
La inteligencia estratégica en las organizaciones políticas y empresariales. Seminario Internacional. Julio 2021
junio 16, 2021
SEMINARIO INTERNACIONAL
“LA INTELIGENCIA ESTRATÉGICA EN LAS ORGANIZACIONES POLÍTICAS Y EMPRESARIALES”
FECHAS: 16 y 17 de julio
- De 18:00 Hs. a 21:00 Hs.
- De 09:00 Hs. a 12:00 Hs.
Medio: Plataforma Zoom
Responsable: ITAJU COMUNICACIONES CONSULTORÍA
INVITADOS ESPECIALES: Dr. Euclides Acevedo – Dr. Horacio Galeano Perrone
AGENDA
SUBTEMAS:
Viernes 16-07-21
18:00 a 18:10: Saludo a los ponentes e invitados especiales – mensaje de bienvenida
Dra. María Amelia Britos Bogado
18:10 a 18:30 Hs. La inteligencia estratégica, una herramienta necesaria para la toma decisiones, un imperativo del mundo actual. Dr. Ricardo Spadaro. Argentina.
18:30 a 19:00 Hs. Aplicación de la inteligencia en organizaciones empresariales y el valor que implica: Ing. Gustavo Ibáñez Padilla. Argentina
19:00 a 19:30 Hs. La inteligencia estratégica y el crimen organizado. Desafíos para el Siglo XXI: Prof. Mg. Marcelo Luis Martinengo. Argentina
19:30 a 20:00 Hs. La inteligencia estratégica y la seguridad interna: Crio. Antonio Gamarra. Paraguay
20: 00 a 20:30 Hs. La inteligencia estratégica y la construcción de escenarios prospectivos: Cnel. Hugo Vera. Paraguay
20:30 a 21:00 Hs. Preguntas del auditorio – Conclusiones.
Sábado 17-07-21 Moderadores: Lic. José María Condomí (Analista de Inteligencia Estratégica Militar – 2005. Escuela de Inteligencia de las Fuerzas Armadas Argentinas y Dra. María Amelia Britos Bogado (Máster en Planificación Estratégica nacional – Ministerio de Defensa Nacional de Paraguay – año 2006)
09:00 a 09:15. Saludo e introducción a los temas. Dr. Horacio Galeano Perrone
09:15 a 09:40. La inteligencia política en las instituciones gubernamentales. Mg. Alessandra Martin. México.
09:40 a 10:20. La inteligencia y la comunicación política: Dr. Ricardo Amado Castillo. Venezuela – Mg. Alejandra Cáceres. Argentina.
10:20 a 11: 00. La inteligencia artificial aplicada al sector público y privado. Lic. Facundo Armas. Argentina
11:00 a 11:20. Herramientas de la inteligencia humana. La comunicación no verbal – inteligencia comportamental: Mg. Marisa Barrera. Argentina.
11:20 a 11:40. Debate con el auditorio. Conclusiones
11: 40 a 12: 00. Entrega virtual de Certificados.
Agradecimiento.

.

.
.

.
.
¿Qué es la Geopolítica?
mayo 18, 2021
La Geopolítica es el estudio de los efectos de la Geografía sobre la Política y las Relaciones internacionales. La geopolítica es un método de estudio de la política exterior para entender, explicar y predecir el comportamiento político internacional a través de variables geográficas.
Curso: «Geopolítica como herramienta para el Análisis e investigación social», FES Acatlán, UNAM, 2017. Por Rocío Arroyo. Son 6 videos.
.
.
.
.
.
Video 06. Uso de la Geopolítica en la investigación: https://youtu.be/SnA_DYM1bxc
Ejemplo: Caso de investigación:
América Latina desde un enfoque del sistema-mundo.
Fuente: Rocío Arroyo

______________________________________________________________________________
Más información:
La Geopolítica del Libre comercio
Geopolítica e Inteligencia de Negocios
Ciberespionaje, influencia política y desinformación

______________________________________________________________________________
Vincúlese a nuestras Redes Sociales:
LinkedIn YouTube Facebook Twitter
______________________________________________________________________________

.
.
Sorpresas Estratégicas
diciembre 3, 2020
Sorpresas estratégicas e Inteligencia de alerta temprana
Por Javier Jordán
Global Strategy Report, 56/2020
Resumen: Este documento analiza las causas de las sorpresas estratégicas en materia de Defensa agrupadas en cuatro conjuntos de factores: limitaciones metodológicas, sesgos cognitivos, patologías en las organizaciones responsables de generar inteligencia de alerta temprana, y escasa receptividad política que conduce a un déficit de respuesta.
En la vida algunas sorpresas resultan agradables pero en materia de Defensa rara vez lo son. Esto se debe a las tres notas características de las sorpresas estratégicas: van en contra de las expectativas, suponen un fallo de la alerta temprana y, habitualmente, llegan sin contar con la preparación adecuada (Kam, 1988: 8).
En el marco de una relación antagónica la sorpresa se convierte en un multiplicador de fuerza (Handel, 1984: 229-230). De modo que quien se perciba en situación de inferioridad se sentirá especialmente tentado a utilizarla como instrumento compensatorio. Esto puede suceder a nivel estratégico (ataque japonés a Pearl Harbour en diciembre de 1941 u ofensiva preventiva israelí en junio de 1967) y a nivel táctico: la sorpresa es un elemento indispensable en los golpes de mano de la guerrilla o las acciones terroristas.
No obstante, la sorpresa también forma parte de la planificación militar cuando la correlación resulta favorable pues debilita la resistencia del adversario. Por ello el Ejército Rojo continuó con las acciones de maskirovka (ocultación, engaño) durante los años 1944 y 1945 a pesar de que su ventaja sobre el ejército alemán ya era significativamente superior (Dick, 2019). La sorpresa forma parte por tanto de la propia naturaleza de la guerra.
Pero a pesar de ese efecto multiplicador, la sorpresa rara vez constituye un factor decisivo sobre el resultado final del conflicto, pues no existe correlación positiva entre los éxitos iniciales derivados de sorpresas estratégicas y la victoria en la guerra (Cancian, 2018: 32). Es más, puede ocurrir que el éxito del ataque sorpresa supere las expectativas y no se explote adecuadamente (Handel, 1984: 230).
La sorpresa no se circunscribe a la transición de paz a guerra, o cuándo y en qué sector del frente se producirá un ataque. La sorpresa puede ser también tecnológica. Para la Wehrmacht fue de lo más desagradable encontrarse en los primeros compases de la invasión de Rusia con el hasta entonces desconocido T-34. Y a los norteamericanos les ocurrió algo parecido al descubrir la superioridad en combate aire-aire del Zero durante los primeros meses de la guerra en el Pacífico. Por otro lado, la sorpresa es doctrinal cuando la efectividad de un sistema ya conocido se utiliza en combate de una manera innovadora. Un caso de libro fue el éxito en el empleo de las unidades acorazadas en mayo de 1940, que resultó una sorpresa para franceses y británicos pero también para gran parte de la propia Wehrmacht.
La sorpresa tecnológica y la doctrinal pueden tener efectos estratégicos. Por ejemplo, ¿serán verdaderamente eficaces los aviones de ataque de quinta generación y los misiles stand-off contra un sistema de defensa aérea avanzado? ¿Sobrevivirán los portaviones norteamericanos al A2/AD de China en las aguas del primer anillo de islas? De ahí que Colin S. Gray (2005: 43) afirme sabiamente: “las etapas iniciales de un conflicto consisten en una carrera entre los beligerantes para corregir sus respectivas creencias equivocadas sobre cómo se desarrollaría la guerra”.
Las sorpresas también pueden ser políticas y diplomáticas. Por ejemplo, un realineamiento de alianzas (como el de la Alemania nazi con la Unión Soviética en agosto de 1939), un hecho consumado por debajo del umbral de la guerra (invasión rusa de Crimea en 2014), o afectar a las interacciones dentro de un conflicto o crisis donde suele darse un amplio margen para el oportunismo político o la flexibilidad estratégica ante circunstancias dinámicas (en el conflicto de Siria ha habido varios casos a lo largo de estos casi diez años).

Evidentemente, la sorpresa admite grados (Parker & Stern, 2005: 303). Pocas veces es completa. Como ya he comentado al hablar del COVID-19, los ‘cisnes negros’ son un fenómeno relativo. Dependen de la perspectiva del observador. Lo que para unos es altamente improbable para otros es algo que tarde o temprano acabará ocurriendo. Es frecuente que tras producirse un error grave de anticipación se descubran informaciones relevantes y disponibles que por una u otra razón no fueron consideradas en la cadena de alerta y respuesta temprana (Grabo, 2010: 20). Y este es el tema del presente Report: por qué se producen las sorpresas estratégicas en materia de Defensa.

