
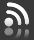
El Teorema de Bayes en el Análisis de Inteligencia
julio 1, 2020
“Bayes ingenuo” en apoyo del análisis de inteligencia
Por José-Miguel Palacios.
Un interesante artículo de Juan Pablo Somiedo[1], aparecido a finales de 2018, nos recordaba que el teorema de Bayes[2], en su versión más elemental (lo que se suele llamar “Bayes ingenuo”) puede seguir siendo útil en análisis de inteligencia.
El teorema de Bayes en el análisis de inteligencia
Se puede argumentar que todo análisis de inteligencia es bayesiano en su naturaleza. En esencia consiste en obtener unas evidencias iniciales, simples fragmentos de una realidad bastante compleja, para formular después hipótesis explicativas, recolectar más evidencia y verificar cuál de nuestras hipótesis se ajusta mejor a la evidencia disponible. Algo que no es esencialmente distinto de la “lógica bayesiana”, es decir, de ir modificando nuestras valoraciones subjetivas iniciales a medida que vamos recibiendo evidencias más o menos consistentes con ellas.
En las décadas de 1960 y 1970 hubo varios intentos de utilizar directamente el teorema de Bayes para fines de análisis de inteligencia. Algunos de ellos han sido documentados en las publicaciones del Centro para el Estudio de la Inteligencia de la CIA[3]. Los resultados, sin embargo, no llegaron a ser plenamente convincentes. Y una de las razones principales fue que el mundo real resultó ser demasiado complejo para los modelos elementales que deben considerarse al utilizar “Bayes ingenuo”. Y es que estos modelos presuponen la invariabilidad de la situación inicial (oculta a nuestros ojos), así como la independencia absoluto de los sucesos que vamos considerando. Este problema puede resolverse mediante el uso de “redes bayesianas”[4] y los resultados son matemáticamente correctos, aunque aquí el principal problema radica en conseguir modelar correctamente la realidad. Es el enfoque que fue seleccionado para el programa Apollo[5] y otros similares.
A pesar de todo, y con las debidas precauciones, el uso de “Bayes ingenuo” puede ayudarnos en algunos casos a valorar la evidencia de que disponemos. Para que ello sea así, tendríamos que prestar atención a neutralizar las principales debilidades del método. A saber:
a) Deberíamos utilizar únicamente evidencia relativamente “reciente” (algo que, medido en tiempo, puede tener distintos significados dependiendo de los casos). El problema es que Bayes nos da información sobre una situación preexistente y oculta (por ejemplo, la decisión que puede haber adoptado un determinado líder político) fijando nuestra atención en sus manifestaciones visibles. Si la evolución de la situación es bastante lenta (por ejemplo, la soviética durante el brezhnevismo medio y tardío), podemos asumir que no cambia sustancialmente durante años, por lo que el momento de obtención es escasamente relevante para la valoración de la evidencia. En situaciones más dinámicas, como suelen ser la actuales, las posiciones de los líderes se están modificando continuamente como consecuencia de los cambios que se producen en el entorno. Evidencia relativamente antigua puede referirse a una “situación oculta” que ya no es actual. Por ello, deberíamos utilizar solo evidencia bastante nueva y, si la crisis continúa, prescindir de la más antigua en beneficio de otra más reciente.
b) En la medida de lo posible, el conjunto de las hipótesis debería cubrir la totalidad de las posibilidades existentes, y no debería existir ningún solape entre las diferentes hipótesis. En la práctica, este objetivo es casi imposible de alcanzar, aunque cuanto más nos acerquemos a él, más fiables serán los resultados que obtengamos al aplicar “Bayes ingenuo”.
c) Las evidencias (“Sucesos”) deberían ser de un “peso similar” y no estar relacionadas entre sí[6].

