a todo el mundo a ponerse de rodillas o empieza a tirar estatuas, no lo tiene que justificar. Por el contrario, el discurso progresista viene a decir que si alguien empieza a quemar ciudades o tirar estatuas será que algún motivo tendrá. Hemos visto esta forma de pensar en acción muchas veces en relación al terrorismo, por ejemplo. Si había un grupo terrorista poniendo bombas y pegando tiros en la nuca a la gente, es que alguna justificación tenían que tener. Para acabar con el fenómeno había que encontrar las causas políticas del conflicto, no tratar de reprimir a los terroristas. Aunque este discurso puede parecer pacifista, en realidad es todo lo contrario del pacifismo. El que más mata más justificación tiene. A más bombas, más conflicto político y social se adivina como trasfondo. Si pones la bomba, será el discurso de progreso el que encuentre tu justificación. Si no eres capaz de poner bombas, no trates de generar un debate social. El que no quema contenedores evidencia la falta de respaldo social a su ideas. Obviamente esta teoría sólo funciona cuando la violencia la practica la izquierda. Lo hemos visto en Chile o lo estamos viendo en los EEUU. Los gobiernos democráticos tienen que arrodillarse ante los instigadores de las revueltas sociales.
Paradójicamente, a la par que un lado ya casi ha abandonado el discurso y simplemente actúa, utilizando la fuerza sin demasiados complejos, es cuando están quizá brotando en el otro lado más personas con más capacidad de oponer con brillantez un discurso refutatorio. Es el caso por ejemplo del canal de Youtube “Fortunata y Jacinta”, toda una prueba de que los discursos intensos y extensos, no necesariamente coincidentes con el nuestro, también pueden tener su público.
En el caso del “black lives matter” y su deriva antihispánica, materializada en los ataques a estatuas de personajes históricos españoles, incluso en la propia España, no es sin embargo un vídeo del canal lo que nos ha llamado la atención sino un trabajado artículo publicado en la cuenta paralela del canal en Twitter. El resumen corto de los 16 puntos que componen la reflexión es que el Imperio Español fue estupendo. Con matices, pero estupendo. Y he aquí el porqué de esta extravagante afirmación:
El caso es que, como respuesta a la intensificación de los ataques perpetrados contra símbolos históricos de tradición hispánica en EEUU y otros lugares del mundo, el pasado sábado 20 de junio publiqué en redes sociales 16 escuetos puntos tratando de explicar por qué España nunca se vio comprometida de modo sistemático ni con la explotación esclava, ni con la exclusión social, ni con la aniquilación deliberada de pueblos enteros por motivos raciales (incluyo traducción al inglés).