A la hora de explicar el origen de las sorpresas hay que prestar atención a distintas dimensiones y a la interacción entre ellas. Normalmente, el problema es sistémico y multivariable. Algo que ya detectaron Eliot Cohen y John Gooch (2006: 54-56) al analizar diversos desastres militares. Por ello al agregar las distintas variables que explican las sorpresas, podemos establecer cuatro conjuntos de factores: metodológicos, cognitivos, organizacionales y políticos. Veamos cada uno de ellos.
Limitaciones metodológicas
Desde esta perspectiva, la sorpresa puede deberse a varias razones. En primer lugar a que la naturaleza de lo que se quiere conocer escape las posibilidades de los métodos disponibles. Se trata de la conocida diferencia entre puzles y misterios (Treverton, 2001: 11-12). Los primeros, al igual que los crucigramas se pueden resolver porque sus componentes existen. Se trata de dar con ellos y encajarlos correctamente. Por ejemplo, quién está financiando los nuevos programas de adquisiciones militares de Marruecos (que exceden el músculo financiero del país): ¿Emiratos? ¿Arabia Saudí? ¿Estados Unidos, financiando parte de la venta?; o ¿qué nivel de operatividad tienen realmente esos equipos una vez que llegan a las unidades? Son preguntas que tienen respuesta.
Los misterios aluden sin embargo a intenciones futuras o a los caminos que puede recorrer la interacción entre distintas variables clave. Siguiendo con el ejemplo de Marruecos, ¿esos programas de adquisiciones constituyen un mero reemplazo de generaciones armas próximas a la obsolescencia o serán también la herramienta para una acción exterior más asertiva? ¿El arsenal marroquí se orientará solo a la disuasión frente a Argelia o aumentará el margen de actuación, junto a otras estrategias (híbridas), en las disputas territoriales con España?
Los puzles y los misterios requieren aproximaciones metodológicas diferentes. Por su naturaleza, los puzles son el objeto propio de los medios de obtención de inteligencia, de la investigación científica y de la indagación periodística. Forman parte de lo empírico. De lo constatable.
Los misterios por su parte pertenecen al campo de la prospectiva estratégica, al análisis y construcción de futuros alternativos. Su esclarecimiento no admite una respuesta simple y directa, sino un esfuerzo por entender las fuerzas motrices (drivers) cuya interacción puede dar lugar a distintos mañanas. Y, una vez identificadas dichas fuerzas, la respuesta a los misterios requiere un sistema de vigilancia prospectiva que siga la evolución de los diferentes drivers y esté atento a nuevas fuerzas emergentes con el fin de obtener cierto grado de anticipación estratégica.
En consecuencia, un sistema de alerta temprana se expone a grandes sorpresas asociadas a los misterios si se orienta de manera desproporcionada a la resolución de puzles, priorizando la inteligencia de actualidad –lo que ocurre ese día o esa semana– a costa casi por completo del análisis estratégico y la prospectiva. La inteligencia de actualidad (current Intelligence) no es sinónimo de inteligencia de alerta temprana (Grabo, 2010: 15-16). Y si existe un desequilibrio excesivo a favor de la inteligencia de actualidad se debilita la producción de inteligencia en su conjunto.
El análisis estratégico y la prospectiva no ofrecen garantía plena por sus propias limitaciones metodológicas. Pero ambos proporcionan una perspectiva más amplia que ayuda procesar las ‘señales débiles’ –piezas aparentemente aisladas de información de interpretación ambigua– que adquieren significado al conectarlas con patrones y tendencias identificadas en un esfuerzo previo de análisis estratégico y de prospectiva. Dicho de otro modo, la inteligencia de alerta temprana está abocada al fracaso si la arquitectura institucional y la cultura de la organización no contemplan el estudio sistemático del futuro.
El conocimiento anticipativo, que se basa en buena medida en marcos explicativos correctos y en un buen sistema de vigilancia prospectiva, ayuda a convertir las señales débiles en señales de alerta temprana.

En segundo lugar, la inteligencia de alerta temprana –especialmente en el ámbito militar– suele utilizar sistemas de indicadores que evalúan la capacidad y las intenciones de un potencial adversario. Como es sabido las capacidades militares incluyen los elementos materiales e inmateriales del MIRADO-I (Materiales, Infraestructuras, Recursos humanos, Adiestramiento, Doctrina, Orgánica e Interoperabilidad). Son observables y hasta cierto punto medibles. A la vez, mantener el despliegue y un alto nivel de alistamiento de gran parte de la fuerza resulta prohibitivo. De modo que el incremento sustancial de los niveles de preparación para el combate y los despliegues no justificados constituyen señales clásicas y poderosas de alerta (Grabo, 2010: 46-47).
A su vez, las intenciones engloban tanto las genéricas (por ejemplo, la postura de Defensa) como las específicas e inmediatas (por ejemplo, en el marco de una pre-crisis). Las intenciones específicas de un actor potencialmente agresivo se pueden estimar a partir de las intenciones genéricas –los objetivos conocidos de sus decisores políticos–, las declaraciones públicas, la posibilidad de alcanzarlos a través de un determinado curso de acción, que cuente con medios para ello y que haya descartado otras vías menos hostiles para lograrlos (Grabo, 2010: 236). También de la importancia concedida por ese a determinados objetivos, que puede ser muy diferente a la de quien analiza. Un ejemplo de esto último, fue el modo como los británicos minusvaloraron los sentimientos de los dirigentes y de la sociedad argentina hacia las Malvinas en vísperas de la invasión de abril de 1982 (Hopple, 1984: 348). Obviamente, el problema es irresoluble –un misterio– cuando esas élites políticas no han decidido qué curso de acción seguir.
Los sistemas de indicadores constituyen un elemento esencial de la inteligencia temprana pero al mismo tiempo se ven afectados por limitaciones metodológicas:
- Ambigüedad, sobre todo en lo referente a las intenciones. La movilización militar es difícil de esconder pero los juegos políticos son menos transparentes, lo que lleva a que la combinación de ambos conduzca a distintas interpretaciones: ¿el despliegue de unidades del ejército iraquí en la frontera de Kuwait en julio de 1990 era una demostración de fuerza en clave diplomática o el paso previo a una invasión? Algo similar ocurrió con el despliegue del ejército egipcio los días previos la guerra del Yom Kippur: a pesar de que los indicadores alertaban de un ataque no se podía descartar por completo la hipótesis de las maniobras militares (Honig, 2008: 75). La inteligencia de alerta entraña una valoración basada en probabilidades, no en certezas absolutas (Grabo, 2010: 23-24). Y cuanto mayor sea la ambigüedad, mayor peso tendrán sobre el analista sus propias presunciones (Betts, 1978: 70).
- Engaño, que aumenta la ambigüedad. Como dicen los anglosajones: “The enemy gets a vote”. En el bando adversario hay personas muy inteligentes, bien entrenadas, y que hacen brillantemente su trabajo (Cancian, 2018: 25-26). Toda operación militar antagónica incorpora acciones de engaño para ocultar –al menos al comienzo– el auténtico curso de acción. Los engaños más eficaces son además aquellos que simulan lo que la víctima quiere creer. Por tanto, el analista de inteligencia ha de mantener una actitud de desconfianza por defecto, sin descartar informaciones potencialmente alarmantes hasta estar razonablemente seguro de que existe una explicación para esa anomalía (Grabo, 2010: 82). Pero al mismo tiempo esta inclinación ha de ser equilibrada para no generar, como veremos, cansancio de la alarma y falsos positivos.
- Paradoja de la sensibilidad. Cuanto más se afinen los indicadores (en grado de detalle), más riesgo de falsos positivos. Pero a la vez, unos indicadores demasiado genéricos corren el riesgo de no medir bien los cambios amenazantes (Betts, 1978: 63), por lo que se trata de encontrar un equilibrio.
Los sistemas clásicos de indicadores requieren una profunda adaptación al vigilar los conflictos en la zona gris, con empleo de estrategias híbridas (multidimensionales) y caracterizados precisamente por la ambigüedad y el gradualismo.
Los indicadores militares de alerta temprana tradicionales se construyen asumiendo que el adversario tiene que dar una serie de pasos a la hora de preparar una acción hostil (incrementar el nivel de alistamiento, desplegar la fuerza, activar la cadena logística, etc.). Dichos pasos se deducen de la experiencia histórica, del conocimiento específico de la doctrina militar del país estudiado y de las lecciones aprendidas en crisis o conflictos previos (Grabo, 2010: 60-63).
Sin embargo, en los conflictos en la zona gris los cursos de acción son múltiples, difíciles de prever y multidimensionales (MCDC Countering Hybrid Warfare Project, 2019: 25-32). A ello se añaden los problemas de atribución en lo relacionado por ejemplo con acciones hostiles en el ciberespacio y con operaciones de influencia a través de redes sociales (Treverton, 2018: 17). El sistema de indicadores debe vigilar por ello los distintos instrumentos de poder a disposición del adversario: político, económico, social, informacional, militar, etc. (‘conocidos desconocidos’) y permanecer atento a acciones de manipulación creativas (‘desconocidos desconocidos’) que combinen el uso coordinado de dichos instrumentos para obtener ganancias estratégicas mediante la coerción (Cullen, 2018: 4).