En la práctica
Hemos elaborado una hoja de Excel[7], con la esperanza de que pueda ayudar con los cálculos matemáticos que esta técnica requiere. Para rellenarla, seguiremos los siguiente pasos, sugeridos por Jessica McLaughlin[8]:
1) Creamos un conjunto de hipótesis mutuamente excluyentes y colectivamente exhaustivas relativas al fenómeno incierto que queremos investigar. Como ya hemos explicado, es, quizá, uno de los pasos más difíciles. En general, resulta complicado imaginar hipótesis que sean por completo mutuamente excluyentes (sin ningún solape entre ellas). Y no lo es menos conseguir que el conjunto de ellas agote todas las posibilidades.
2) Asignamos probabilidades previas (pr.previa, en nuestra hoja de cálculo) a cada una de las hipótesis. La probabilidad previa es nuestra estimación intuitiva de la probabilidad relativa de cada una de las hipótesis. Dado que son mutuamente excluyentes y que cubren todas las posibilidades, la suma de las probabilidades previas debe ser 1. En nuestra tabla, expresamos las probabilidades en tantos por ciento.
3) Ahora debemos ir incorporando los “Sucesos” que nos servirán para valorar las hipótesis. El método reajusta las probabilidades de las hipótesis después de cada suceso, por lo que estos pueden añadirse secuencialmente, según se van produciendo o según tenemos noticia de ellos. Una buena elección de sucesos es muy importante para que el método produzca resultados aceptables. Los sucesos deben tener valor diagnóstico (es decir, deben ser más o menos probables según cuál de las hipótesis es la correcta) y, en lo posible, de un “peso” (importancia) similar.
4) Según incorporamos “Sucesos” a la tabla, les asignamos “verosimilitudes” (“verosim.”, en nuestra hoja de cálculo), relativas a cada una de las hipótesis. Se trata para cada caso de la probabilidad estimada por el analista de que el suceso ocurra, suponiendo que la hipótesis que estamos considerando sea correcta. En la tabla, esta probabilidad la expresamos por un entero entre 0 y 100, siendo 0 la imposibilidad total, y 100 la seguridad completa (de que el suceso se producirá suponiendo que la hipótesis se verifica). Obviamente, la suma de todas las verosimilitudes no tiene por que ser la unidad (100% o, según la notación que utilizamos en nuestra tabla, 100).
La propia tabla recalculará las probabilidades de las hipótesis una vez que hayamos computado cada “Suceso”. En nuestra tabla, podemos encontrar estas probabilidades recalculadas en la columna G (“probab.”).
5) Reiteraremos el proceso según añadimos nuevos sucesos. En nuestra tabla, cada nuevo suceso está representado 10 filas más abajo del anterior. Si agotamos los predefinidos en la tabla, podemos añadir más copiando el último “bloque” diez filas más abajo.
Un ejemplo: Crisis de Crimea, marzo de 2020
El proceso puede verse mucho más claro con la ayuda de un ejemplo. Utilizaremos el de la crisis de Crimea de 2014, en particular las dos semanas que siguieron a la caída del Presidente ucraniano Yanukovich, el 21 de febrero. Hemos rellenado la hoja Excel con una serie de “Sucesos” y el resultado puede encontrarse en la hoja prueba_crimea.xlsx[9]. Se trata, evidentemente, de un supuesto didáctico en el que la elección su “Sucesos” y la determinación de las verosimilitudes están condicionados por el interés en ilustrar algunos de los posibles resultados.
Como vemos, la técnica nos permite calcular en todo momento las probabilidades de las diversas hipótesis, y mantener este cálculo actualizado según vamos recibiendo nueva información. Algunas observaciones interesantes:
- a) A fecha 6 de marzo de 2014, consideraríamos casi seguro (probabilidad del 90%) que la intención rusa sea anexionar la península de Crimea.
- b) Sin embargo, unos días antes (según la tabla) no estaría tan claro. El 1 de marzo la hipótesis de la anexión era ya la más probable (55%), pero aún calculábamos una probabilidad notable (39%) de que los rusos estuvieran intentando crear una república virtualmente independiente sin poner en cuestión (formalmente) las fronteras reconocidas (modelo “Transnistria”).
- c) Tan solo unos días antes, hacia el 25-26 de febrero, la hipótesis más probable era aún que los rusos estuvieran intentando impedir que el nuevo gobierno de Kiev tomara el control efectivo de Crimea (probabilidad del 63-68%).
Con la tabla, podemos fácilmente excluir como sospechoso de desinformación un suceso que hemos aceptado previamente, modificar la verosimilitud de sucesos pasados a la luz de nueva evidencia, o cambiar las probabilidades previas de las que hemos partido. En todos estos casos, la tabla nos recalcula automáticamente todas las probabilidades.
Bayes ingenuo y Análisis de Hipótesis Alternativas (ACH)
En el fondo, la técnica de Bayes ingenuo no es muy diferente del Análisis de Hipótesis Alternativas (ACH) de Heuers. La lógica subyacente es la misma (conocer una realidad oculta gracias al estudio de sus manifestaciones visibles) y la diferencia principal radica en la forma de atacar el problema: mientras Bayes ingenuo calcula las probabilidades relativas, ACH intenta descartar hipótesis por ser inconsistentes con la evidencia.
Para ilustrar mejor las diferencias entre estas dos técnicas, hemos elaborado una matriz (prueba ach_crimea.xlsx[10]) con los sucesos y las hipótesis del ejemplo sobre Crimea. Como sabemos, las diversas variantes de ACH se diferencian entre sí por la manera de contabilizar los resultados. En nuestro caso, marcaremos CC y contaremos 2 puntos cuando el suceso sea altamente consistente con la hipótesis, C (1 punto) cuando sea consistente, I (-1) cuando sea inconsistente y X (rechazo de la hipótesis) cuando sea incompatible. Con estas reglas, hemos llegado a los resultados que a continuación se indican:
a) La hipótesis de la Anexión parece la más probable, aunque seguimos atribuyendo una probabilidad considerable a la hipótesis del Caos. Las dos primeras hipótesis (Evitar el control de Kiev sobre la península y el modelo Transnistria) podrían ser descartadas.
b) Si elimináramos la última fila, es decir, si no tomáramos en consideración el suceso del 6 de marzo, las cuatro hipótesis seguirían siendo verosímiles, con dos de ellas (Anexión y Transnistria) vistas como claramente más probables.
Vemos, pues, que partiendo de una lógica similar, las dos técnicas nos conducen a resultados ligeramente distintos. Y en el proceso podemos apreciar algunos de los inconvenientes que cada una de ellas tiene:
a) En ACH el principal problema es que no siempre resulta fácil encontrar sucesos que desmientan alguna de las hipótesis (“coartadas”) por ser completamente incompatibles con ella. Y, en ocasiones, sucesos muy interesantes pueden ser sospechosos de desinformación.
b) En ausencia de “coartadas”, la puntuación en ACH depende mucho de la metodología de cálculo que se siga. La que hemos elegido es, quizá, excesivamente simple. Otras más complejas pueden resultar difíciles de aplicar (aunque hay programas informáticos que pueden servir de ayuda) y resultar en cierta medida arbitrarias.
c) El problema con Bayes ingenuo es que para muchos analistas no resulta intuitivo. El uso de la hoja Excel ayuda mucho a realizar los cálculos, pero puede oscurecer la lógica que hay detrás de ellos.
A modo de conclusión
a) El Teorema de Bayes no sirve para predecir el futuro, sino que nos ayuda a conocer una realidad pasada o presente que permanece oculta a nuestros ojos. Es obvio que si el Presidente del país X ha decidido invadir el país vecino Y, acabará haciéndolo, de no mediar alguna circunstancia que le haga cambiar de opinión. Pero lo que averiguamos no es el hecho futuro (que invadirá), sino el pasado (que ha tomado la decisión de hacerlo).
b) Bayes ingenuo (como también ACH) es más efectivo cuando se usa para estudiar una situación estable, cuando la evidencia se puede recolectar durante un período de tiempo suficientemente largo sin que la “incógnita” que intentamos resolver cambie apreciablemente. Porque cuando la “incógnita” cambia con relativa rapidez, como suele ser el caso durante las crisis actuales, diferentes observaciones realizadas en momentos distintos pueden ser producto de una “realidad oculta” que se ha modificado, que ya no es la misma. Por eso, si queremos que Bayes ingenuo funcione razonablemente bien con situaciones dinámicas, la recogida de datos debe realizarse en plazos de tiempo relativamente cortos. O debemos descartar los “sucesos” más antiguos, que pueden responder a una “realidad oculta” que ya no es real.
c) Más importante que las dos técnicas que hemos examinado en este post es la “lógica bayesiana” que subyace a ambas. En inteligencia (sobre todo, en inteligencia estratégica) es raro conseguir evidencias directas sobre la realidad que nos interesa. Esa realidad siempre permanece oculta a nuestros ojos y lo que podemos averiguar sobre ella es gracias a sus manifestaciones visibles.
d) Quien quiera ocultar una información valiosa no solo intentará protegerla de intentos directos de acceder a ella, sino que tendrá también en cuenta esas manifestaciones visibles, tan difíciles de ocultar. Y lo hará utilizando desinformación. Este es el principal problema para utilizar Bayes ingenuo (o ACH): distinguir la información correcta de la inexacta y de la desinformacón.
Y es que no resulta nada fácil ser un analista inteligente.
[1] SOMIEDO, J.P. (2018). El análisis bayesiano como piedra angular de la inteligencia de alertas estratégicas. Revista de Estudios en Seguridad Internacional, 4, 1: 161-176. DOI: http://dx.doi.org/10.18847/1.7.10. Para una lista de las interesantes aportaciones de Somiedo al estudio de la metodología del análisis de inteligencia, ver https://dialnet.unirioja.es/servlet/autor?codigo=3971893.
[2] Para una explicación rápida del teorema de Bayes, véase https://es.wikipedia.org/wiki/Teorema_de_Bayes.
[3] Puede verse, por ejemplo, FISK, C.F. (1967). The Sino-Soviet Border Dispute: A Comparison of the Conventional and Bayesian Methods for Intelligence Warning. CIA Center for the Study of Intelligence. https://www.cia.gov/library/center-for-the-study-of-intelligence/kent-csi/vol16no2/html/v16i2a04p_0001.htm (acceso: 08.062020).
[4] Los no familiarizados con las redes bayesianas pueden encontrar una introducción elemental de este concepto en https://es.wikipedia.org/wiki/Red_bayesiana.
[5] Ver STICHA, P., BUEDE, D. & REES, R.L. (2005). APOLLO: An analytical tool for predicting a subject’s decision making. En Proceedings of the 2005 International Conference on Intelligence Analysis. https://cse.sc.edu/~mgv/BNSeminar/ApolloIA05.pdf (acceso: 08.06.2020).
[6] Los que conozcan el histórico concurso de televisión Un, dos, tres, responda otra vez recordarán que una táctica muy eficaz para responder consistía en repetir un “objeto”, alterando alguna de sus características. Por ejemplo, si pedían “muebles que puedan estar en un comedor”, ir diciendo sucesivamente “silla blanca”, “silla negra”, “silla roja”, etc. Esta táctica aplicada a la técnica de “Bayes ingenuo” nos acabaría conduciendo inexorablemente a una hipótesis predeterminada. Claro que sería como hacernos trampas al solitario…
[7] El nombre de la hoja es bayes_excel.xlsx, y puede encontrarse en https://bit.ly/2An58uc.
[8] MCLAUGHLIN, J., & PATÉ-CORNELL, M.E. (2005). A Bayesian approach to Iraq’s nuclear program intelligence analysis: a hypothetical illustration. En 2005 International Conference on Intelligence Analysis. https://analysis.mitre.org/proceedings/Final_Papers_Files/85_Camera_Ready_Paper.pdf (acceso: 27.10.2018). También, MCLAUGHLIN, J. (2005). A Bayesian Updating Model for Intelligence Analysis:A Case Study of Iraq’s Nuclear Weapons Program. Honors Program in International Security Studies Center for International Security and Cooperation Stanford University.
[9] Puede accederse a ella en la siguiente dirección: https://bit.ly/30veoY3.
[10] Puede encontrarse en https://bit.ly/3dUsENL.
Fuente: serviciosdeinteligencia.com, 2020
Algoritmos Naive Bayes: Fundamentos e Implementación
¡Conviértete en un maestro de uno de los algoritmos mas usados en clasificación!
Por Víctor Román.
Victor RomanFollowApr 25, 2019 · 13 min read