1º La prohibición de esclavizar al vencido la hace Isabel la Católica y esto supuso tal revolución conceptual que resultó incomprensible para mucha gente de la época. Las Leyes de Burgos (1512) establecen la naturaleza jurídica del indio como hombre libre con todos los derechos de propiedad.
2º No podía ser explotado y podía trabajar a cambio de un salario justo; se establecen horarios laborales, se exime del trabajo a los menores de catorce años, se respeta la situación social de los indios caciques y de sus descendientes, se prohíben los castigos físicos, etc.
3º El derecho de conquista se basaba en tres fuentes: el derecho romano, el medieval y el Pontificio. España cumplía con los tres, pero Carlos I detiene la conquista para determinar si es o no legítima desde el punto de vista moral.
4º En la Controversia de Valladolid se cuestionan estos tres derechos. De ahí sale la figura del “protector de indios” y el moderno Derecho de gentes. Nunca antes se había preguntado un pueblo vencedor dónde empezaban los derechos propios y dónde empezaban los del vencido.
5º Por primera vez en la historia el poder político se somete a la filosofía moral y son los juristas y teólogos de la Escuela de Salamanca quienes realizan esta labor prefigurando el Derecho internacional y los llamados “derechos humanos”.
6º Una de las primeras consideraciones que reconocieron los teólogos y juristas españoles del siglo XVI fue que las sociedades indígenas no eran amorfas (tal y como sugería el agustinismo político), sino que eran sociedades ya constituidas cuya formación implicaba el desarrollo de una racionalidad técnica, jurídica, artística y política.
7º El racionalismo tomista venció en España al agustinismo político, que fue el seguido por los protestantes. Este racionalismo tomista reconocía la racionalidad del indio y supuso, por eso, el reconocimiento también de sus derechos, entre otros el de ser propietarios de sus tierras.
8º Eso no quiere decir que la acción del Imperio español fuese angelical: hubo abusos individuales igual que los hay en nuestras sociedades actuales a pesar de la ONU, a pesar de la Declaración de Derechos Humanos del 48 y a pesar de nuestras avanzadas democracias y de nuestros refinados códigos penales. Por eso es tan importante la distinción entre finis operis y finis operantis que, de forma grosera, podría extrapolarse a otros ámbitos. Por ejemplo, ¿la norma objetiva de la policía en EEUU es masacrar negros? De cara a quienes cantan “el Estado opresor es un macho violador” ¿acaso la norma objetiva, positiva, del Estado español o del chileno es discriminar, violar o alentar el asesinato de mujeres?
9º En la América española se estipuló una educación legalmente interracial y, gracias a ello, muchos indios estudiaron y se dedicaron a las leyes. Tenían cátedras de lenguas indígenas, cuyo conocimiento era obligatorio para todos los religiosos que ejercieran la enseñanza.
10º Se fundaron 25 universidades en toda la América española. Los portugueses no fundaron universidades. La primera en Brasil data de 1913. ¿Qué decir del imperio alemán en África y el holandés en Oceanía? Y la muy culta Bélgica no abrió ni una sola universidad en el Congo.
11º Colegio San Pablo de Lima: biblioteca más importante del continente americano con más de 40.000 volúmenes (frente a los 4.000 de Harvard fundada en 1636), libros no precisamente dedicados a la doctrina católica sino a las matemáticas, la arquitectura, botánica, medicina, etc.
12º Cultura musical barroca en la América española: los pobladores locales ocuparon sus lugares en el coro, como solistas, instrumentistas, copistas, constructores de instrumentos, compositores e incluso maestros de capilla.
13º Al igual que Roma extendía sus instituciones allá donde fuera, con el derecho romano a la cabeza, así España replicaba en América los Cabildos, que eran pequeños parlamentos descentralizados en las ciudades y cumplían una función legislativa. Luego estaban las Reales Audiencias (ejecutivo) y la Legislación de Indias (judicial). El Imperio español es el primer heredero del Imperio romano cuyo objetivo es ponerse al servicio político de todas las partes, orientándose a elevar políticamente a las sociedades consideradas más primarias. Por eso los territorios españoles de ultramar no eran “colonias” (entendidas en el sentido abrasivo del término, más moderno). Eran provincias, “reinos” gobernados por virreyes.
14º Este sistema se había ido construyendo en la Península desde el siglo IX: Cortes donde está representado el pueblo, las primeras con campesinos libres que pueden elegir señor, con municipios de hombres libres y amplia capacidad de decisión.
15º El Imperio se consolida manteniendo algunas de las estructuras políticas preexistentes, como la figura de una nobleza indígena hereditaria, los llamados curacas, siendo ellos quienes ocuparon los cargos principales de estos cabildos.
16º Los nativos americanos fueron considerados como súbditos de la Corona, tan españoles como uno de Salamanca, hecho que fue interpretado por la Europa del norte como una transgresión contra la pureza racial y un atropello a la higiene moral.
En definitiva, es más fácil alinearse con ciertos zurcidores de la moral biempensante antes que enfrentarse a los hechos. Pero lo cierto es que todo esto lo aporta España objetivamente: no es una interpretación ideológica o interesada, sino una realidad que se ha ocultado a varias generaciones de españoles y de hispanoamericanos.
A riesgo de alargar aún más esta ya de por sí larga entrada, añadimos esta reflexión de la autora sobre las respuestas que suscitaron en las redes sociales los anteriores puntos. Para que nuestros lectores no sepan menos que los que leyeron el hilo en la cuenta original.
Hasta aquí el hilo presentado en redes sociales. Dicho hilo se viralizó en Twitter, dando lugar a un nutrido conjunto de objeciones, ampliaciones, precisiones y también insultos, simplificaciones y tergiversaciones de todo tipo. Este es el enlace a mi cuenta de Twitter por si queréis revisar el material que allí se ha generado: https://twitter.com/fortunayjacinta/s… Es interesante advertir que hasta hace muy pocos años, apenas quince, el Columbus day era celebrado en EEUU en honor de Italia (de forma extraoficial desde 1792; como fiesta federal a partir de 1934). Como ejemplo, lean estas declaraciones del presidente Truman: “Desde los días en que Colón descubrió América, incalculables miles de seres han venido al Nuevo Mundo desde las costas de Italia para contribuir con su esfuerzo a nuestra cultura y civilización. Ellos han seguido el trabajo de Cristóbal Colón, reviviendo el espíritu que él ejemplarizó y en este aniversario del afortunado final del intrépido viaje yo les saludo por la fiesta que ellos han representado en la historia de esta nación”.
Aquellos que niegan la existencia de la ideología antiespañola, dirigida geopolíticamente contra toda la comunidad hispana, tendrán que explicar por qué el dedo acusatorio que hoy día justifica el derribo de las estatuas de Cristóbal Colón en distintos puntos de EEUU no señala, culpabilizándola, a la nación italiana y a los italianos, sino que se dirige, imperturbable hacia España. Y que conste que Colón, en efecto, cometió excesos en América, razón por la que fue traído a la Península con los grilletes puestos y vilipendiado por las calles de Granada. Traigo, por tanto, el caso de Colón para evidenciar las contradicciones que se viven actualmente en EEUU respecto al juicio moral de determinados hitos de su historia. Lo que interesa subrayar es que mientras en EEUU esa ideología antiespañola puede servir para reforzarse internamente como nación, en los países hispanoamericanos y en España sirve para dirigir ese odio hacia dentro, creando facturas internas muy graves y un enorme extravío identitario.
Y prueba de ello es que quienes con más esfuerzo han atacado el citado hilo han sido españoles, mexicanos, colombianos, peruanos, bolivianos, etc. En este vídeo (incluyo texto del guion: http://www.nodulo.org/forja/forja052…. exponía hace pocos meses cómo a principios del XX insignes representantes de las naciones hispanoamericanas sí sabían que se encontraban en abierta confrontación dialéctica contra otras plataformas geopolíticas, sabían que el enemigo no era España y que en la unión podía estar la fuerza (por supuesto, tampoco buscaban una especie de armonicismo tontorrón con España, sino posibles alianzas frente a enemigos comunes). Por cierto, y para evitar suspicacias, sé bien que el ataque a los símbolos de tradición hispánica (estatuas de Cervantes, Isabel la Católica, Fray Junípero, Oñate, etc.) es sólo uno de los efectos del Black Lives Matter, fenómeno complejo que tiende a ser interpretado en clave dualista (globalismo aureolar versus patriotismo; demócratas contra republicanos; globalistas contra Trump, capitalistas industriales versus capitalistas financieros, etc.), pero que precisará de análisis más precisos. Salud a todos los hispanohablantes del mundo, a un lado y otro de los océanos.
Fuente: navarraconfidencial.com, 2020