Para complicar más la ecuación, la combinación de acciones en el marco de estrategias híbridas suele tener efectos no previstos, incluso para quienes las orquestan. Al interaccionar con otras variables en sociedades complejas e interconectadas, las consecuencias son dispares e imprevisibles (Mushrush, 2015: 34-35). En particular si quien está desarrollando dichas acciones híbridas lo hace en el marco de una ‘estrategia de caos’ con el propósito de generar disfunciones en el proceso de toma adversario (Jensen & Doran, 2018: 23).
Se trata así de vigilar indicadores prestablecidos de carácter multidimensional, y de anticipar y buscar patrones a partir de lo que está ocurriendo (U.S. Army Special Operations Command, 2016: 10). Lo cual requiere un conocimiento profundo del oponente. De sus fines, medios y modos habituales, incluida la comprensión de sus valores y de su cultura. También son útiles herramientas analíticas que estimulan la creatividad tipo ‘sombrero rojo’ o matrix games. Pero aun así el riesgo de falsos positivos resulta inevitable. La principal garantía es contar con medios de obtención (HUMINT, SIGINT) que permitan tener acceso a la caja negra del proceso de toma de decisiones adversario para conocer cuáles son sus intenciones y estrategias, y de ese modo anticipar, vigilar y responder a sus acciones híbridas.
Limitaciones cognitivas
Tienen que ver con los sesgos de análisis que ya he comentado en otros post previos como este o este otro, que además han sido abordados en Global Strategy (2020) en lo relativo al COVID-19 por Luis De la Corte. Por tanto solo voy a destacar los siguientes:
- Sobrecarga cognitiva, cuanta más información, más ruido. Paradójicamente, el gran problema de la inteligencia de alerta no suele ser la escasez de información sino la saturación (Grabo, 2010: 229-230). Es una de las causas que Roberta Wohlstetter (1962: 387) identifica en su clásico Pearl Harbour. Warning and Decision: “En pocas palabras, fracasamos al anticipar el ataque contra Pearl Harbour no por falta de información relevante como por una plétora de informaciones accesorias”.
- Cansancio de la alarma ante repetidos falsos positivos que erosionan la credibilidad del sistema de indicadores y de los marcos teóricos que los respaldan (Parker & Stern, 2005: 311). La invasión alemana de Noruega en abril de 1940 y la de Holanda un mes más tarde estuvieron precedidas de numerosas falsas alarmas que restaron crédito al “que viene el lobo” auténtico (Betts, 1980: 559). En la película El Ángel se da a entender que Ashraf Marwan aprovechó este sesgo en el contexto previo a la guerra del Yom Kippur, aunque Uri Bar-Joseph niega que fuera un agente doble en The Angel: The Egyptian Spy Who Saved Israel, el libro en el que se basó dicha película. En casos excepcionales, el cansancio de alarma puede deberse a la ‘trampa de la efectividad’. Es decir, a éxitos de alerta temprana cuya respuesta disuade de acciones hostiles (Chan, 1979: 172).
- Marco explicativo incorrecto. Es una de las fuentes de error más conocidas, y suele ir asociada a otros sesgos cognitivos: exceso de confianza, wishful thinking, sesgo de confirmación, no buscar informaciones ausentes que contradigan los presupuestos de partida, arrogancia epistémica al sumar años de experiencia que han solidificado ese marco cognitivo, huir de la complejidad descansando en la explicación simplificada del marco adoptado y, en ocasiones, etnocentrismo. Como consecuencia las señales débiles ‘tácticas’ que permitirían dar la voz de alarma no son interpretadas correctamente y no consiguen por sí solas modificar las presunciones ‘estratégicas’ (Ben-Zvi, 1976: 394). Uno de los casos más conocidos está asociado de nuevo a la guerra del Yom Kippur, pues la inteligencia militar israelí daba por sentado que ni Siria ni Egipto iniciarían una guerra hasta que sus respectivas fuerzas aéreas superaran a la israelí. Pero en su lugar ambos países optaron por sistemas antiaéreos móviles avanzados para negar el espacio aéreo operacional a la IAF (Gross Stein, 1980: 155-156; Handel, 1984: 242; Ben-Zvi, 1997: 136-137;). Como también es sabido, tras aquella experiencia los israelíes establecieron un sistema de explicaciones alternativas (ipcha mistabra: “lo contrario es probable” o el equivalente al ‘abogado del diablo’ occidental) para desafiar los marcos explicativos dominantes (Pascovich, 2018: 858).
- Falta de pensamiento creativo. Según el informe de la Comisión (2014: 336) que investigó los atentados del 11 de septiembre de 2001, uno de los principales errores consistió en un “fallo de imaginación y una mentalidad poco abierta a ese tipo de posibilidades” en la anticipación, detección y prevención de dichos ataques. De nuevo, la construcción y análisis de escenarios, los ejercicios de ‘equipo rojo’, de ‘sombrero rojo’, los ‘matrix games’ y –en el ámbito militar los wargames, la experimentación y los ejercicios–, son útiles a la hora de generar escenarios y líneas de actuación plausibles que escapan al análisis convencional (Cancian, 2018: 83-90). También resulta interesante el análisis de hipótesis en competición para explorar y contrastar diferentes explicaciones a una conducta sospechosa, o emplear una matriz de análisis morfológico para visualizar las opciones múltiples del adversario y elaborar a partir de ellas indicadores de seguimiento.
Patologías estructurales en las organizaciones de Inteligencia
Determinados aspectos de la arquitectura, la praxis o la cultura de la organización de Inteligencia pueden resultar problemáticos a la hora de anticipar sorpresas. Ya hemos mencionado que un desequilibrio que enfatice en exceso la producción inteligencia de actualidad descuidando el análisis estratégico y la prospectiva tiene costes en términos de anticipación y de pérdida de visión periférica. Igualmente, la ausencia de un sistema de indicadores o un diseño defectuoso de estos también dificulta el seguimiento de las amenazas.
Y a todo lo anterior, habría que sumar los sospechosos habituales en la literatura sobre errores de inteligencia:
- Problemas de conexión entre los órganos de obtención y de análisis dentro de la propia organización de Inteligencia. No se trata solo de que la información recolectada llegue a los analistas, sino que exista una coordinación correcta que traduzca los interrogantes de los analistas en nuevos requerimientos de obtención (Grabo, 2010: 38).
- Defectos de la arquitectura de Inteligencia nacional que dificultan la coordinación entre las distintas organizaciones que participan en su elaboración. No en vano la comunidad de Inteligencia norteamericana tiene su origen histórico en la sorpresa del ataque japonés a Pearl Harbour. La compartimentalización de la inteligencia es un fenómeno que la literatura anglosajona sobre Inteligencia denomina stovepiping, transmitiendo la imagen de varias chimeneas que lanzan el humo en vertical –la inteligencia al decisor– sin conexión entre ellas. Este problema también estuvo presente en los atentados del 11-S. Los centros de fusión y el rol efectivo de los directores o autoridades nacionales de Inteligencia –en caso de que existan– tienen como función evitarlo.
- Competencia malsana entre las distintas instituciones que componen la comunidad de Inteligencia. Cierto grado de competición resulta saludable. El problema es cuando se politiza corporativamente y se convierte en lucha de feudos, lo que obviamente complica la comunicación y coordinación.