Introducción: ¿Qué son los modelos Naive Bayes?
En un sentido amplio, los modelos de Naive Bayes son una clase especial de algoritmos de clasificación de Aprendizaje Automatico, o Machine Learning, tal y como nos referiremos de ahora en adelante. Se basan en una técnica de clasificación estadística llamada “teorema de Bayes”.
Estos modelos son llamados algoritmos “Naive”, o “Inocentes” en español. En ellos se asume que las variables predictoras son independientes entre sí. En otras palabras, que la presencia de una cierta característica en un conjunto de datos no está en absoluto relacionada con la presencia de cualquier otra característica.
Proporcionan una manera fácil de construir modelos con un comportamiento muy bueno debido a su simplicidad.
Lo consiguen proporcionando una forma de calcular la probabilidad ‘posterior’ de que ocurra un cierto evento A, dadas algunas probabilidades de eventos ‘anteriores’.

Ejemplo
Presentaremos los conceptos principales del algoritmo Naive Bayes estudiando un ejemplo.
Consideremos el caso de dos compañeros que trabajan en la misma oficina: Alicia y Bruno. Sabemos que:
- Alicia viene a la oficina 3 días a la semana.
- Bruno viene a la oficina 1 día a la semana.
Esta sería nuestra información “anterior”.
Estamos en la oficina y vemos pasar delante de nosotros a alguien muy rápido, tan rápido que no sabemos si es Alicia o Bruno.
Dada la información que tenemos hasta ahora y asumiendo que solo trabajan 4 días a la semana, las probabilidades de que la persona vista sea Alicia o Bruno, son:
- P(Alicia) = 3/4 = 0.75
- P(Bruno) = 1/4 = 0.25
Cuando vimos a la persona pasar, vimos que él o ella llevaba una chaqueta roja. También sabemos lo siguiente:
- Alicia viste de rojo 2 veces a la semana.
- Bruno viste de rojo 3 veces a la semana.
Así que, para cada semana de trabajo, que tiene cinco días, podemos inferir lo siguiente:
- La probabilidad de que Alicia vista de rojo es → P(Rojo|Alicia) = 2/5 = 0.4
- La probabilidad de que Bruno vista de rojo → P(Rojo|Bruno) = 3/5 = 0.6
Entonces, con esta información, ¿a quién vimos pasar? (en forma de probabilidad)
Esta nueva probabilidad será la información ‘posterior’.

Inicialmente conocíamos las probabilidades P(Alicia) y P(Bruno), y después inferíamos las probabilidades de P(rojo|Alicia) y P(rojo|Bruno).
De forma que las probabilidades reales son:

Formalmente, el gráfico previo sería:

Algoritmo Naive Bayes Supervisado
A continuación se listan los pasos que hay que realizar para poder utilizar el algoritmo Naive Bayes en problemas de clasificación como el mostrado en el apartado anterior.
- Convertir el conjunto de datos en una tabla de frecuencias.
- Crear una tabla de probabilidad calculando las correspondientes a que ocurran los diversos eventos.
- La ecuación Naive Bayes se usa para calcular la probabilidad posterior de cada clase.
- La clase con la probabilidad posterior más alta es el resultado de la predicción.
Puntos fuertes y débiles de Naive Bayes
Los puntos fuertes principales son:
- Un manera fácil y rápida de predecir clases, para problemas de clasificación binarios y multiclase.
- En los casos en que sea apropiada una presunción de independencia, el algoritmo se comporta mejor que otros modelos de clasificación, incluso con menos datos de entrenamiento.
- El desacoplamiento de las distribuciones de características condicionales de clase significan que cada distribución puede ser estimada independientemente como si tuviera una sola dimensión. Esto ayuda con problemas derivados de la dimensionalidad y mejora el rendimiento.
Los puntos débiles principales son:
- Aunque son unos clasificadores bastante buenos, los algoritmos Naive Bayes son conocidos por ser pobres estimadores. Por ello, no se deben tomar muy en serio las probabilidades que se obtienen.
- La presunción de independencia Naive muy probablemente no reflejará cómo son los datos en el mundo real.
- Cuando el conjunto de datos de prueba tiene una característica que no ha sido observada en el conjunto de entrenamiento, el modelo le asignará una probabilidad de cero y será inútil realizar predicciones. Uno de los principales métodos para evitar esto, es la técnica de suavizado, siendo la estimación de Laplace una de las más populares.
Proyecto de Implementación: Detector de Spam
Actualmente, una de las aplicaciones principales de Machine Learning es la detección de spam. Casi todos los servicios de email más importantes proporcionan un detector de spam que clasifica el spam automáticamente y lo envía al buzón de “correo no deseado”.
En este proyecto, desarrollaremos un modelo Naive Bayes que clasifica los mensajes SMS como spam o no spam (‘ham’ en el proyecto). Se basará en datos de entrenamiento que le proporcionaremos.
Haciendo una investigación previa, encontramos que, normalmente, en los mensajes de spam se cumple lo siguiente:
- Contienen palabras como: ‘gratis’, ‘gana’, ‘ganador’, ‘dinero’ y ‘premio’.
- Tienden a contener palabras escritas con todas las letras mayúsculas y tienden al uso de muchos signos de exclamación.
Esto es un problema de clasificación binaria supervisada, ya que los mensajes son o ‘Spam’ o ‘No spam’ y alimentaremos un conjunto de datos etiquetado para entrenar el modelo.
Visión general
Realizaremos los siguientes pasos:
- Entender el conjunto de datos
- Procesar los datos
- Introducción al “Bag of Words” (BoW) y la implementación en la libreria Sci-kit Learn
- División del conjunto de datos (Dataset) en los grupos de entrenamiento y pruebas
- Aplicar “Bag of Words” (BoW) para procesar nuestro conjunto de datos
- Implementación de Naive Bayes con Sci-kit Learn
- Evaluación del modelo
- Conclusión
Entender el Conjunto de Datos
Utilizaremos un conjunto de datos del repositorio UCI Machine Learning.
Un primer vistazo a los datos:

Las columnas no se han nombrado, pero como podemos imaginar al leerlas:
- La primera columna determina la clase del mensaje, o ‘spam’ o ‘ham’ (no spam).
- La segunda columna corresponde al contenido del mensaje
Primero importaremos el conjunto de datos y cambiaremos los nombre de las columnas. Haciendo una exploración previa, también vemos que el conjunto de datos está separado. El separador es ‘\t’.
# Importar la libreria Pandas
import pandas as pd# Dataset de https://archive.ics.uci.edu/ml/datasets/SMS+Spam+Collection
df = pd.read_table('smsspamcollection/SMSSpamCollection',
sep='\t',
names=['label','sms_message'])# Visualización de las 5 primeras filas
df.head()
Preprocesamiento de Datos
Ahora, ya que el Sci-kit learn solo maneja valores numéricos como entradas, convertiremos las etiquetas en variables binarias, 0 representará ‘ham’ y 1 representará ‘spam’.
Para representar la conversión:
# Conversion
df['label'] = df.label.map({'ham':0, 'spam':1})# Visualizar las dimensiones de los datos
df.shape()

Introducción a la Implementación “Bag of Words” (BoW) y Sci-kit Learn
Nuestro conjunto de datos es una gran colección de datos en forma de texto (5572 filas). Como nuestro modelos solo aceptará datos numéricos como entrada, deberíamos procesar mensajes de texto. Aquí es donde “Bag of Words“ entra en juego.
“Bag of Words” es un término usado para especificar los problemas que tiene una colección de datos de texto que necesita ser procesada. La idea es tomar un fragmento de texto y contar la frecuencia de las palabras en el mismo.
BoW trata cada palabra independientemente y el orden es irrelevante.
Podemos convertir un conjunto de documentos en una matriz, siendo cada documento una fila y cada palabra (token) una columna, y los valores correspondientes (fila, columna) son la frecuencia de ocurrencia de cada palabra (token) en el documento.
Como ejemplo, si tenemos los siguientes cuatro documentos:
['Hello, how are you!', 'Win money, win from home.', 'Call me now', 'Hello, Call you tomorrow?']
Convertiremos el texto a una matriz de frecuencia de distribución como la siguiente:

Los documentos se numeran en filas, y cada palabra es un nombre de columna, siendo el valor correspondiente la frecuencia de la palabra en el documento.
Usaremos el método contador de vectorización de Sci-kit Learn, que funciona de la siguiente manera:
- Fragmenta y valora la cadena (separa la cadena en palabras individuales) y asigna un ID entero a cada fragmento (palabra).
- Cuenta la ocurrencia de cada uno de los fragmentos (palabras) valorados.
- Automáticamente convierte todas las palabras valoradas en minúsculas para no tratar de forma diferente palabras como “el” y “El”.
- También ignora los signos de puntuación para no tratar de forma distinta palabras seguidas de un signo de puntuación de aquellas que no lo poseen (por ejemplo “¡hola!” y “hola”).
- El tercer parámetro a tener en cuenta es el parámetro
stop_words. Este parámetro se refiere a las palabra más comúnmente usadas en el lenguaje. Incluye palabras como “el”, “uno”, “y”, “soy”, etc. Estableciendo el valor de este parámetro por ejemplo enenglish, “CountVectorizer” automáticamente ignorará todas las palabras (de nuestro texto de entrada) que se encuentran en la lista de “stop words” de idioma inglés..
La implementación en Sci-kit Learn sería la siguiente:
# Definir los documentos
documents = ['Hello, how are you!',
'Win money, win from home.',
'Call me now.',
'Hello, Call hello you tomorrow?']# Importar el contador de vectorizacion e inicializarlo
from sklearn.feature_extraction.text import CountVectorizer
count_vector = CountVectorizer()# Visualizar del objeto'count_vector' que es una instancia de 'CountVectorizer()'
print(count_vector)

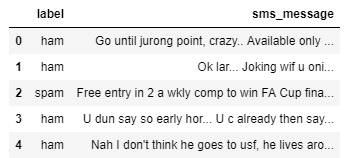
Para ajustar el conjunto de datos del documento al objeto “CountVectorizer” creado, usaremos el método “fit()”, y conseguiremos la lista de palabras que han sido clasificadas como características usando el método “get_feature_names()”. Este método devuelve nuestros nombres de características para este conjunto de datos, que es el conjunto de palabras que componen nuestro vocabulario para “documentos”.
count_vector.fit(documents)
names = count_vector.get_feature_names()
names
A continuación, queremos crear una matriz cuyas filas serán una de cada cuatro documentos, y las columnas serán cada palabra. El valor correspondiente (fila, columna) será la frecuencia de ocurrencia de esa palabra (en la columna) en un documento particular (en la fila).
Podemos hacer esto usando el método “transform()” y pasando como argumento en el conjunto de datos del documento. El método “transform()” devuelve una matriz de enteros, que se puede convertir en tabla de datos usando “toarray()”.
doc_array = count_vector.transform(documents).toarray()
doc_array

Para hacerlo fácil de entender, nuestro paso siguiente es convertir esta tabla en una estructura de datos y nombrar las columnas adecuadamente.
frequency_matrix = pd.DataFrame(data=doc_array, columns=names)
frequency_matrix

Con esto, hemos implementado con éxito un problema de “BoW” o Bag of Words para un conjunto de datos de documentos que hemos creado.
Un problema potencial que puede surgir al usar este método es el hecho de que si nuestro conjunto de datos de texto es extremadamente grande, habrá ciertos valores que son más comunes que otros simplemente debido a la estructura del propio idioma. Así, por ejemplo, palabras como ‘es’, ‘el’, ‘a’, pronombres, construcciones gramaticales, etc. podrían sesgar nuestra matriz y afectar nuestro análisis.
Para mitigar esto, usaremos el parámetro stop_words de la clase CountVectorizer y estableceremos su valor en inglés.
Dividiendo el Conjunto de Datos en Conjuntos de Entrenamiento y Pruebas
Buscamos dividir nuestros datos para que tengan la siguiente forma:
X_trainson nuestros datos de entrenamiento para la columna ‘sms_message’y_trainson nuestros datos de entrenamiento para la columna ‘label’X_testson nuestros datos de prueba para la columna ‘sms_message’y_testson nuestros datos de prueba para la columna ‘label’. Muestra el número de filas que tenemos en nuestros datos de entrenamiento y pruebas
# Dividir los datos en conjunto de entrenamiento y de test
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(df['sms_message'], df['label'], random_state=1)print('Number of rows in the total set: {}'.format(df.shape[0]))print('Number of rows in the training set: {}'.format(X_train.shape[0]))print('Number of rows in the test set: {}'.format(X_test.shape[0]))