Vincúlese a nuestras Redes Sociales: LinkedIn Twitter
.
.
El Teorema de Bayes en el Análisis de Inteligencia
julio 1, 2020
“Bayes ingenuo” en apoyo del análisis de inteligencia
Por José-Miguel Palacios.
Un interesante artículo de Juan Pablo Somiedo[1], aparecido a finales de 2018, nos recordaba que el teorema de Bayes[2], en su versión más elemental (lo que se suele llamar “Bayes ingenuo”) puede seguir siendo útil en análisis de inteligencia.
El teorema de Bayes en el análisis de inteligencia
Se puede argumentar que todo análisis de inteligencia es bayesiano en su naturaleza. En esencia consiste en obtener unas evidencias iniciales, simples fragmentos de una realidad bastante compleja, para formular después hipótesis explicativas, recolectar más evidencia y verificar cuál de nuestras hipótesis se ajusta mejor a la evidencia disponible. Algo que no es esencialmente distinto de la “lógica bayesiana”, es decir, de ir modificando nuestras valoraciones subjetivas iniciales a medida que vamos recibiendo evidencias más o menos consistentes con ellas.
En las décadas de 1960 y 1970 hubo varios intentos de utilizar directamente el teorema de Bayes para fines de análisis de inteligencia. Algunos de ellos han sido documentados en las publicaciones del Centro para el Estudio de la Inteligencia de la CIA[3]. Los resultados, sin embargo, no llegaron a ser plenamente convincentes. Y una de las razones principales fue que el mundo real resultó ser demasiado complejo para los modelos elementales que deben considerarse al utilizar “Bayes ingenuo”. Y es que estos modelos presuponen la invariabilidad de la situación inicial (oculta a nuestros ojos), así como la independencia absoluto de los sucesos que vamos considerando. Este problema puede resolverse mediante el uso de “redes bayesianas”[4] y los resultados son matemáticamente correctos, aunque aquí el principal problema radica en conseguir modelar correctamente la realidad. Es el enfoque que fue seleccionado para el programa Apollo[5] y otros similares.
A pesar de todo, y con las debidas precauciones, el uso de “Bayes ingenuo” puede ayudarnos en algunos casos a valorar la evidencia de que disponemos. Para que ello sea así, tendríamos que prestar atención a neutralizar las principales debilidades del método. A saber:
a) Deberíamos utilizar únicamente evidencia relativamente “reciente” (algo que, medido en tiempo, puede tener distintos significados dependiendo de los casos). El problema es que Bayes nos da información sobre una situación preexistente y oculta (por ejemplo, la decisión que puede haber adoptado un determinado líder político) fijando nuestra atención en sus manifestaciones visibles. Si la evolución de la situación es bastante lenta (por ejemplo, la soviética durante el brezhnevismo medio y tardío), podemos asumir que no cambia sustancialmente durante años, por lo que el momento de obtención es escasamente relevante para la valoración de la evidencia. En situaciones más dinámicas, como suelen ser la actuales, las posiciones de los líderes se están modificando continuamente como consecuencia de los cambios que se producen en el entorno. Evidencia relativamente antigua puede referirse a una “situación oculta” que ya no es actual. Por ello, deberíamos utilizar solo evidencia bastante nueva y, si la crisis continúa, prescindir de la más antigua en beneficio de otra más reciente.
b) En la medida de lo posible, el conjunto de las hipótesis debería cubrir la totalidad de las posibilidades existentes, y no debería existir ningún solape entre las diferentes hipótesis. En la práctica, este objetivo es casi imposible de alcanzar, aunque cuanto más nos acerquemos a él, más fiables serán los resultados que obtengamos al aplicar “Bayes ingenuo”.
c) Las evidencias (“Sucesos”) deberían ser de un “peso similar” y no estar relacionadas entre sí[6].