Escasa receptividad de quienes han de responder
Un último conjunto de factores a la hora de explicar las sorpresas tiene que ver la aceptación de la inteligencia de alerta temprana por parte de los responsables de alto nivel. En esta dimensión los problemas no se encuentran tanto en la inteligencia anticipativa como en lo que algunos autores denominan el warning-response gap (George & Holl, 1997: 9). Según Richard K. Betts (1978: 61-63), es en este nivel donde se han producido los errores históricos más conocidos: Pearl Harbour, la invasión nazi de la Unión Soviética, la intervención de China en Corea en 1950 y el estallido de la guerra del Yom Kippur. En todos ellos hubo: 1) señales de alerta que no fluyeron de manera efectiva a través de la cadena de mando; y 2) señales fragmentadas que sí llegaron a los decisores pero fueron desechadas porque contradecían sus presupuestos estratégicos. El ejemplo por antonomasia es la negativa de Stalin a aceptar más de ochenta alertas específicas de invasión alemana, ordenando incluso ejecutar a alguna fuente por lo que él entendía como ‘desinformación’ (Cancian, 2018: 33).
Aunque la carencia entre alerta y respuesta puede ser de carácter táctico –una acción hostil concreta de impacto limitado–, es especialmente interesante analizar este fenómeno cuando la sorpresa es estratégica: un cambio de tendencia de gran calado y de enorme impacto. Algo que en principio tendría más base para interpelar a los decisores, que suele presentarse con tiempo –no de manera repentina–, pero que sin embargo no consigue su atención. Un fenómeno que Michele Wucker (2016) desarrolla con profundidad en The Gray Rhino. How to Recognize and Act on the Obvious Dangers We Ignore.
De manera también esquemática destaco algunos factores que crean esa fractura entre la alerta y la respuesta adecuada.
- Relación precaria entre quienes producen inteligencia y los decisores políticos. Puede deberse a falta de credibilidad como consecuencia de errores previos de los primeros. Pero también a falta de interés sobre las cuestiones de inteligencia por parte de los segundos. Uno de los ejemplos más conocidos fue la relación del presidente Bill Clinton con el entonces director de la CIA, James Woolsey. En palabras de este último: “no es que tuviera mala relación con el presidente, sino que simplemente no tenía ninguna”. O como expresó en otra ocasión sarcásticamente: “¿recuerda a aquel tipo que estrelló una avioneta en el césped de la Casablanca? Era yo tratando de conseguir una reunión con el presidente” (Warner, 2014: 260).
- Competición con otros asuntos de la agenda política. Se trata de un viejo problema estudiado por la Ciencia Política. No es tanto el caso de la alerta ante problemas inmediatos (una crisis internacional a punto de estallar o una amenaza fundada de atentado terrorista) como de la alerta ante sorpresas estratégicas cuyo gestación ocupa un tiempo más dilatado. El proceso por el que unos asuntos tienen prioridad sobre otros en la agenda política ha sido explicado entre otros por John Kingdon (1995: 77-86) en su teoría de las corrientes múltiples, y en gran medida también resulta aplicable al warning-response gap. En el primer epígrafe de esta publicación explico los elementos esenciales de la propuesta de Kingdon. Para que un asunto no urgente escale puestos en la agenda, los servicios de Inteligencia han de actuar a veces como ‘emprendedores políticos’: recabando la atención de otras burocracias, actores sociales e incluso medios de comunicación, como vía indirecta para llegar a los decisores políticos; sobre todo, si el asunto en cuestión no coincide con las afinidades y prioridades de dichos decisores.
- Falta de tiempo y de reflexión por parte de los responsables políticos. Se encuentra relacionado con el punto anterior y a primera vista parece un obstáculo trivial, pero es otro factor que explica la falta de respuesta ante eventualidades anticipadas. Se crean cuellos de botella donde la inteligencia de alerta queda aprisionada. En alusión a un problema distinto a las sorpresas estratégicas, el ex Secretario de Defensa, Robert McNamara (1996: xxi) exponía en sus memorias una consideración que resulta válida para lo que estamos analizando: “Una de las razones por las que las Administraciones Kennedy y Johnson no llegaron a un planeamiento ordenado y racional de las cuestiones referentes a Vietnam fue la asombrosa diversidad y complejidad de otros asuntos a los que nos enfrentábamos. Dicho de manera sencilla, nos veíamos ante un diluvio de problemas; el día tenía sólo veinticuatro horas y, a menudo, no disponíamos de tiempo para pensar con claridad”. Esta situación se agudiza en un contexto de crisis, donde las consideraciones a corto plazo tienen un protagonismo desproporcionado que resta influencia al cálculo de los costes a largo plazo (Lebow, 2007: 73).
- Ir contra la línea o encuadre político establecido. Ya que en tal caso quienes dirijan la política preferirán explicaciones alternativas a los informaciones que motivan la alarma, que –como ya he señalado– es a menudo ambigua (Chan, 1979: 172; Ben-Zvi, 1997: 115). Para quien produce la inteligencia el reto consiste entonces en mantener el compromiso con la verdad, sin caer en el vicio conocido como inteligencia para agradar (intelligence to please,) a la espera de obtener la atención y aprobación del nivel político.
En función de los casos, estos problemas pueden estar más o menos interrelacionados y a la postre acaban creando un patrón de ignorancia, negación y distracción respecto al problema emergente, con distinta intensidad en la cadena que va desde los responsables de la vigilancia hasta quienes han de decidir y articular las respuestas.
Y, para concluir, a partir de los cuatro conjuntos de factores analizados en este Report (limitaciones metodológicas, sesgos cognitivos, patologías en las organizaciones de Inteligencia, y escasa receptividad política que conduce a un déficit de respuesta) se deducen diversas líneas maestras para anticipar las sorpresas. Una de ellas, acorde con los contenidos de esta web, consiste en equilibrar el análisis de actualidad con el análisis estratégico y la prospectiva, –empleando técnicas que estimulen la creatividad y desafíen los marcos cognitivos establecidos– para a partir de ambos disponer de un sistema de vigilancia que siga la evolución de los indicadores seleccionados. Esto ayuda a identificar y dar sentido a las señales débiles, convirtiéndolas en señales de alerta temprana.
Referencias
Ben-Zvi, Abraham (1976), “Hindsight and Foresight: A Conceptual Framework for the Analysis of Surprise Attacks”, World Politics, Vol. 28, No. 3, pp. 381-395.
Ben‐Zvi, Abraham (1997), “The Dynamics of Surprise: The Defender’s Perspective”, Intelligence and National Security, Vol. 12, No 4, pp. 113-144.
Betts, Richard K. (1978), “Analysis, War, and Decision: Why Intelligence Failures Are inevitable”, World Politics, Vol. 31, No. 1, pp. 61-89.
Betts, Richard K. (1980), “Surprise Despite Warning: Why Sudden Attacks Succeed”, Political Science Quarterly, Vol. 95, No. 4, pp. 551-572.
Bryon D. Mushrush. Improved Intelligence Warning in an. Age of Complexity. Fort Leavenworth, KA: School of Advanced Military Studies.
Cancian, Mark F. (2018), Coping with Surprise in Great Power Conflicts, Washington DC: Center for Strategic and International Studies.
Chan, Steve (1979), “The Intelligence of Stupidity: Understanding Failures in Strategic Warning”, The American Political Science Review, Vol. 73, No. 1, pp. 171-180.
Cohen, Eliot A. & Gooch, John (2006), Military Misfortunes: the Anatomy of Failure in War, New York: Free Press.
Cullen, Patrick (2018), “Hybrid Threats as a New ‘Wicked Problem’ For Early Warning”, Strategic Analysis, Hybrid Center of Excellence.
De la Corte, Luis (2020), “¿Por qué se subestimó al Covid-19? Un análisis preliminar desde la Psicología y la Sociología del Riesgo”, Global Strategy Report, 23/2020.
Dick, Charles J. (2019), De la derrota a la Victoria. Arte operacional en el frente del Este. Verano de 1944, Málaga: Ediciones Salamina.
George, Alexander L. & Holl, Jane E. (1997), The Warning-Response Problem and Missed Opportunities in Preventive Diplomacy, New York: Carnegie Corporation of New York.
Grabo, Cynthia (2010), Handbook of Warning Intelligence: Assessing the Threat to National Security, Lanham: Scarecrow Press.
Gray, Colin S. (2005), Another Bloody Century: Future Warfare, London: Weidenfeld and Nicolson.
Gross Stein, Janice (1980), “‘Intelligence’ and ‘Stupidity’ Reconsidered: Estimation and Decision in Israel, 1973”, Journal of Strategic Studies, Vol. 3, No 2, pp. 147-177.
Handel, Michael I. (1984), “Intelligence and the Problem of Strategic Surprise”, Journal of Strategic Studies, Vol. 7, No 3, pp. 229-281.
Honig, Or (2008), “Surprise Attacks—Are They Inevitable? Moving Beyond the Orthodox–Revisionist Dichotomy”, Security Studies, Vol. 17, No 1, pp. 72-106.
Hopple, Gerald W. (1984), “Intelligence and Warning: Implications and Lessons of the Falkland Islands War”, World Politics, Vol. 36, No. 3, pp. 339-361.
Jensen, Donald N. & Doran, Peter B. (2018), Chaos as a Strategy. Putin’s ‘Promethean’ Gamble, Washington D.C., Center for European Policy Analysis.
Kam, Ephraim (1988), Surprise Attack: The Victim’s Perspective, Cambridge, MA. Harvard University Press.
Kingdon, John W. (1995), Agendas, Alternatives, and Public Policies, New York: HaperCollins.
Lebow, Richard Ned (2007), “Revisiting the Falklands Intelligence Failures”, The RUSI Journal, Vol. 152, No 4, pp. 68-73.
Lesca, Humbert & Lesca, Nicolas (2011), Weak Signals for Strategic Intelligence, London: ISTE.
MCDC Countering Hybrid Warfare Project, Countering Hybrid Warfare (London: UK Ministry of Defence 2019)
McNamara, Robert S. with VanDeMark, Brian (1996), In Retrospect: The Tragedy and Lessons of Vietnam, New York: Vintage Books.
National Commission on Terrorist Attacks, (2004), The 9/11 Commission Report. Washington DC, W. W. Norton.
Parker, Charles F. & Stern, Eric K. (2005), “Bolt From the Blue or Avoidable Failure? Revisiting September 11 and The Origins of Strategic Surprise”, Foreign Policy Analysis Vol. 1, No 3, pp. 301-331.
Pascovich, Eyal (2018), “The Devil’s Advocate in Intelligence: The Israeli Experience”, Intelligence and National Security, Vol. 33, No 6, pp. 854-865.
Pierri, Hugo (2020), “Revalorizando la anticipación estratégica”, Global Strategy, 27 de abril.
Treverton, Gregory (2018), “The Intelligence Challenges of Hybrid Threats”, Center for Asymmetric Threat Studies.
Treverton, Gregory F. (2001), Reshaping National Intelligence for an Age of Information: Cambridge: Cambridge University Press.
U.S. Army Special Operations Command, Perceiving Gray Zone Indications (Fort Bragg, NC: U.S. Army Special Operations, 2016).
Editado por: Global Strategy. Lugar de edición: Granada (España). ISSN 2695-8937
Fuente: global-strategy.org, 2020