Aplicar BoW para Procesar Nuestros Datos de Pruebas
Ahora que hemos dividido los datos, el próximo objetivo es convertir nuestros datos al formato de la matriz buscada. Para realizar esto, utilizaremos CountVectorizer() como hicimos antes. tenemos que considerar dos casos:
- Primero, tenemos que ajustar nuestros datos de entrenamiento (
X_train) enCountVectorizer()y devolver la matriz. - Sgundo, tenemos que transformar nustros datos de pruebas (
X_test) para devolver la matriz.
Hay que tener en cuenta que X_train son los datos de entrenamiento de nuestro modelo para la columna ‘sms_message’ en nuestro conjunto de datos.
X_test son nuestros datos de prueba para la columna ‘sms_message’, y son los datos que utilizaremos (después de transformarlos en una matriz) para realizar predicciones. Compararemos luego esas predicciones con y_test en un paso posterior.
El código para este segmento está dividido en 2 partes. Primero aprendemos un diccionario de vocabulario para los datos de entrenamiento y luego transformamos los datos en una matriz de documentos; segundo, para los datos de prueba, solo transformamos los datos en una matriz de documentos.
# Instantiate the CountVectorizer method
count_vector = CountVectorizer()# Fit the training data and then return the matrix
training_data = count_vector.fit_transform(X_train)# Transform testing data and return the matrix. Note we are not fitting the testing data into the CountVectorizer()
testing_data = count_vector.transform(X_test)
Implementación Naive Bayes con Sci-Kit Learn
Usaremos la implementación Naive Bayes “multinomial”. Este clasificador particular es adecuado para la clasificación de características discretas (como en nuestro caso, contador de palabras para la clasificación de texto), y toma como entrada el contador completo de palabras.
Por otro lado el Naive Bayes gausiano es más adecuado para datos continuos ya que asume que los datos de entrada tienen una distribución de curva de Gauss (normal).
Importaremos el clasificador “MultinomialNB” y ajustaremos los datos de entrenamiento en el clasificador usando fit().
from sklearn.naive_bayes import MultinomialNB
naive_bayes = MultinomialNB()
naive_bayes.fit(training_data, y_train)

Ahora que nuestro algoritmo ha sido entrenado usando el conjunto de datos de entrenamiento, podemos hacer algunas predicciones en los datos de prueba almacenados en ‘testing_data’ usando predict().
predictions = naive_bayes.predict(testing_data)
Una vez realizadas las predicciones el conjunto de pruebas, necesitamos comprobar la exactitud de las mismas.
Evaluación del modelo
Hay varios mecanismos para hacerlo, primero hagamos una breve recapitulación de los criterios y de la matriz de confusión.
- La matriz de confusión es donde se recogen el conjunto de posibilidades entre la clase correcta de un evento, y su predicción.
- Exactitud: mide cómo de a menudo el clasificador realiza la predicción correcta. Es el ratio de número de predicciones correctas contra el número total de predicciones (el número de puntos de datos de prueba).
- Precisión: nos dice la proporción de mensajes que clasificamos como spam. Es el ratio entre positivos “verdaderos” (palabras clasificadas como spam que son realmente spam) y todos los positivos (palabras clasificadas como spam, lo sean realmente o no)
- Recall (sensibilidad): Nos dice la proporción de mensajes que realmente eran spam y que fueron clasificados por nosotros como spam. Es el ratio de positivos “verdaderos” (palabras clasificadas como spam, que son realmente spam) y todas las palabras que fueron realmente spam.
Para los problemas de clasificación que están sesgados en sus distribuciones de clasificación como en nuestro caso. Por ejemplo si tuviéramos 100 mensajes de texto y solo 2 fueron spam y los restantes 98 no lo fueron, la exactitud por si misma no es una buena métrica. Podríamos clasificar 90 mensajes como no spam (incluyendo los 2 que eran spam y los clasificamos como “no spam”, y por tanto falsos negativos) y 10 como spam (los 10 falsos positivos) y todavía conseguir una puntuación de exactitud razonablemente buena.
Para casos como este, la precisión y el recuerdo son bastante adecuados. Estas dos métricas pueden ser combinadas para conseguir la puntuación F1, que es el “peso” medio de las puntuaciones de precisión y recuerdo. Esta puntuación puede ir en el rango de 0 a 1, siendo 1 la mejor puntuación posible F1.
Usaremos las cuatro métricas para estar seguros de que nuestro modelo se comporta correctamente. Para todas estas métricas cuyo rango es de 0 a 1, tener una puntuación lo más cercana posible a 1 es un buen indicador de cómo de bien se está comportando el modelo.
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_scoreprint('Accuracy score: ', format(accuracy_score(y_test, predictions)))print('Precision score: ', format(precision_score(y_test, predictions)))print('Recall score: ', format(recall_score(y_test, predictions)))print('F1 score: ', format(f1_score(y_test, predictions)))

Conclusión
- Una de las mayores ventajas que Naive Bayes tiene sobre otros algoritmos de clasificación es la capacidad de manejo de un número extremadamente grande de características. En nuestro caso, cada palabra es tratada como una característica y hay miles de palabras diferentes.
- También, se comporta bien incluso ante la presencia de características irrelevantes y no es relativamente afectado por ellos.
- La otra ventaja principal es su relativa simplicidad. Naive Bayes funciona bien desde el principio y ajustar sus parámetros es raramente necesario.
- Raramente sobreajusta los datos.
- Otra ventaja importante es que su modelo de entrenamiento y procesos de predicción son muy rápidos teniendo en cuenta la cantidad de datos que puede manejar.
Fuente: medium.com, 2019

Vincúlese a nuestras Redes Sociales:
LinkedIn YouTube Facebook Twitter

.
.
Para saber más sobre Big Data
mayo 9, 2020
Big Data. Conceptos, tecnologías y aplicaciones

El libro que tengo en las manos es una excelente aportación para el conocimiento del público en general del gran paradigma que conmueve los cimientos de nuestro mundo, el Big Data. Se trata de Big Data. Conceptos, tecnologías y aplicaciones, en la colección Qué sabemos de, escrito por dos expertos, David Ríos Insúa y David Gómez Ullate.
Comentaremos brevemente el contenido de este libro, aunque en entradas sucesivas seguiremos hablando de algunos de los temas que, al menos a mí, me han resultado tan interesantes como para querer saber más sobre ellos.
Una de las cuestiones más preocupantes del big data es que una gran parte de ese tsunami de datos lo estamos proporcionando nosotros mismos de manera gratuita y casi sin darnos cuenta, como si no nos importara. Y con esos datos, hay compañías que hacen negocios. Google recibe 4 millones de peticiones por minuto, en Facebook compartimos 2 millones y medio de piezas por minuto, cada día enviamos 400 millones de tuits.