En la práctica
Hemos elaborado una hoja de Excel[7], con la esperanza de que pueda ayudar con los cálculos matemáticos que esta técnica requiere. Para rellenarla, seguiremos los siguiente pasos, sugeridos por Jessica McLaughlin[8]:
1) Creamos un conjunto de hipótesis mutuamente excluyentes y colectivamente exhaustivas relativas al fenómeno incierto que queremos investigar. Como ya hemos explicado, es, quizá, uno de los pasos más difíciles. En general, resulta complicado imaginar hipótesis que sean por completo mutuamente excluyentes (sin ningún solape entre ellas). Y no lo es menos conseguir que el conjunto de ellas agote todas las posibilidades.
2) Asignamos probabilidades previas (pr.previa, en nuestra hoja de cálculo) a cada una de las hipótesis. La probabilidad previa es nuestra estimación intuitiva de la probabilidad relativa de cada una de las hipótesis. Dado que son mutuamente excluyentes y que cubren todas las posibilidades, la suma de las probabilidades previas debe ser 1. En nuestra tabla, expresamos las probabilidades en tantos por ciento.
3) Ahora debemos ir incorporando los “Sucesos” que nos servirán para valorar las hipótesis. El método reajusta las probabilidades de las hipótesis después de cada suceso, por lo que estos pueden añadirse secuencialmente, según se van produciendo o según tenemos noticia de ellos. Una buena elección de sucesos es muy importante para que el método produzca resultados aceptables. Los sucesos deben tener valor diagnóstico (es decir, deben ser más o menos probables según cuál de las hipótesis es la correcta) y, en lo posible, de un “peso” (importancia) similar.
4) Según incorporamos “Sucesos” a la tabla, les asignamos “verosimilitudes” (“verosim.”, en nuestra hoja de cálculo), relativas a cada una de las hipótesis. Se trata para cada caso de la probabilidad estimada por el analista de que el suceso ocurra, suponiendo que la hipótesis que estamos considerando sea correcta. En la tabla, esta probabilidad la expresamos por un entero entre 0 y 100, siendo 0 la imposibilidad total, y 100 la seguridad completa (de que el suceso se producirá suponiendo que la hipótesis se verifica). Obviamente, la suma de todas las verosimilitudes no tiene por que ser la unidad (100% o, según la notación que utilizamos en nuestra tabla, 100).
La propia tabla recalculará las probabilidades de las hipótesis una vez que hayamos computado cada “Suceso”. En nuestra tabla, podemos encontrar estas probabilidades recalculadas en la columna G (“probab.”).
5) Reiteraremos el proceso según añadimos nuevos sucesos. En nuestra tabla, cada nuevo suceso está representado 10 filas más abajo del anterior. Si agotamos los predefinidos en la tabla, podemos añadir más copiando el último “bloque” diez filas más abajo.
Un ejemplo: Crisis de Crimea, marzo de 2020
El proceso puede verse mucho más claro con la ayuda de un ejemplo. Utilizaremos el de la crisis de Crimea de 2014, en particular las dos semanas que siguieron a la caída del Presidente ucraniano Yanukovich, el 21 de febrero. Hemos rellenado la hoja Excel con una serie de “Sucesos” y el resultado puede encontrarse en la hoja prueba_crimea.xlsx[9]. Se trata, evidentemente, de un supuesto didáctico en el que la elección su “Sucesos” y la determinación de las verosimilitudes están condicionados por el interés en ilustrar algunos de los posibles resultados.
Como vemos, la técnica nos permite calcular en todo momento las probabilidades de las diversas hipótesis, y mantener este cálculo actualizado según vamos recibiendo nueva información. Algunas observaciones interesantes:
- a) A fecha 6 de marzo de 2014, consideraríamos casi seguro (probabilidad del 90%) que la intención rusa sea anexionar la península de Crimea.
- b) Sin embargo, unos días antes (según la tabla) no estaría tan claro. El 1 de marzo la hipótesis de la anexión era ya la más probable (55%), pero aún calculábamos una probabilidad notable (39%) de que los rusos estuvieran intentando crear una república virtualmente independiente sin poner en cuestión (formalmente) las fronteras reconocidas (modelo “Transnistria”).
- c) Tan solo unos días antes, hacia el 25-26 de febrero, la hipótesis más probable era aún que los rusos estuvieran intentando impedir que el nuevo gobierno de Kiev tomara el control efectivo de Crimea (probabilidad del 63-68%).
Con la tabla, podemos fácilmente excluir como sospechoso de desinformación un suceso que hemos aceptado previamente, modificar la verosimilitud de sucesos pasados a la luz de nueva evidencia, o cambiar las probabilidades previas de las que hemos partido. En todos estos casos, la tabla nos recalcula automáticamente todas las probabilidades.
Bayes ingenuo y Análisis de Hipótesis Alternativas (ACH)
En el fondo, la técnica de Bayes ingenuo no es muy diferente del Análisis de Hipótesis Alternativas (ACH) de Heuers. La lógica subyacente es la misma (conocer una realidad oculta gracias al estudio de sus manifestaciones visibles) y la diferencia principal radica en la forma de atacar el problema: mientras Bayes ingenuo calcula las probabilidades relativas, ACH intenta descartar hipótesis por ser inconsistentes con la evidencia.
Para ilustrar mejor las diferencias entre estas dos técnicas, hemos elaborado una matriz (prueba ach_crimea.xlsx[10]) con los sucesos y las hipótesis del ejemplo sobre Crimea. Como sabemos, las diversas variantes de ACH se diferencian entre sí por la manera de contabilizar los resultados. En nuestro caso, marcaremos CC y contaremos 2 puntos cuando el suceso sea altamente consistente con la hipótesis, C (1 punto) cuando sea consistente, I (-1) cuando sea inconsistente y X (rechazo de la hipótesis) cuando sea incompatible. Con estas reglas, hemos llegado a los resultados que a continuación se indican:
a) La hipótesis de la Anexión parece la más probable, aunque seguimos atribuyendo una probabilidad considerable a la hipótesis del Caos. Las dos primeras hipótesis (Evitar el control de Kiev sobre la península y el modelo Transnistria) podrían ser descartadas.