.
.
El Teorema de Bayes en el Análisis de Inteligencia
julio 1, 2020
“Bayes ingenuo” en apoyo del análisis de inteligencia
Por José-Miguel Palacios.
Un interesante artículo de Juan Pablo Somiedo[1], aparecido a finales de 2018, nos recordaba que el teorema de Bayes[2], en su versión más elemental (lo que se suele llamar “Bayes ingenuo”) puede seguir siendo útil en análisis de inteligencia.
El teorema de Bayes en el análisis de inteligencia
Se puede argumentar que todo análisis de inteligencia es bayesiano en su naturaleza. En esencia consiste en obtener unas evidencias iniciales, simples fragmentos de una realidad bastante compleja, para formular después hipótesis explicativas, recolectar más evidencia y verificar cuál de nuestras hipótesis se ajusta mejor a la evidencia disponible. Algo que no es esencialmente distinto de la “lógica bayesiana”, es decir, de ir modificando nuestras valoraciones subjetivas iniciales a medida que vamos recibiendo evidencias más o menos consistentes con ellas.
En las décadas de 1960 y 1970 hubo varios intentos de utilizar directamente el teorema de Bayes para fines de análisis de inteligencia. Algunos de ellos han sido documentados en las publicaciones del Centro para el Estudio de la Inteligencia de la CIA[3]. Los resultados, sin embargo, no llegaron a ser plenamente convincentes. Y una de las razones principales fue que el mundo real resultó ser demasiado complejo para los modelos elementales que deben considerarse al utilizar “Bayes ingenuo”. Y es que estos modelos presuponen la invariabilidad de la situación inicial (oculta a nuestros ojos), así como la independencia absoluto de los sucesos que vamos considerando. Este problema puede resolverse mediante el uso de “redes bayesianas”[4] y los resultados son matemáticamente correctos, aunque aquí el principal problema radica en conseguir modelar correctamente la realidad. Es el enfoque que fue seleccionado para el programa Apollo[5] y otros similares.
A pesar de todo, y con las debidas precauciones, el uso de “Bayes ingenuo” puede ayudarnos en algunos casos a valorar la evidencia de que disponemos. Para que ello sea así, tendríamos que prestar atención a neutralizar las principales debilidades del método. A saber:
a) Deberíamos utilizar únicamente evidencia relativamente “reciente” (algo que, medido en tiempo, puede tener distintos significados dependiendo de los casos). El problema es que Bayes nos da información sobre una situación preexistente y oculta (por ejemplo, la decisión que puede haber adoptado un determinado líder político) fijando nuestra atención en sus manifestaciones visibles. Si la evolución de la situación es bastante lenta (por ejemplo, la soviética durante el brezhnevismo medio y tardío), podemos asumir que no cambia sustancialmente durante años, por lo que el momento de obtención es escasamente relevante para la valoración de la evidencia. En situaciones más dinámicas, como suelen ser la actuales, las posiciones de los líderes se están modificando continuamente como consecuencia de los cambios que se producen en el entorno. Evidencia relativamente antigua puede referirse a una “situación oculta” que ya no es actual. Por ello, deberíamos utilizar solo evidencia bastante nueva y, si la crisis continúa, prescindir de la más antigua en beneficio de otra más reciente.
b) En la medida de lo posible, el conjunto de las hipótesis debería cubrir la totalidad de las posibilidades existentes, y no debería existir ningún solape entre las diferentes hipótesis. En la práctica, este objetivo es casi imposible de alcanzar, aunque cuanto más nos acerquemos a él, más fiables serán los resultados que obtengamos al aplicar “Bayes ingenuo”.
c) Las evidencias (“Sucesos”) deberían ser de un “peso similar” y no estar relacionadas entre sí[6].

En la práctica
Hemos elaborado una hoja de Excel[7], con la esperanza de que pueda ayudar con los cálculos matemáticos que esta técnica requiere. Para rellenarla, seguiremos los siguiente pasos, sugeridos por Jessica McLaughlin[8]:
1) Creamos un conjunto de hipótesis mutuamente excluyentes y colectivamente exhaustivas relativas al fenómeno incierto que queremos investigar. Como ya hemos explicado, es, quizá, uno de los pasos más difíciles. En general, resulta complicado imaginar hipótesis que sean por completo mutuamente excluyentes (sin ningún solape entre ellas). Y no lo es menos conseguir que el conjunto de ellas agote todas las posibilidades.
2) Asignamos probabilidades previas (pr.previa, en nuestra hoja de cálculo) a cada una de las hipótesis. La probabilidad previa es nuestra estimación intuitiva de la probabilidad relativa de cada una de las hipótesis. Dado que son mutuamente excluyentes y que cubren todas las posibilidades, la suma de las probabilidades previas debe ser 1. En nuestra tabla, expresamos las probabilidades en tantos por ciento.
3) Ahora debemos ir incorporando los “Sucesos” que nos servirán para valorar las hipótesis. El método reajusta las probabilidades de las hipótesis después de cada suceso, por lo que estos pueden añadirse secuencialmente, según se van produciendo o según tenemos noticia de ellos. Una buena elección de sucesos es muy importante para que el método produzca resultados aceptables. Los sucesos deben tener valor diagnóstico (es decir, deben ser más o menos probables según cuál de las hipótesis es la correcta) y, en lo posible, de un “peso” (importancia) similar.
4) Según incorporamos “Sucesos” a la tabla, les asignamos “verosimilitudes” (“verosim.”, en nuestra hoja de cálculo), relativas a cada una de las hipótesis. Se trata para cada caso de la probabilidad estimada por el analista de que el suceso ocurra, suponiendo que la hipótesis que estamos considerando sea correcta. En la tabla, esta probabilidad la expresamos por un entero entre 0 y 100, siendo 0 la imposibilidad total, y 100 la seguridad completa (de que el suceso se producirá suponiendo que la hipótesis se verifica). Obviamente, la suma de todas las verosimilitudes no tiene por que ser la unidad (100% o, según la notación que utilizamos en nuestra tabla, 100).
La propia tabla recalculará las probabilidades de las hipótesis una vez que hayamos computado cada “Suceso”. En nuestra tabla, podemos encontrar estas probabilidades recalculadas en la columna G (“probab.”).
5) Reiteraremos el proceso según añadimos nuevos sucesos. En nuestra tabla, cada nuevo suceso está representado 10 filas más abajo del anterior. Si agotamos los predefinidos en la tabla, podemos añadir más copiando el último “bloque” diez filas más abajo.
Un ejemplo: Crisis de Crimea, marzo de 2020
El proceso puede verse mucho más claro con la ayuda de un ejemplo. Utilizaremos el de la crisis de Crimea de 2014, en particular las dos semanas que siguieron a la caída del Presidente ucraniano Yanukovich, el 21 de febrero. Hemos rellenado la hoja Excel con una serie de “Sucesos” y el resultado puede encontrarse en la hoja prueba_crimea.xlsx[9]. Se trata, evidentemente, de un supuesto didáctico en el que la elección su “Sucesos” y la determinación de las verosimilitudes están condicionados por el interés en ilustrar algunos de los posibles resultados.
Como vemos, la técnica nos permite calcular en todo momento las probabilidades de las diversas hipótesis, y mantener este cálculo actualizado según vamos recibiendo nueva información. Algunas observaciones interesantes:
- a) A fecha 6 de marzo de 2014, consideraríamos casi seguro (probabilidad del 90%) que la intención rusa sea anexionar la península de Crimea.
- b) Sin embargo, unos días antes (según la tabla) no estaría tan claro. El 1 de marzo la hipótesis de la anexión era ya la más probable (55%), pero aún calculábamos una probabilidad notable (39%) de que los rusos estuvieran intentando crear una república virtualmente independiente sin poner en cuestión (formalmente) las fronteras reconocidas (modelo “Transnistria”).
- c) Tan solo unos días antes, hacia el 25-26 de febrero, la hipótesis más probable era aún que los rusos estuvieran intentando impedir que el nuevo gobierno de Kiev tomara el control efectivo de Crimea (probabilidad del 63-68%).
Con la tabla, podemos fácilmente excluir como sospechoso de desinformación un suceso que hemos aceptado previamente, modificar la verosimilitud de sucesos pasados a la luz de nueva evidencia, o cambiar las probabilidades previas de las que hemos partido. En todos estos casos, la tabla nos recalcula automáticamente todas las probabilidades.
Bayes ingenuo y Análisis de Hipótesis Alternativas (ACH)
En el fondo, la técnica de Bayes ingenuo no es muy diferente del Análisis de Hipótesis Alternativas (ACH) de Heuers. La lógica subyacente es la misma (conocer una realidad oculta gracias al estudio de sus manifestaciones visibles) y la diferencia principal radica en la forma de atacar el problema: mientras Bayes ingenuo calcula las probabilidades relativas, ACH intenta descartar hipótesis por ser inconsistentes con la evidencia.
Para ilustrar mejor las diferencias entre estas dos técnicas, hemos elaborado una matriz (prueba ach_crimea.xlsx[10]) con los sucesos y las hipótesis del ejemplo sobre Crimea. Como sabemos, las diversas variantes de ACH se diferencian entre sí por la manera de contabilizar los resultados. En nuestro caso, marcaremos CC y contaremos 2 puntos cuando el suceso sea altamente consistente con la hipótesis, C (1 punto) cuando sea consistente, I (-1) cuando sea inconsistente y X (rechazo de la hipótesis) cuando sea incompatible. Con estas reglas, hemos llegado a los resultados que a continuación se indican:
a) La hipótesis de la Anexión parece la más probable, aunque seguimos atribuyendo una probabilidad considerable a la hipótesis del Caos. Las dos primeras hipótesis (Evitar el control de Kiev sobre la península y el modelo Transnistria) podrían ser descartadas.
b) Si elimináramos la última fila, es decir, si no tomáramos en consideración el suceso del 6 de marzo, las cuatro hipótesis seguirían siendo verosímiles, con dos de ellas (Anexión y Transnistria) vistas como claramente más probables.
Vemos, pues, que partiendo de una lógica similar, las dos técnicas nos conducen a resultados ligeramente distintos. Y en el proceso podemos apreciar algunos de los inconvenientes que cada una de ellas tiene:
a) En ACH el principal problema es que no siempre resulta fácil encontrar sucesos que desmientan alguna de las hipótesis (“coartadas”) por ser completamente incompatibles con ella. Y, en ocasiones, sucesos muy interesantes pueden ser sospechosos de desinformación.
b) En ausencia de “coartadas”, la puntuación en ACH depende mucho de la metodología de cálculo que se siga. La que hemos elegido es, quizá, excesivamente simple. Otras más complejas pueden resultar difíciles de aplicar (aunque hay programas informáticos que pueden servir de ayuda) y resultar en cierta medida arbitrarias.
c) El problema con Bayes ingenuo es que para muchos analistas no resulta intuitivo. El uso de la hoja Excel ayuda mucho a realizar los cálculos, pero puede oscurecer la lógica que hay detrás de ellos.
A modo de conclusión
a) El Teorema de Bayes no sirve para predecir el futuro, sino que nos ayuda a conocer una realidad pasada o presente que permanece oculta a nuestros ojos. Es obvio que si el Presidente del país X ha decidido invadir el país vecino Y, acabará haciéndolo, de no mediar alguna circunstancia que le haga cambiar de opinión. Pero lo que averiguamos no es el hecho futuro (que invadirá), sino el pasado (que ha tomado la decisión de hacerlo).
b) Bayes ingenuo (como también ACH) es más efectivo cuando se usa para estudiar una situación estable, cuando la evidencia se puede recolectar durante un período de tiempo suficientemente largo sin que la “incógnita” que intentamos resolver cambie apreciablemente. Porque cuando la “incógnita” cambia con relativa rapidez, como suele ser el caso durante las crisis actuales, diferentes observaciones realizadas en momentos distintos pueden ser producto de una “realidad oculta” que se ha modificado, que ya no es la misma. Por eso, si queremos que Bayes ingenuo funcione razonablemente bien con situaciones dinámicas, la recogida de datos debe realizarse en plazos de tiempo relativamente cortos. O debemos descartar los “sucesos” más antiguos, que pueden responder a una “realidad oculta” que ya no es real.
c) Más importante que las dos técnicas que hemos examinado en este post es la “lógica bayesiana” que subyace a ambas. En inteligencia (sobre todo, en inteligencia estratégica) es raro conseguir evidencias directas sobre la realidad que nos interesa. Esa realidad siempre permanece oculta a nuestros ojos y lo que podemos averiguar sobre ella es gracias a sus manifestaciones visibles.
d) Quien quiera ocultar una información valiosa no solo intentará protegerla de intentos directos de acceder a ella, sino que tendrá también en cuenta esas manifestaciones visibles, tan difíciles de ocultar. Y lo hará utilizando desinformación. Este es el principal problema para utilizar Bayes ingenuo (o ACH): distinguir la información correcta de la inexacta y de la desinformacón.
Y es que no resulta nada fácil ser un analista inteligente.
[1] SOMIEDO, J.P. (2018). El análisis bayesiano como piedra angular de la inteligencia de alertas estratégicas. Revista de Estudios en Seguridad Internacional, 4, 1: 161-176. DOI: http://dx.doi.org/10.18847/1.7.10. Para una lista de las interesantes aportaciones de Somiedo al estudio de la metodología del análisis de inteligencia, ver https://dialnet.unirioja.es/servlet/autor?codigo=3971893.
[2] Para una explicación rápida del teorema de Bayes, véase https://es.wikipedia.org/wiki/Teorema_de_Bayes.
[3] Puede verse, por ejemplo, FISK, C.F. (1967). The Sino-Soviet Border Dispute: A Comparison of the Conventional and Bayesian Methods for Intelligence Warning. CIA Center for the Study of Intelligence. https://www.cia.gov/library/center-for-the-study-of-intelligence/kent-csi/vol16no2/html/v16i2a04p_0001.htm (acceso: 08.062020).
[4] Los no familiarizados con las redes bayesianas pueden encontrar una introducción elemental de este concepto en https://es.wikipedia.org/wiki/Red_bayesiana.
[5] Ver STICHA, P., BUEDE, D. & REES, R.L. (2005). APOLLO: An analytical tool for predicting a subject’s decision making. En Proceedings of the 2005 International Conference on Intelligence Analysis. https://cse.sc.edu/~mgv/BNSeminar/ApolloIA05.pdf (acceso: 08.06.2020).
[6] Los que conozcan el histórico concurso de televisión Un, dos, tres, responda otra vez recordarán que una táctica muy eficaz para responder consistía en repetir un “objeto”, alterando alguna de sus características. Por ejemplo, si pedían “muebles que puedan estar en un comedor”, ir diciendo sucesivamente “silla blanca”, “silla negra”, “silla roja”, etc. Esta táctica aplicada a la técnica de “Bayes ingenuo” nos acabaría conduciendo inexorablemente a una hipótesis predeterminada. Claro que sería como hacernos trampas al solitario…
[7] El nombre de la hoja es bayes_excel.xlsx, y puede encontrarse en https://bit.ly/2An58uc.
[8] MCLAUGHLIN, J., & PATÉ-CORNELL, M.E. (2005). A Bayesian approach to Iraq’s nuclear program intelligence analysis: a hypothetical illustration. En 2005 International Conference on Intelligence Analysis. https://analysis.mitre.org/proceedings/Final_Papers_Files/85_Camera_Ready_Paper.pdf (acceso: 27.10.2018). También, MCLAUGHLIN, J. (2005). A Bayesian Updating Model for Intelligence Analysis:A Case Study of Iraq’s Nuclear Weapons Program. Honors Program in International Security Studies Center for International Security and Cooperation Stanford University.
[9] Puede accederse a ella en la siguiente dirección: https://bit.ly/30veoY3.
[10] Puede encontrarse en https://bit.ly/3dUsENL.
Fuente: serviciosdeinteligencia.com, 2020
Algoritmos Naive Bayes: Fundamentos e Implementación
¡Conviértete en un maestro de uno de los algoritmos mas usados en clasificación!
Por Víctor Román.
Victor RomanFollowApr 25, 2019 · 13 min read