La importancia de los datos y su análisis tiene un origen comercial, como conocer mejor a los clientes, sus gustos, como llegar mejor a ellos. Y si antiguamente (por ejemplo, Gallup) había que hacer encuestas, los avances tecnológicos (internet, móviles, GPS, …) han facilitado la tarea. Se dice que hay unos 15.000 millones de sensores distribuidos en el mundo, y no paran,
Pero estos datos se dan en bruto, tenemos que pulirlos y almacernarlos para poder usarlos. Y después tenemos que aplicar diferentes tecnologías para extraer información útil de los mismos. Y ahí es donde entran las matemáticas. Los autores muestran como una de las bases claves es la Estadística. El otro pilar es la Infomática. A lo largo del libro describen ampliamente como estas dos disciplinas interactúan en el Big Data. Y ello les lleva a hablar del aprendizaje automático (machine learning), redes neuronales, inteligencia artificial, ciberseguridad, y muchos otros temas.
Es muy relevante como las administraciones públicas están tan lejos de las grandes corporaciones empresariales y no están utilizando estas nuevas herramientas en beneficio de la sociedad; hay un enorme potencial en su uso, por ejemplo, en la medicina, tal y como detallan en uno de sus capítulos.
Aunque a veces la lectura nos produce el temor al Gran Hermano, los aspectos positivos son muchos, como ocurre casi siempre con la ciencia. El Big Data no es la panacea a todos los problemas de este mundo pero si que nos ofrece un gran cantidad de oportunidades. Enhorabuena a los autores por este magnífico libro que en apenas 134 páginas no nos da respiro.

{kind=link}
David Ríos Insúa. Es AXA-ICMAT Chair en Análisis de Riesgos Adversarios en el ICMAT-CSIC y numerario de la Real Academia de Ciencias Exactas, Físicas y Naturales. Es catedrático de Estadística e Investigación Operativa (en excedencia). Previamente ha sido profesor o investigador en Manchester, Leeds, Duke, Purdue, Paris-Dauphine, Aalto, CNR-IMATI, IIASA, SAMSI y UPM. Entre otros, ha recibido el Premio DeGroot de la ISBA por su libro Adversarial Risk Analysis. Es asesor científico de Aisoy Robotics. Ha escrito más de 130 artículos con revisión y 15 monografías sobre sus temas de interés que incluyen la inferencia bayesiana, la ciencia de datos, el análisis de decisiones y el análisis de riesgos, y sus aplicaciones, principalmente, a seguridad y ciberseguridad.
{kind=link}
David Gómez-Ullate Oteiza. Es investigador en la Universidad de Cádiz y profesor titular de Matemática Aplicada en la Universidad Complutense de Madrid. Su labor reciente se centra en la transferencia de conocimiento al sector industrial en ciencia de datos e inteligencia artificial. Dirige proyectos en el sector aeronáutico, seguros y biomédico aplicando técnicas de visión artificial y procesamiento de lenguaje natural.
___
Manuel de León (CSIC, Fundador del ICMAT, Real Academia de Ciencias, Real Academia Canaria de Ciencias, Real Academia Galega de Ciencias).
Fuente: madrimasd.org, 2020.
Vincúlese a nuestras Redes Sociales:
LinkedIn YouTube Facebook Twitter

.
.
¿Hacia dónde va la Inteligencia de Negocios?
mayo 1, 2020
Cinco tendencias que están marcando la evolución de la Analítica y el Business Intelligence
Las empresas que atraviesan un proceso de transformación digital adoptan en prácticamente todos los casos nuevas tecnologías que las ayudan a avanzar y agilizar procesos. Entre ellas hay en muchos casos una o varias ramas de la Inteligencia Artificial. Como la Analítica o el Business Intelligence, dos piezas de gran importancia para que las empresas consigan extraer información útil y valiosa de los datos que manejan y puedan aplicarla en sus procesos. Tanto, que según Gartner, muchos directivos y empresas centradas en lo digital han convertido a ambas tecnologías en dos de sus principales prioridades de inversión.
Estas dos tecnologías, al igual que el resto de ramas de la Inteligencia Artificial, avanzan de manera constante, para lo que se apoyan en diversas tendencias que dan forma a su evolución. De ellas, las cinco más punteras en la actualidad son las siguientes:
1 – Analítica aumentada
La analítica aumentada emplea el machine learning para automatizar la preparación de datos, el descubrimiento de información, la ciencia de datos, el desarrollo de modelos de machine learning y la compartición de información para un amplio rango de usuarios profesionales, trabajadores y científicos de datos «civiles».
A medida que vaya madurando, la analítica aumentada se convertirá en una función clave de las plataformas de analítica moderna. Proporcionará análisis a cualquier miembro de una empresa en menos tiempo, y también con menos requisitos para los usuarios con experiencia, y con menos sesgo interpretativo que los enfoques manuales actuales.

2 – Cultura digital
El desarrollo de una cultura digital eficaz puede ser el primer y más importante paso en una empresa de cara a abordar sus procesos de transformación digital. Cualquier organización que intenta obtener valor de sus datos y está en pleno proceso de transformación digital debe centrarse en el desarrollo de una formación en datos. Según los analistas de Gartner, la formación de datos tendrá impacto en todos los empleados, ya que se convertirá no solo en una habilidad de empresa, sino en una que será crítica para la vida.
En relación con esto, la preocupación por el peso cada vez mayor de la Inteligencia Artificial y la sociedad digital, pero también de las fake news, tanto las organizaciones como los gobiernos están interesándose cada vez más por la ética digital.
Los líderes en datos y analítica deberían patrocinar debates sobre ética digital para asegurarse de que la información y la tecnología se usan de manera ética para conseguir y mantener la confianza de empleados, clientes y socios. Y parece que, según Gartner, es cada vez más importante. Así, según sus datos, para 2023, el 60% de organizaciones con más de 20 científicos de datos necesitarán un código de conducta profesional que incorpore un uso ético de los datos y la analítica.
3 – Analítica de las relaciones
La emergencia de la analítica de relaciones pone de manifiesto el uso creciente de los grafos, la ubicación y las técnicas de analítica social, con el objetivo de comprender cómo están conectadas las distintas entidades de interés, como la gente, los lugares y las cosas.
El análisis de datos desestructurados y cambiantes puede proporcionar a los usuarios información y contexto en una red, y datos más exhaustivos que mejoren la precisión de las predicciones y la toma de decisiones.
4 – Inteligencia de decisión
Los líderes en datos y analítica trabajan con grandes cantidades de datos de ecosistemas que están en evolución constante. Por lo tanto necesitan utilizar una multitud de técnicas para gestionar los datos de forma eficaz.
Lo impredecible de los modelos de decisión actuales viene a menudo de una incapacidad para capturar de manera adecuada o tener en cuenta ciertos factores de incertidumbre relacionada con el comportamiento de modelos en un contexto de empresa. La inteligencia de decisión proporciona un framework que aúna técnicas tradicionales y avanzadas para diseñar, modelar, alinear, ejecutar, controlar y afinar modelos de decisión.
5 – Operatividad y escalado
La cantidad de casos de uso en el núcleo de una empresa, en sus áreas relacionadas y más allá es ingente. Cada vez más más gente que quiere interactuar con los datos, y cada vez más interacciones y procesos necesitan analítica para la automatización y el escalado.
Los servicios de analítica y los algoritmos se activan cada vez con más frecuencia cuándo y donde se necesitan. Ya sea para justificar el siguiente gran paso estratégico o para optimizar millones de transacciones, las herramientas de analítica y los datos que las alimentan están en espacios en los que hasta ahora era raro encontrarlos.
Fuente: muycomputerpro.com, 2019
___________________________________________________________________
Analítica de grafos: El valor de las relaciones
Con los avances en Big Data y Machine Learning en los últimos años, el análisis y modelado de datos se está convirtiendo en algo cada vez más importante, convirtiendo el rol de Data Scientist en un perfil cada vez más relevante y solicitado.
Pero, ¿qué tiene que ver esto con la analítica de grafos?
Los grafos son una estructura de datos que aporta mucho valor tanto en áreas científicas y de investigación (biología, sociología, etc), como en áreas de negocio (estudios de mercado, detección de fraude, etc), permitiendo modelar la información visualmente de una forma mucho más “real”.