b) Si elimináramos la última fila, es decir, si no tomáramos en consideración el suceso del 6 de marzo, las cuatro hipótesis seguirían siendo verosímiles, con dos de ellas (Anexión y Transnistria) vistas como claramente más probables.
Vemos, pues, que partiendo de una lógica similar, las dos técnicas nos conducen a resultados ligeramente distintos. Y en el proceso podemos apreciar algunos de los inconvenientes que cada una de ellas tiene:
a) En ACH el principal problema es que no siempre resulta fácil encontrar sucesos que desmientan alguna de las hipótesis (“coartadas”) por ser completamente incompatibles con ella. Y, en ocasiones, sucesos muy interesantes pueden ser sospechosos de desinformación.
b) En ausencia de “coartadas”, la puntuación en ACH depende mucho de la metodología de cálculo que se siga. La que hemos elegido es, quizá, excesivamente simple. Otras más complejas pueden resultar difíciles de aplicar (aunque hay programas informáticos que pueden servir de ayuda) y resultar en cierta medida arbitrarias.
c) El problema con Bayes ingenuo es que para muchos analistas no resulta intuitivo. El uso de la hoja Excel ayuda mucho a realizar los cálculos, pero puede oscurecer la lógica que hay detrás de ellos.
A modo de conclusión
a) El Teorema de Bayes no sirve para predecir el futuro, sino que nos ayuda a conocer una realidad pasada o presente que permanece oculta a nuestros ojos. Es obvio que si el Presidente del país X ha decidido invadir el país vecino Y, acabará haciéndolo, de no mediar alguna circunstancia que le haga cambiar de opinión. Pero lo que averiguamos no es el hecho futuro (que invadirá), sino el pasado (que ha tomado la decisión de hacerlo).
b) Bayes ingenuo (como también ACH) es más efectivo cuando se usa para estudiar una situación estable, cuando la evidencia se puede recolectar durante un período de tiempo suficientemente largo sin que la “incógnita” que intentamos resolver cambie apreciablemente. Porque cuando la “incógnita” cambia con relativa rapidez, como suele ser el caso durante las crisis actuales, diferentes observaciones realizadas en momentos distintos pueden ser producto de una “realidad oculta” que se ha modificado, que ya no es la misma. Por eso, si queremos que Bayes ingenuo funcione razonablemente bien con situaciones dinámicas, la recogida de datos debe realizarse en plazos de tiempo relativamente cortos. O debemos descartar los “sucesos” más antiguos, que pueden responder a una “realidad oculta” que ya no es real.
c) Más importante que las dos técnicas que hemos examinado en este post es la “lógica bayesiana” que subyace a ambas. En inteligencia (sobre todo, en inteligencia estratégica) es raro conseguir evidencias directas sobre la realidad que nos interesa. Esa realidad siempre permanece oculta a nuestros ojos y lo que podemos averiguar sobre ella es gracias a sus manifestaciones visibles.
d) Quien quiera ocultar una información valiosa no solo intentará protegerla de intentos directos de acceder a ella, sino que tendrá también en cuenta esas manifestaciones visibles, tan difíciles de ocultar. Y lo hará utilizando desinformación. Este es el principal problema para utilizar Bayes ingenuo (o ACH): distinguir la información correcta de la inexacta y de la desinformacón.
Y es que no resulta nada fácil ser un analista inteligente.
[1] SOMIEDO, J.P. (2018). El análisis bayesiano como piedra angular de la inteligencia de alertas estratégicas. Revista de Estudios en Seguridad Internacional, 4, 1: 161-176. DOI: http://dx.doi.org/10.18847/1.7.10. Para una lista de las interesantes aportaciones de Somiedo al estudio de la metodología del análisis de inteligencia, ver https://dialnet.unirioja.es/servlet/autor?codigo=3971893.
[2] Para una explicación rápida del teorema de Bayes, véase https://es.wikipedia.org/wiki/Teorema_de_Bayes.
[3] Puede verse, por ejemplo, FISK, C.F. (1967). The Sino-Soviet Border Dispute: A Comparison of the Conventional and Bayesian Methods for Intelligence Warning. CIA Center for the Study of Intelligence. https://www.cia.gov/library/center-for-the-study-of-intelligence/kent-csi/vol16no2/html/v16i2a04p_0001.htm (acceso: 08.062020).
[4] Los no familiarizados con las redes bayesianas pueden encontrar una introducción elemental de este concepto en https://es.wikipedia.org/wiki/Red_bayesiana.
[5] Ver STICHA, P., BUEDE, D. & REES, R.L. (2005). APOLLO: An analytical tool for predicting a subject’s decision making. En Proceedings of the 2005 International Conference on Intelligence Analysis. https://cse.sc.edu/~mgv/BNSeminar/ApolloIA05.pdf (acceso: 08.06.2020).
[6] Los que conozcan el histórico concurso de televisión Un, dos, tres, responda otra vez recordarán que una táctica muy eficaz para responder consistía en repetir un “objeto”, alterando alguna de sus características. Por ejemplo, si pedían “muebles que puedan estar en un comedor”, ir diciendo sucesivamente “silla blanca”, “silla negra”, “silla roja”, etc. Esta táctica aplicada a la técnica de “Bayes ingenuo” nos acabaría conduciendo inexorablemente a una hipótesis predeterminada. Claro que sería como hacernos trampas al solitario…
[7] El nombre de la hoja es bayes_excel.xlsx, y puede encontrarse en https://bit.ly/2An58uc.
[8] MCLAUGHLIN, J., & PATÉ-CORNELL, M.E. (2005). A Bayesian approach to Iraq’s nuclear program intelligence analysis: a hypothetical illustration. En 2005 International Conference on Intelligence Analysis. https://analysis.mitre.org/proceedings/Final_Papers_Files/85_Camera_Ready_Paper.pdf (acceso: 27.10.2018). También, MCLAUGHLIN, J. (2005). A Bayesian Updating Model for Intelligence Analysis:A Case Study of Iraq’s Nuclear Weapons Program. Honors Program in International Security Studies Center for International Security and Cooperation Stanford University.
[9] Puede accederse a ella en la siguiente dirección: https://bit.ly/30veoY3.
[10] Puede encontrarse en https://bit.ly/3dUsENL.
Fuente: serviciosdeinteligencia.com, 2020
Algoritmos Naive Bayes: Fundamentos e Implementación
¡Conviértete en un maestro de uno de los algoritmos mas usados en clasificación!
Por Víctor Román.
Victor RomanFollowApr 25, 2019 · 13 min read