Introducción: ¿Qué son los modelos Naive Bayes?
En un sentido amplio, los modelos de Naive Bayes son una clase especial de algoritmos de clasificación de Aprendizaje Automatico, o Machine Learning, tal y como nos referiremos de ahora en adelante. Se basan en una técnica de clasificación estadística llamada “teorema de Bayes”.
Estos modelos son llamados algoritmos “Naive”, o “Inocentes” en español. En ellos se asume que las variables predictoras son independientes entre sí. En otras palabras, que la presencia de una cierta característica en un conjunto de datos no está en absoluto relacionada con la presencia de cualquier otra característica.
Proporcionan una manera fácil de construir modelos con un comportamiento muy bueno debido a su simplicidad.
Lo consiguen proporcionando una forma de calcular la probabilidad ‘posterior’ de que ocurra un cierto evento A, dadas algunas probabilidades de eventos ‘anteriores’.

Ejemplo
Presentaremos los conceptos principales del algoritmo Naive Bayes estudiando un ejemplo.
Consideremos el caso de dos compañeros que trabajan en la misma oficina: Alicia y Bruno. Sabemos que:
- Alicia viene a la oficina 3 días a la semana.
- Bruno viene a la oficina 1 día a la semana.
Esta sería nuestra información “anterior”.
Estamos en la oficina y vemos pasar delante de nosotros a alguien muy rápido, tan rápido que no sabemos si es Alicia o Bruno.
Dada la información que tenemos hasta ahora y asumiendo que solo trabajan 4 días a la semana, las probabilidades de que la persona vista sea Alicia o Bruno, son:
- P(Alicia) = 3/4 = 0.75
- P(Bruno) = 1/4 = 0.25
Cuando vimos a la persona pasar, vimos que él o ella llevaba una chaqueta roja. También sabemos lo siguiente:
- Alicia viste de rojo 2 veces a la semana.
- Bruno viste de rojo 3 veces a la semana.
Así que, para cada semana de trabajo, que tiene cinco días, podemos inferir lo siguiente:
- La probabilidad de que Alicia vista de rojo es → P(Rojo|Alicia) = 2/5 = 0.4
- La probabilidad de que Bruno vista de rojo → P(Rojo|Bruno) = 3/5 = 0.6
Entonces, con esta información, ¿a quién vimos pasar? (en forma de probabilidad)
Esta nueva probabilidad será la información ‘posterior’.

Inicialmente conocíamos las probabilidades P(Alicia) y P(Bruno), y después inferíamos las probabilidades de P(rojo|Alicia) y P(rojo|Bruno).
De forma que las probabilidades reales son:

Formalmente, el gráfico previo sería:

Algoritmo Naive Bayes Supervisado
A continuación se listan los pasos que hay que realizar para poder utilizar el algoritmo Naive Bayes en problemas de clasificación como el mostrado en el apartado anterior.
- Convertir el conjunto de datos en una tabla de frecuencias.
- Crear una tabla de probabilidad calculando las correspondientes a que ocurran los diversos eventos.
- La ecuación Naive Bayes se usa para calcular la probabilidad posterior de cada clase.
- La clase con la probabilidad posterior más alta es el resultado de la predicción.
Puntos fuertes y débiles de Naive Bayes
Los puntos fuertes principales son:
- Un manera fácil y rápida de predecir clases, para problemas de clasificación binarios y multiclase.
- En los casos en que sea apropiada una presunción de independencia, el algoritmo se comporta mejor que otros modelos de clasificación, incluso con menos datos de entrenamiento.
- El desacoplamiento de las distribuciones de características condicionales de clase significan que cada distribución puede ser estimada independientemente como si tuviera una sola dimensión. Esto ayuda con problemas derivados de la dimensionalidad y mejora el rendimiento.
Los puntos débiles principales son:
- Aunque son unos clasificadores bastante buenos, los algoritmos Naive Bayes son conocidos por ser pobres estimadores. Por ello, no se deben tomar muy en serio las probabilidades que se obtienen.
- La presunción de independencia Naive muy probablemente no reflejará cómo son los datos en el mundo real.
- Cuando el conjunto de datos de prueba tiene una característica que no ha sido observada en el conjunto de entrenamiento, el modelo le asignará una probabilidad de cero y será inútil realizar predicciones. Uno de los principales métodos para evitar esto, es la técnica de suavizado, siendo la estimación de Laplace una de las más populares.
Proyecto de Implementación: Detector de Spam
Actualmente, una de las aplicaciones principales de Machine Learning es la detección de spam. Casi todos los servicios de email más importantes proporcionan un detector de spam que clasifica el spam automáticamente y lo envía al buzón de “correo no deseado”.
En este proyecto, desarrollaremos un modelo Naive Bayes que clasifica los mensajes SMS como spam o no spam (‘ham’ en el proyecto). Se basará en datos de entrenamiento que le proporcionaremos.
Haciendo una investigación previa, encontramos que, normalmente, en los mensajes de spam se cumple lo siguiente:
- Contienen palabras como: ‘gratis’, ‘gana’, ‘ganador’, ‘dinero’ y ‘premio’.
- Tienden a contener palabras escritas con todas las letras mayúsculas y tienden al uso de muchos signos de exclamación.
Esto es un problema de clasificación binaria supervisada, ya que los mensajes son o ‘Spam’ o ‘No spam’ y alimentaremos un conjunto de datos etiquetado para entrenar el modelo.
Visión general
Realizaremos los siguientes pasos:
- Entender el conjunto de datos
- Procesar los datos
- Introducción al “Bag of Words” (BoW) y la implementación en la libreria Sci-kit Learn
- División del conjunto de datos (Dataset) en los grupos de entrenamiento y pruebas
- Aplicar “Bag of Words” (BoW) para procesar nuestro conjunto de datos
- Implementación de Naive Bayes con Sci-kit Learn
- Evaluación del modelo
- Conclusión
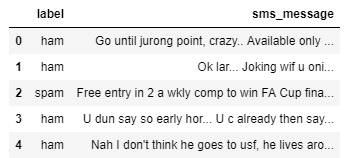
Entender el Conjunto de Datos
Utilizaremos un conjunto de datos del repositorio UCI Machine Learning.
Un primer vistazo a los datos:

Las columnas no se han nombrado, pero como podemos imaginar al leerlas:
- La primera columna determina la clase del mensaje, o ‘spam’ o ‘ham’ (no spam).
- La segunda columna corresponde al contenido del mensaje
Primero importaremos el conjunto de datos y cambiaremos los nombre de las columnas. Haciendo una exploración previa, también vemos que el conjunto de datos está separado. El separador es ‘\t’.
# Importar la libreria Pandas
import pandas as pd# Dataset de https://archive.ics.uci.edu/ml/datasets/SMS+Spam+Collection
df = pd.read_table('smsspamcollection/SMSSpamCollection',
sep='\t',
names=['label','sms_message'])# Visualización de las 5 primeras filas
df.head()
Preprocesamiento de Datos
Ahora, ya que el Sci-kit learn solo maneja valores numéricos como entradas, convertiremos las etiquetas en variables binarias, 0 representará ‘ham’ y 1 representará ‘spam’.
Para representar la conversión:
# Conversion
df['label'] = df.label.map({'ham':0, 'spam':1})# Visualizar las dimensiones de los datos
df.shape()

Introducción a la Implementación “Bag of Words” (BoW) y Sci-kit Learn
Nuestro conjunto de datos es una gran colección de datos en forma de texto (5572 filas). Como nuestro modelos solo aceptará datos numéricos como entrada, deberíamos procesar mensajes de texto. Aquí es donde “Bag of Words“ entra en juego.
“Bag of Words” es un término usado para especificar los problemas que tiene una colección de datos de texto que necesita ser procesada. La idea es tomar un fragmento de texto y contar la frecuencia de las palabras en el mismo.
BoW trata cada palabra independientemente y el orden es irrelevante.
Podemos convertir un conjunto de documentos en una matriz, siendo cada documento una fila y cada palabra (token) una columna, y los valores correspondientes (fila, columna) son la frecuencia de ocurrencia de cada palabra (token) en el documento.
Como ejemplo, si tenemos los siguientes cuatro documentos:
['Hello, how are you!', 'Win money, win from home.', 'Call me now', 'Hello, Call you tomorrow?']
Convertiremos el texto a una matriz de frecuencia de distribución como la siguiente:

Los documentos se numeran en filas, y cada palabra es un nombre de columna, siendo el valor correspondiente la frecuencia de la palabra en el documento.
Usaremos el método contador de vectorización de Sci-kit Learn, que funciona de la siguiente manera:
- Fragmenta y valora la cadena (separa la cadena en palabras individuales) y asigna un ID entero a cada fragmento (palabra).
- Cuenta la ocurrencia de cada uno de los fragmentos (palabras) valorados.
- Automáticamente convierte todas las palabras valoradas en minúsculas para no tratar de forma diferente palabras como “el” y “El”.
- También ignora los signos de puntuación para no tratar de forma distinta palabras seguidas de un signo de puntuación de aquellas que no lo poseen (por ejemplo “¡hola!” y “hola”).
- El tercer parámetro a tener en cuenta es el parámetro
stop_words. Este parámetro se refiere a las palabra más comúnmente usadas en el lenguaje. Incluye palabras como “el”, “uno”, “y”, “soy”, etc. Estableciendo el valor de este parámetro por ejemplo enenglish, “CountVectorizer” automáticamente ignorará todas las palabras (de nuestro texto de entrada) que se encuentran en la lista de “stop words” de idioma inglés..
La implementación en Sci-kit Learn sería la siguiente:
# Definir los documentos
documents = ['Hello, how are you!',
'Win money, win from home.',
'Call me now.',
'Hello, Call hello you tomorrow?']# Importar el contador de vectorizacion e inicializarlo
from sklearn.feature_extraction.text import CountVectorizer
count_vector = CountVectorizer()# Visualizar del objeto'count_vector' que es una instancia de 'CountVectorizer()'
print(count_vector)

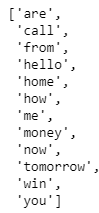
Para ajustar el conjunto de datos del documento al objeto “CountVectorizer” creado, usaremos el método “fit()”, y conseguiremos la lista de palabras que han sido clasificadas como características usando el método “get_feature_names()”. Este método devuelve nuestros nombres de características para este conjunto de datos, que es el conjunto de palabras que componen nuestro vocabulario para “documentos”.
count_vector.fit(documents)
names = count_vector.get_feature_names()
names
A continuación, queremos crear una matriz cuyas filas serán una de cada cuatro documentos, y las columnas serán cada palabra. El valor correspondiente (fila, columna) será la frecuencia de ocurrencia de esa palabra (en la columna) en un documento particular (en la fila).
Podemos hacer esto usando el método “transform()” y pasando como argumento en el conjunto de datos del documento. El método “transform()” devuelve una matriz de enteros, que se puede convertir en tabla de datos usando “toarray()”.
doc_array = count_vector.transform(documents).toarray()
doc_array

Para hacerlo fácil de entender, nuestro paso siguiente es convertir esta tabla en una estructura de datos y nombrar las columnas adecuadamente.
frequency_matrix = pd.DataFrame(data=doc_array, columns=names)
frequency_matrix

Con esto, hemos implementado con éxito un problema de “BoW” o Bag of Words para un conjunto de datos de documentos que hemos creado.
Un problema potencial que puede surgir al usar este método es el hecho de que si nuestro conjunto de datos de texto es extremadamente grande, habrá ciertos valores que son más comunes que otros simplemente debido a la estructura del propio idioma. Así, por ejemplo, palabras como ‘es’, ‘el’, ‘a’, pronombres, construcciones gramaticales, etc. podrían sesgar nuestra matriz y afectar nuestro análisis.
Para mitigar esto, usaremos el parámetro stop_words de la clase CountVectorizer y estableceremos su valor en inglés.
Dividiendo el Conjunto de Datos en Conjuntos de Entrenamiento y Pruebas
Buscamos dividir nuestros datos para que tengan la siguiente forma:
X_trainson nuestros datos de entrenamiento para la columna ‘sms_message’y_trainson nuestros datos de entrenamiento para la columna ‘label’X_testson nuestros datos de prueba para la columna ‘sms_message’y_testson nuestros datos de prueba para la columna ‘label’. Muestra el número de filas que tenemos en nuestros datos de entrenamiento y pruebas
# Dividir los datos en conjunto de entrenamiento y de test
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(df['sms_message'], df['label'], random_state=1)print('Number of rows in the total set: {}'.format(df.shape[0]))print('Number of rows in the training set: {}'.format(X_train.shape[0]))print('Number of rows in the test set: {}'.format(X_test.shape[0]))

Aplicar BoW para Procesar Nuestros Datos de Pruebas
Ahora que hemos dividido los datos, el próximo objetivo es convertir nuestros datos al formato de la matriz buscada. Para realizar esto, utilizaremos CountVectorizer() como hicimos antes. tenemos que considerar dos casos:
- Primero, tenemos que ajustar nuestros datos de entrenamiento (
X_train) enCountVectorizer()y devolver la matriz. - Sgundo, tenemos que transformar nustros datos de pruebas (
X_test) para devolver la matriz.
Hay que tener en cuenta que X_train son los datos de entrenamiento de nuestro modelo para la columna ‘sms_message’ en nuestro conjunto de datos.
X_test son nuestros datos de prueba para la columna ‘sms_message’, y son los datos que utilizaremos (después de transformarlos en una matriz) para realizar predicciones. Compararemos luego esas predicciones con y_test en un paso posterior.
El código para este segmento está dividido en 2 partes. Primero aprendemos un diccionario de vocabulario para los datos de entrenamiento y luego transformamos los datos en una matriz de documentos; segundo, para los datos de prueba, solo transformamos los datos en una matriz de documentos.
# Instantiate the CountVectorizer method
count_vector = CountVectorizer()# Fit the training data and then return the matrix
training_data = count_vector.fit_transform(X_train)# Transform testing data and return the matrix. Note we are not fitting the testing data into the CountVectorizer()
testing_data = count_vector.transform(X_test)
Implementación Naive Bayes con Sci-Kit Learn
Usaremos la implementación Naive Bayes “multinomial”. Este clasificador particular es adecuado para la clasificación de características discretas (como en nuestro caso, contador de palabras para la clasificación de texto), y toma como entrada el contador completo de palabras.
Por otro lado el Naive Bayes gausiano es más adecuado para datos continuos ya que asume que los datos de entrada tienen una distribución de curva de Gauss (normal).
Importaremos el clasificador “MultinomialNB” y ajustaremos los datos de entrenamiento en el clasificador usando fit().
from sklearn.naive_bayes import MultinomialNB
naive_bayes = MultinomialNB()
naive_bayes.fit(training_data, y_train)