Por esta razón, la analítica de grafos se ha convertido en una habilidad más que todo analista de datos debería aprender.
¿Cómo realizar un análisis?
Aunque visualmente un grafo pequeño es fácil de entender, la volumetría de los datos y la complejidad de las propiedades y de las relaciones puede dificultar mucho su interpretación. Por esta razón, es importante definir qué es lo que se quiere medir o analizar y utilizar la metodología y los algoritmos correctos para obtener conclusiones.
Dentro de la teoría de grafos, en función de lo que se pretenda obtener, se pueden realizar los siguientes tipos de análisis:
- Path analysis: analiza las características de las rutas entre dos nodos, por ejemplo, para conocer la distancia mínima que hay entre ellos. Existen muchos casos de uso dónde este análisis es muy útil, uno de los más comunes sería utilizarlo para conocer los pasos que ha realizado un usuario desde que accede a una web hasta que compra un producto, pero también se utiliza para temas más complejos, como analizar patrones de comportamiento que llevan a una persona a cometer un fraude.
- Connectivity analysis: se utiliza para comprobar la “fuerza” de las relaciones, permitiendo detectar relaciones débiles o vulnerables entre dos nodos. Un caso de uso para este tipo de análisis sería detectar cuellos de botella en la comunicación dentro de una red de ordenadores.
- Community analysis: este método de análisis se basa en la distancia y densidad del grafo para detectar comunidades de nodos, de forma que cada comunidad contenga nodos con características comunes o similares.

- Centrality analysis: permite conocer la relevancia que tienen los nodos dentro del grafo, es decir, analiza la influencia que tiene un nodo. El ejemplo más común sería detectar las páginas web más visitadas, sin embargo, tiene usos más atractivos como detectar las personas más influyentes en las redes sociales.
La centralidad dentro de un grafo se puede calcular en función de distintas medidas. La siguiente imagen muestra los resultados de centralidad utilizando diferentes medidas sobre el mismo grafo:


- Subgraph isomorphism: analiza el grafo para obtener patrones estructurales dentro del mismo, permitiendo averiguar qué patrones son los más repetidos. La detección de patrones es un método muy utilizado para la detección de fraude.
- Graph Embedding: se trata de una técnica que permite interpretar los nodos como vectores y así poder entrenar y ejecutar modelos predictivos de Machine Learning sobre el grafo. Por lo general, el uso de modelos ML sobre grafos es complicado debido a la forma en la que están estructurados los datos, sin embargo, técnicas como Graph Embedding facilitan su uso al transformar las estructuras de nodos en vectores.
La analítica de grafos es una rama dentro del análisis de datos que permite visualizar la información de forma más clara, y que se está utilizando en numerosas disciplinas, como detección de fraude, marketing, investigación, etc. a fin de revelar rasgos y tendencias ocultos en los datos. Por esta razón, se está convirtiendo en una habilidad muy cotizada en personas con perfil de analista.
La analítica de grafos basada en proyectos Big Data y complementada con tecnología como Machine Learning y Deep Learning proporciona a los analistas un mapa del comportamiento facilitando y simplificando los procesos de investigación.
___________________________________________________________________
Luchando contra el fraude: “El roadmap de la detección”