Introducción: ¿Qué son los modelos Naive Bayes?
En un sentido amplio, los modelos de Naive Bayes son una clase especial de algoritmos de clasificación de Aprendizaje Automatico, o Machine Learning, tal y como nos referiremos de ahora en adelante. Se basan en una técnica de clasificación estadística llamada “teorema de Bayes”.
Estos modelos son llamados algoritmos “Naive”, o “Inocentes” en español. En ellos se asume que las variables predictoras son independientes entre sí. En otras palabras, que la presencia de una cierta característica en un conjunto de datos no está en absoluto relacionada con la presencia de cualquier otra característica.
Proporcionan una manera fácil de construir modelos con un comportamiento muy bueno debido a su simplicidad.
Lo consiguen proporcionando una forma de calcular la probabilidad ‘posterior’ de que ocurra un cierto evento A, dadas algunas probabilidades de eventos ‘anteriores’.

Ejemplo
Presentaremos los conceptos principales del algoritmo Naive Bayes estudiando un ejemplo.
Consideremos el caso de dos compañeros que trabajan en la misma oficina: Alicia y Bruno. Sabemos que:
- Alicia viene a la oficina 3 días a la semana.
- Bruno viene a la oficina 1 día a la semana.
Esta sería nuestra información “anterior”.
Estamos en la oficina y vemos pasar delante de nosotros a alguien muy rápido, tan rápido que no sabemos si es Alicia o Bruno.
Dada la información que tenemos hasta ahora y asumiendo que solo trabajan 4 días a la semana, las probabilidades de que la persona vista sea Alicia o Bruno, son:
- P(Alicia) = 3/4 = 0.75
- P(Bruno) = 1/4 = 0.25
Cuando vimos a la persona pasar, vimos que él o ella llevaba una chaqueta roja. También sabemos lo siguiente:
- Alicia viste de rojo 2 veces a la semana.
- Bruno viste de rojo 3 veces a la semana.
Así que, para cada semana de trabajo, que tiene cinco días, podemos inferir lo siguiente:
- La probabilidad de que Alicia vista de rojo es → P(Rojo|Alicia) = 2/5 = 0.4
- La probabilidad de que Bruno vista de rojo → P(Rojo|Bruno) = 3/5 = 0.6
Entonces, con esta información, ¿a quién vimos pasar? (en forma de probabilidad)
Esta nueva probabilidad será la información ‘posterior’.

Inicialmente conocíamos las probabilidades P(Alicia) y P(Bruno), y después inferíamos las probabilidades de P(rojo|Alicia) y P(rojo|Bruno).
De forma que las probabilidades reales son:

Formalmente, el gráfico previo sería:

Algoritmo Naive Bayes Supervisado
A continuación se listan los pasos que hay que realizar para poder utilizar el algoritmo Naive Bayes en problemas de clasificación como el mostrado en el apartado anterior.
- Convertir el conjunto de datos en una tabla de frecuencias.
- Crear una tabla de probabilidad calculando las correspondientes a que ocurran los diversos eventos.
- La ecuación Naive Bayes se usa para calcular la probabilidad posterior de cada clase.
- La clase con la probabilidad posterior más alta es el resultado de la predicción.
Puntos fuertes y débiles de Naive Bayes
Los puntos fuertes principales son:
- Un manera fácil y rápida de predecir clases, para problemas de clasificación binarios y multiclase.
- En los casos en que sea apropiada una presunción de independencia, el algoritmo se comporta mejor que otros modelos de clasificación, incluso con menos datos de entrenamiento.
- El desacoplamiento de las distribuciones de características condicionales de clase significan que cada distribución puede ser estimada independientemente como si tuviera una sola dimensión. Esto ayuda con problemas derivados de la dimensionalidad y mejora el rendimiento.
Los puntos débiles principales son:
- Aunque son unos clasificadores bastante buenos, los algoritmos Naive Bayes son conocidos por ser pobres estimadores. Por ello, no se deben tomar muy en serio las probabilidades que se obtienen.
- La presunción de independencia Naive muy probablemente no reflejará cómo son los datos en el mundo real.
- Cuando el conjunto de datos de prueba tiene una característica que no ha sido observada en el conjunto de entrenamiento, el modelo le asignará una probabilidad de cero y será inútil realizar predicciones. Uno de los principales métodos para evitar esto, es la técnica de suavizado, siendo la estimación de Laplace una de las más populares.
Proyecto de Implementación: Detector de Spam
Actualmente, una de las aplicaciones principales de Machine Learning es la detección de spam. Casi todos los servicios de email más importantes proporcionan un detector de spam que clasifica el spam automáticamente y lo envía al buzón de “correo no deseado”.
En este proyecto, desarrollaremos un modelo Naive Bayes que clasifica los mensajes SMS como spam o no spam (‘ham’ en el proyecto). Se basará en datos de entrenamiento que le proporcionaremos.
Haciendo una investigación previa, encontramos que, normalmente, en los mensajes de spam se cumple lo siguiente:
- Contienen palabras como: ‘gratis’, ‘gana’, ‘ganador’, ‘dinero’ y ‘premio’.
- Tienden a contener palabras escritas con todas las letras mayúsculas y tienden al uso de muchos signos de exclamación.
Esto es un problema de clasificación binaria supervisada, ya que los mensajes son o ‘Spam’ o ‘No spam’ y alimentaremos un conjunto de datos etiquetado para entrenar el modelo.
Visión general
Realizaremos los siguientes pasos:
- Entender el conjunto de datos
- Procesar los datos
- Introducción al “Bag of Words” (BoW) y la implementación en la libreria Sci-kit Learn
- División del conjunto de datos (Dataset) en los grupos de entrenamiento y pruebas
- Aplicar “Bag of Words” (BoW) para procesar nuestro conjunto de datos
- Implementación de Naive Bayes con Sci-kit Learn
- Evaluación del modelo
- Conclusión
Entender el Conjunto de Datos
Utilizaremos un conjunto de datos del repositorio UCI Machine Learning.
Un primer vistazo a los datos:

Las columnas no se han nombrado, pero como podemos imaginar al leerlas:
- La primera columna determina la clase del mensaje, o ‘spam’ o ‘ham’ (no spam).
- La segunda columna corresponde al contenido del mensaje
Primero importaremos el conjunto de datos y cambiaremos los nombre de las columnas. Haciendo una exploración previa, también vemos que el conjunto de datos está separado. El separador es ‘\t’.
# Importar la libreria Pandas
import pandas as pd# Dataset de https://archive.ics.uci.edu/ml/datasets/SMS+Spam+Collection
df = pd.read_table('smsspamcollection/SMSSpamCollection',
sep='\t',
names=['label','sms_message'])# Visualización de las 5 primeras filas
df.head()
Preprocesamiento de Datos
Ahora, ya que el Sci-kit learn solo maneja valores numéricos como entradas, convertiremos las etiquetas en variables binarias, 0 representará ‘ham’ y 1 representará ‘spam’.
Para representar la conversión:
# Conversion
df['label'] = df.label.map({'ham':0, 'spam':1})# Visualizar las dimensiones de los datos
df.shape()

Introducción a la Implementación “Bag of Words” (BoW) y Sci-kit Learn
Nuestro conjunto de datos es una gran colección de datos en forma de texto (5572 filas). Como nuestro modelos solo aceptará datos numéricos como entrada, deberíamos procesar mensajes de texto. Aquí es donde “Bag of Words“ entra en juego.
“Bag of Words” es un término usado para especificar los problemas que tiene una colección de datos de texto que necesita ser procesada. La idea es tomar un fragmento de texto y contar la frecuencia de las palabras en el mismo.
BoW trata cada palabra independientemente y el orden es irrelevante.
Podemos convertir un conjunto de documentos en una matriz, siendo cada documento una fila y cada palabra (token) una columna, y los valores correspondientes (fila, columna) son la frecuencia de ocurrencia de cada palabra (token) en el documento.
Como ejemplo, si tenemos los siguientes cuatro documentos:
['Hello, how are you!', 'Win money, win from home.', 'Call me now', 'Hello, Call you tomorrow?']
Convertiremos el texto a una matriz de frecuencia de distribución como la siguiente:

Los documentos se numeran en filas, y cada palabra es un nombre de columna, siendo el valor correspondiente la frecuencia de la palabra en el documento.
Usaremos el método contador de vectorización de Sci-kit Learn, que funciona de la siguiente manera:
- Fragmenta y valora la cadena (separa la cadena en palabras individuales) y asigna un ID entero a cada fragmento (palabra).
- Cuenta la ocurrencia de cada uno de los fragmentos (palabras) valorados.
- Automáticamente convierte todas las palabras valoradas en minúsculas para no tratar de forma diferente palabras como “el” y “El”.
- También ignora los signos de puntuación para no tratar de forma distinta palabras seguidas de un signo de puntuación de aquellas que no lo poseen (por ejemplo “¡hola!” y “hola”).
- El tercer parámetro a tener en cuenta es el parámetro
stop_words. Este parámetro se refiere a las palabra más comúnmente usadas en el lenguaje. Incluye palabras como “el”, “uno”, “y”, “soy”, etc. Estableciendo el valor de este parámetro por ejemplo enenglish, “CountVectorizer” automáticamente ignorará todas las palabras (de nuestro texto de entrada) que se encuentran en la lista de “stop words” de idioma inglés..
La implementación en Sci-kit Learn sería la siguiente:
# Definir los documentos
documents = ['Hello, how are you!',
'Win money, win from home.',
'Call me now.',
'Hello, Call hello you tomorrow?']# Importar el contador de vectorizacion e inicializarlo
from sklearn.feature_extraction.text import CountVectorizer
count_vector = CountVectorizer()# Visualizar del objeto'count_vector' que es una instancia de 'CountVectorizer()'
print(count_vector)

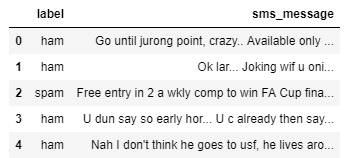
Para ajustar el conjunto de datos del documento al objeto “CountVectorizer” creado, usaremos el método “fit()”, y conseguiremos la lista de palabras que han sido clasificadas como características usando el método “get_feature_names()”. Este método devuelve nuestros nombres de características para este conjunto de datos, que es el conjunto de palabras que componen nuestro vocabulario para “documentos”.
count_vector.fit(documents)
names = count_vector.get_feature_names()
names
A continuación, queremos crear una matriz cuyas filas serán una de cada cuatro documentos, y las columnas serán cada palabra. El valor correspondiente (fila, columna) será la frecuencia de ocurrencia de esa palabra (en la columna) en un documento particular (en la fila).
Podemos hacer esto usando el método “transform()” y pasando como argumento en el conjunto de datos del documento. El método “transform()” devuelve una matriz de enteros, que se puede convertir en tabla de datos usando “toarray()”.
doc_array = count_vector.transform(documents).toarray()
doc_array

Para hacerlo fácil de entender, nuestro paso siguiente es convertir esta tabla en una estructura de datos y nombrar las columnas adecuadamente.
frequency_matrix = pd.DataFrame(data=doc_array, columns=names)
frequency_matrix

Con esto, hemos implementado con éxito un problema de “BoW” o Bag of Words para un conjunto de datos de documentos que hemos creado.
Un problema potencial que puede surgir al usar este método es el hecho de que si nuestro conjunto de datos de texto es extremadamente grande, habrá ciertos valores que son más comunes que otros simplemente debido a la estructura del propio idioma. Así, por ejemplo, palabras como ‘es’, ‘el’, ‘a’, pronombres, construcciones gramaticales, etc. podrían sesgar nuestra matriz y afectar nuestro análisis.
Para mitigar esto, usaremos el parámetro stop_words de la clase CountVectorizer y estableceremos su valor en inglés.
Dividiendo el Conjunto de Datos en Conjuntos de Entrenamiento y Pruebas
Buscamos dividir nuestros datos para que tengan la siguiente forma:
X_trainson nuestros datos de entrenamiento para la columna ‘sms_message’y_trainson nuestros datos de entrenamiento para la columna ‘label’X_testson nuestros datos de prueba para la columna ‘sms_message’y_testson nuestros datos de prueba para la columna ‘label’. Muestra el número de filas que tenemos en nuestros datos de entrenamiento y pruebas
# Dividir los datos en conjunto de entrenamiento y de test
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(df['sms_message'], df['label'], random_state=1)print('Number of rows in the total set: {}'.format(df.shape[0]))print('Number of rows in the training set: {}'.format(X_train.shape[0]))print('Number of rows in the test set: {}'.format(X_test.shape[0]))