Hace unas semanas tuve la oportunidad de participar como ponente en el “III Foro Anual de Gestión de Siniestros y Fraude” organizado por INESE en la que pude explicar cómo la analítica de grafos puede ayudar en la detección de fraude aportando nuevas perspectivas de análisis. Veremos cómo las compañías aseguradoras pueden emprender el “roadmap de la detección” desde la tramitación manual a la analítica de grafos pasando por la implementación de algoritmos de Machine Learning. Estas son las fases del “Roadmap de la detección”:
Matrices de fraude o automatización de reglas de negocio
La mayor parte de las compañías disponen de una identificación clara de las reglas de negocio que determinan el riesgo de un determinado siniestro en función de la experiencia de negocio adquirida en los últimos años.
De esta forma, las compañías determinan el riesgo de un siniestro en base a las condiciones establecidas en el producto contratado (periodos de carencia, exclusiones, etc…) o bien, en función de la experiencia ganada con siniestros sospechosos en el pasado, identificando una serie de reglas que permiten obtener un indicador de riesgo en base al cumplimiento de dichas reglas.
Algunas compañías han pasado de la identificación de las reglas de negocio o matriz de fraude, a una automatización de la misma basada en productos de mercado o bien, en una implementación ad-hoc para sus sistemas de tramitación de siniestros.
- La automatización de la matriz de fraude aporta una serie de ventajas:
- Permite que el modo de tramitación de todo el departamento se base en las mismas reglas evitando la interpretación subjetiva de las reglas.
- Evita el pago de siniestros que no cumplen con las condiciones del producto o sus exclusiones de un modo automático.
- Aporta un nivel de riesgo de fraude a aquellos siniestros que cumplen con unas características que han sido determinadas en base a la experiencia de la compañía o a la experiencia global del sector.
Las matrices de fraude son un elemento altamente eficaz, de hecho la mayor parte de las compañías dispone de mecanismos de automatización de las mismas. Sin embargo, el volumen de información que disponen las compañías está creciendo exponencialmente y por lo tanto deberíamos ser capaces de responder a la siguiente pregunta: ¿Existen otros datos distintos a los tratados en la matriz que pueden determinar el riesgo de un siniestro? Para poder responder a esta pregunta, necesitamos entrar en el siguiente paso del roadmap (hoja de ruta):
Machine Learning
Si bien las técnicas de machine learning existen de manera previa a la irrupción del Big Data, es cierto que esta nueva tendencia permite que estas técnicas sean más eficaces gracias a la capacidad que disponemos para usar la totalidad de los datos para el entrenamiento de los modelos en lugar de muestreos más pequeños.
Teniendo en cuenta esta premisa, es fácil imaginar oportunidades de mejora en la automatización de la matriz de fraude si además de contar con la información proveniente de los sistemas de tramitación, pudiéramos mezclar esa información con la información que proviene de los centros de atención al usuario, correos electrónicos, la historia del cliente en la compañía y otros elementos.
Disponer de la capacidad de mezclar toda esta información aporta unas ventajas claras a la hora de determinar el riesgo de fraude de un determinado siniestro, sin embargo, hay que tener en cuenta multitud de aspectos esenciales para tener éxito en este tipo de aproximaciones:
- ¿Dispongo de la suficiente calidad en la información de mis sistemas?
- ¿Puedo mejorar dicha calidad de un modo automatizado?
- ¿Cómo puedo acceder a la información de todos los sistemas sin alterar su rutina de funcionamiento?
- ¿Cómo seleccionamos las variables más relevantes?
- ¿Cómo se aborda un proyecto de Machine Learning?
- ¿Cómo reduzco el número de falsos positivos?
Aunque intentaré responder a estas preguntas en posteriores artículos, lo que podemos determinar es que la aplicación de las técnicas de Machine Learning aportan de nuevo una serie de ventajas adicionales:
- Aumenta el rango de búsqueda de los siniestros con riesgo de fraude: La selección de nuevas variables puede determinar nuevos condicionantes hasta ahora desconocidos.
- Automatiza la identificación del riesgo a partir de la aplicación de estos modelos.
- Aporta un nuevo indicador de fraude en base a la predicción del riesgo a través de dichos modelos.
- Permite la no repetición de fraude que hayamos detectado en el pasado.
- Puede reducir el número de falsos positivos de las matrices de fraude.
Esta serie de ventajas pueden aportar una gran diferencia con respecto a la automatización de la matriz de fraude y suponen un gran retorno de inversión para aquellas compañías aseguradoras que invierten en el desarrollo de estos sistemas de detección.
Hasta este momento de la “Hoja de Ruta de la detección” hemos conseguido minimizar el riesgo de reaparición de fraudes para los que tenemos indicios en el histórico de la compañía, sin embargo, ¿Podemos acercarnos un paso adicional en la detección del fraude que nunca hemos detectado en la compañía o que no tenemos consciencia de él? Las siguientes etapas nos permiten acercarnos a la resolución de esta pregunta.
Enriquecimiento de la información
Uno de los aspectos fundamentales para encontrar nuevos indicios de riesgo de fraude es disponer de otros elementos de información distintos a los que disponemos en nuestras organizaciones que puedan enriquecer la información que disponemos de nuestros clientes o del propio siniestro, para ello existen varias catalogaciones de las fuentes de información:
Redes Sociales e Internet: La sociedad ha cambiado de manera radical en los últimos años hacia la digitalización. El uso de redes sociales y blogs, entre otros es una constante en casi todos los rangos de edad poblacionales, lo que supone una gran oportunidad para las compañías si son capaces de recoger parte de esa información para enriquecer sus propios datos.
Fuentes públicas: En los últimos años se han desarrollado multitud de fuentes de libre disposición y que permiten enriquecer la información de nuestra compañía con múltiples indicadores como pueden ser valores socio económicos, valores meteorológicos, geopolíticos, etcétera. Estas fuentes de libre disposición vienen determinadas por las corrientes Open Data que se han ido desarrollando en los últimos años por los gobiernos de todo el mundo; de hecho, España es líder europeo en la puesta a disposición de los ciudadanos de multitud de fuentes de información para el desarrollo de diferentes modelos de negocio.
Fuentes privadas: Existen multitud de recursos que pueden adquirirse a través de diferentes asociaciones o empresas para enriquecer la información de nuestros clientes con un posible riesgo crediticio, patrón de comportamiento, etc. Estas fuentes de información permiten a las compañías enriquecer su información a través de acuerdos interempresa.
Si bien la disposición de estas fuentes de información para enriquecer nuestros datos puede ser un elemento diferencial en la detección de fraude, disponer de esta información no está exento de múltiples cuestiones a considerar:
- ¿Es viable disponer de esta información sin vulnerar la LOPD (Ley Orgánica de Protección de Datos de Carácter Personal)?
- ¿Cuál es la fiabilidad de cada una de las fuentes de información?
- ¿Qué trabajo es necesario para normalizar esta información externa e integrarla en los procesos de tramitación de mi compañía?
- ¿Qué beneficio real me aporta la incorporación de esta fuente?
Analítica de grafos
Uno de los enfoques más creativos a la hora de luchar contra el fraude o determinar el riesgo de un determinado cliente u operación, es conseguir analizar la información desde múltiples perspectivas. En este sentido, la Analítica de Grafos nos permite enfocar la detección de fraude desde un punto de vista completamente distinto al habitual, el enfoque de las relaciones.
Como hemos visto en los anteriores puntos, la mayor parte de las técnicas utilizadas consiste en analizar los datos desde el punto de vista del valor de dichos datos, sin embargo, la Analítica de Grafos nos permite modelar la información desde el punto de vista de cómo se interrelaciona la información. Este nuevo enfoque nos permite identificar nuevos indicios de fraude basándonos en cómo nuestros clientes, nuestros siniestros, nuestros datos, se interrelacionan entre sí.
La Analítica de Grafos o SNA (Social Network Analysis) es una técnica que nos permite modelar cualquier realidad en una red formada por nodos y relaciones como podemos ver en la siguiente figura:

Esta aproximación nos permite acelerar los tiempos de investigación de cada caso, basándonos en que los tramitadores o analistas no tienen que imaginarse un mapa mental del siniestro sino que dichas técnicas nos aportan un enfoque completamente visual de la información.
De otro modo, la Analítica de Grafos aplicada a los datos de una compañía aseguradora nos permite conocer el comportamiento de nuestros clientes en cada uno de los siniestros de la compañía y así identificar nuevos indicios como elementos en común entre diferentes siniestros, aparición de redes organizadas de fraude, detección de secuencias temporales o patrones geográficos. Es decir, dado que el fraude lo cometen personas, utilicemos un modelado de información que nos permita “ver” como se interrelacionan dichas personas.
Pero la Analítica de Grafos no es sólo un modo de visualización o modelado, sino que nos permite la aplicación de diferentes técnicas y algoritmos matemáticos que nos
permiten inferir patrones de comportamiento en el conjunto de nuestros clientes o anomalías que se encuentran en nuestros datos de un modo automatizado.
En mi opinión, la detección de fraude o la determinación del riesgo de un determinado perfil es una tarea realmente compleja y no existen los sistemas infalibles. Sin embargo, la utilización de la Analítica de Grafos junto con el Machine Learning y el enriquecimiento de la información aporta un elemento diferenciador en la lucha contra el fraude y puede generar importantes beneficios para una compañía que decida emprender dicho camino.
Fuente: bites.futurespace.es, 15/11/17.
Más información:
La Inteligencia y sus especialidades en la Sociedad del conocimiento
___________________________________________________________________
.
.