Aplicar BoW para Procesar Nuestros Datos de Pruebas
Ahora que hemos dividido los datos, el próximo objetivo es convertir nuestros datos al formato de la matriz buscada. Para realizar esto, utilizaremos CountVectorizer() como hicimos antes. tenemos que considerar dos casos:
- Primero, tenemos que ajustar nuestros datos de entrenamiento (
X_train) enCountVectorizer()y devolver la matriz. - Sgundo, tenemos que transformar nustros datos de pruebas (
X_test) para devolver la matriz.
Hay que tener en cuenta que X_train son los datos de entrenamiento de nuestro modelo para la columna ‘sms_message’ en nuestro conjunto de datos.
X_test son nuestros datos de prueba para la columna ‘sms_message’, y son los datos que utilizaremos (después de transformarlos en una matriz) para realizar predicciones. Compararemos luego esas predicciones con y_test en un paso posterior.
El código para este segmento está dividido en 2 partes. Primero aprendemos un diccionario de vocabulario para los datos de entrenamiento y luego transformamos los datos en una matriz de documentos; segundo, para los datos de prueba, solo transformamos los datos en una matriz de documentos.
# Instantiate the CountVectorizer method
count_vector = CountVectorizer()# Fit the training data and then return the matrix
training_data = count_vector.fit_transform(X_train)# Transform testing data and return the matrix. Note we are not fitting the testing data into the CountVectorizer()
testing_data = count_vector.transform(X_test)
Implementación Naive Bayes con Sci-Kit Learn
Usaremos la implementación Naive Bayes “multinomial”. Este clasificador particular es adecuado para la clasificación de características discretas (como en nuestro caso, contador de palabras para la clasificación de texto), y toma como entrada el contador completo de palabras.
Por otro lado el Naive Bayes gausiano es más adecuado para datos continuos ya que asume que los datos de entrada tienen una distribución de curva de Gauss (normal).
Importaremos el clasificador “MultinomialNB” y ajustaremos los datos de entrenamiento en el clasificador usando fit().
from sklearn.naive_bayes import MultinomialNB
naive_bayes = MultinomialNB()
naive_bayes.fit(training_data, y_train)

Ahora que nuestro algoritmo ha sido entrenado usando el conjunto de datos de entrenamiento, podemos hacer algunas predicciones en los datos de prueba almacenados en ‘testing_data’ usando predict().
predictions = naive_bayes.predict(testing_data)
Una vez realizadas las predicciones el conjunto de pruebas, necesitamos comprobar la exactitud de las mismas.
Evaluación del modelo
Hay varios mecanismos para hacerlo, primero hagamos una breve recapitulación de los criterios y de la matriz de confusión.
- La matriz de confusión es donde se recogen el conjunto de posibilidades entre la clase correcta de un evento, y su predicción.
- Exactitud: mide cómo de a menudo el clasificador realiza la predicción correcta. Es el ratio de número de predicciones correctas contra el número total de predicciones (el número de puntos de datos de prueba).
- Precisión: nos dice la proporción de mensajes que clasificamos como spam. Es el ratio entre positivos “verdaderos” (palabras clasificadas como spam que son realmente spam) y todos los positivos (palabras clasificadas como spam, lo sean realmente o no)
- Recall (sensibilidad): Nos dice la proporción de mensajes que realmente eran spam y que fueron clasificados por nosotros como spam. Es el ratio de positivos “verdaderos” (palabras clasificadas como spam, que son realmente spam) y todas las palabras que fueron realmente spam.
Para los problemas de clasificación que están sesgados en sus distribuciones de clasificación como en nuestro caso. Por ejemplo si tuviéramos 100 mensajes de texto y solo 2 fueron spam y los restantes 98 no lo fueron, la exactitud por si misma no es una buena métrica. Podríamos clasificar 90 mensajes como no spam (incluyendo los 2 que eran spam y los clasificamos como “no spam”, y por tanto falsos negativos) y 10 como spam (los 10 falsos positivos) y todavía conseguir una puntuación de exactitud razonablemente buena.
Para casos como este, la precisión y el recuerdo son bastante adecuados. Estas dos métricas pueden ser combinadas para conseguir la puntuación F1, que es el “peso” medio de las puntuaciones de precisión y recuerdo. Esta puntuación puede ir en el rango de 0 a 1, siendo 1 la mejor puntuación posible F1.
Usaremos las cuatro métricas para estar seguros de que nuestro modelo se comporta correctamente. Para todas estas métricas cuyo rango es de 0 a 1, tener una puntuación lo más cercana posible a 1 es un buen indicador de cómo de bien se está comportando el modelo.
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_scoreprint('Accuracy score: ', format(accuracy_score(y_test, predictions)))print('Precision score: ', format(precision_score(y_test, predictions)))print('Recall score: ', format(recall_score(y_test, predictions)))print('F1 score: ', format(f1_score(y_test, predictions)))

Conclusión
- Una de las mayores ventajas que Naive Bayes tiene sobre otros algoritmos de clasificación es la capacidad de manejo de un número extremadamente grande de características. En nuestro caso, cada palabra es tratada como una característica y hay miles de palabras diferentes.
- También, se comporta bien incluso ante la presencia de características irrelevantes y no es relativamente afectado por ellos.
- La otra ventaja principal es su relativa simplicidad. Naive Bayes funciona bien desde el principio y ajustar sus parámetros es raramente necesario.
- Raramente sobreajusta los datos.
- Otra ventaja importante es que su modelo de entrenamiento y procesos de predicción son muy rápidos teniendo en cuenta la cantidad de datos que puede manejar.
Fuente: medium.com, 2019

Vincúlese a nuestras Redes Sociales:
LinkedIn YouTube Facebook Twitter
.
.