Ahora que nuestro algoritmo ha sido entrenado usando el conjunto de datos de entrenamiento, podemos hacer algunas predicciones en los datos de prueba almacenados en ‘testing_data’ usando predict().
predictions = naive_bayes.predict(testing_data)
Una vez realizadas las predicciones el conjunto de pruebas, necesitamos comprobar la exactitud de las mismas.
Evaluación del modelo
Hay varios mecanismos para hacerlo, primero hagamos una breve recapitulación de los criterios y de la matriz de confusión.
- La matriz de confusión es donde se recogen el conjunto de posibilidades entre la clase correcta de un evento, y su predicción.
- Exactitud: mide cómo de a menudo el clasificador realiza la predicción correcta. Es el ratio de número de predicciones correctas contra el número total de predicciones (el número de puntos de datos de prueba).
- Precisión: nos dice la proporción de mensajes que clasificamos como spam. Es el ratio entre positivos “verdaderos” (palabras clasificadas como spam que son realmente spam) y todos los positivos (palabras clasificadas como spam, lo sean realmente o no)
- Recall (sensibilidad): Nos dice la proporción de mensajes que realmente eran spam y que fueron clasificados por nosotros como spam. Es el ratio de positivos “verdaderos” (palabras clasificadas como spam, que son realmente spam) y todas las palabras que fueron realmente spam.
Para los problemas de clasificación que están sesgados en sus distribuciones de clasificación como en nuestro caso. Por ejemplo si tuviéramos 100 mensajes de texto y solo 2 fueron spam y los restantes 98 no lo fueron, la exactitud por si misma no es una buena métrica. Podríamos clasificar 90 mensajes como no spam (incluyendo los 2 que eran spam y los clasificamos como “no spam”, y por tanto falsos negativos) y 10 como spam (los 10 falsos positivos) y todavía conseguir una puntuación de exactitud razonablemente buena.
Para casos como este, la precisión y el recuerdo son bastante adecuados. Estas dos métricas pueden ser combinadas para conseguir la puntuación F1, que es el “peso” medio de las puntuaciones de precisión y recuerdo. Esta puntuación puede ir en el rango de 0 a 1, siendo 1 la mejor puntuación posible F1.
Usaremos las cuatro métricas para estar seguros de que nuestro modelo se comporta correctamente. Para todas estas métricas cuyo rango es de 0 a 1, tener una puntuación lo más cercana posible a 1 es un buen indicador de cómo de bien se está comportando el modelo.
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_scoreprint('Accuracy score: ', format(accuracy_score(y_test, predictions)))print('Precision score: ', format(precision_score(y_test, predictions)))print('Recall score: ', format(recall_score(y_test, predictions)))print('F1 score: ', format(f1_score(y_test, predictions)))

Conclusión
- Una de las mayores ventajas que Naive Bayes tiene sobre otros algoritmos de clasificación es la capacidad de manejo de un número extremadamente grande de características. En nuestro caso, cada palabra es tratada como una característica y hay miles de palabras diferentes.
- También, se comporta bien incluso ante la presencia de características irrelevantes y no es relativamente afectado por ellos.
- La otra ventaja principal es su relativa simplicidad. Naive Bayes funciona bien desde el principio y ajustar sus parámetros es raramente necesario.
- Raramente sobreajusta los datos.
- Otra ventaja importante es que su modelo de entrenamiento y procesos de predicción son muy rápidos teniendo en cuenta la cantidad de datos que puede manejar.
Fuente: medium.com, 2019

Vincúlese a nuestras Redes Sociales:
LinkedIn YouTube Facebook Twitter
.
.
La Inteligencia Estratégica como sistema de gestión de la innovación
mayo 1, 2020
Inteligencia estratégica: un sistema para gestionar la innovación
Por Joao Aguirre.
Resumen
La inteligencia estratégica es un concepto tradicionalmente empleado en contextos militares, de defensa e incluso como «secreto gubernamental», aunque existen tímidas aplicaciones de índole académica y administrativa. El presente artículo realiza una propuesta conceptual del término inteligencia estratégica, generado a partir de la combinación de diferentes herramientas utilizadas actualmente de forma independiente. La investigación parte de un análisis de la literatura con técnicas bibliométricas, identificando líderes, redes de trabajo y dinámicas en publicación, obteniendo como resultado que actualmente la literatura no reporta una definición específica que sea aplicable en contextos gerenciales y administrativos. Finalmente, se propone un proceso para gestionar la inteligencia estratégica organizacional, concebido desde la integración estratégica para garantizar la gestión de la innovación estructurada, el incremento de la productividad y la competitividad.
1. Introducción
De acuerdo con Nelson y Winter (1982) el estudio académico de los fenómenos relacionados con la evolución de la economía son clave en términos de acceso a los mercados, donde se deben contemplar las diferentes variables econométricas, financieras, de tendencias, de mercados y de planeamiento, para generar desarrollo, bienestar y competitividad en economías emergentes, como un mecanismo importante para el fortalecimiento efectivo de las diferentes organizaciones, regiones y sectores de un país. En las últimas décadas el interés científico y profesional en relación con la inteligencia estratégica ha crecido de manera importante (Aguirre, Cataño y Rojas, 2013), dado que tienen estrecha relación con temas como planeamiento estratégico, desempeño, competitividad, innovación y vigilancia tecnológica, entre otros.
En la actualidad no se cuenta con una definición académica para inteligencia estratégica desde el enfoque administrativo, lo cual se debe principalmente a la falta de claridad del concepto y al uso independiente de las diferentes herramientas que tienen relación directa con prácticas de inteligencia estratégica. Dado lo anterior, el objetivo de este artículo se centra en realizar una propuesta conceptual para definir la inteligencia estratégica en el contexto de las ciencias administrativas, que es resultado de la combinación de diferentes herramientas de tratamiento de la información para la toma de decisiones utilizadas actualmente de forma independiente.
Esta propuesta surge a partir del desarrollo de una investigación con rigor académico, combinando metodologías y saberes propios ya conocidos con un enfoque holístico que pueda dar respuesta a diferentes necesidades del sector productivo y empresarial.
La realización detallada de la revisión de la literatura en relación con inteligencia estratégica se hizo a partir de análisis bibliométricos especializados1, lo que permitió identificar un panorama general en términos académicos de la evolución del concepto y la influencia que este tiene en diversas disciplinas que principalmente se caracterizaron por ser de índole económica y administrativa. Asimismo se identificaron trabajos relevantes que permitieron proponer planteamientos de integración en relación con los tópicos de mayor impacto con la inteligencia estratégica.
Para realizar un recorrido de la evolución del tema tratado, se analizaron las publicaciones científicas en las bases de datos ISI y SCOPUS bajo el concepto principal de inteligencia estratégica para el periodo 1994-2012. En este proceso se capturan los datos en áreas relacionadas con economía, gerencia, toma de decisiones, competitividad y conocimiento desde un enfoque administrativo, excluyendo resultados pertenecientes a otras disciplinas; de esta manera se identifican los tópicos de mayor relación para limitar el objeto de estudio de la investigación en áreas de conocimiento propias de las ciencias económicas y administrativas.
Para este estudio se realizó un análisis bibliométrico de las publicaciones, identificando líderes en publicación, redes de trabajo, países con mayor interés investigativo en el tema y artículos con mayor índice de citación, con el fin de utilizar estos resultados como herramienta de identificación de falencias en la literatura, y de esta manera realizar una contribución teórico-conceptual en áreas relacionadas con la gerencia bajo el enfoque de la innovación.
El análisis estratégico de la información requiere ser articulado de forma sistémica para proveer soluciones específicas a las industrias, identificando proyectos de investigación que tengan la potencialidad de convertirse en innovaciones, resaltando principalmente que cada uno de los ejercicios de inteligencia estratégica que se realicen son propios de cada compañía, desarrollados a la medida y la necesidad que se requiera, son únicos y de carácter confidencial. Por tal razón, se considera que la propuesta conceptual hace aportaciones significativas a la comprensión del marco académico, administrativo y gerencial, generando ventajas competitivas en los diferentes agentes que participan en el ecosistema de innovación.
En este sentido, el presente artículo está estructurado en 5 secciones: inicia con la introducción; en la segunda sección se encuentra el marco conceptual donde se expone una revisión de la literatura de los principales elementos relacionados con inteligencia estratégica; la tercera sección describe el proceso metodológico adoptado durante la investigación; en la cuarta sección se analiza la tendencia de las publicaciones científicas en inteligencia estratégica a partir de técnicas de bibliometría para identificar vacíos actuales en la literatura; adicionalmente, se presentan los resultados obtenidos, exponiendo una propuesta conceptual para inteligencia estratégica y se propone un macroproceso para la gestión integral de la inteligencia estratégica brindando un panorama de acción y la relación que existen entre las diferentes herramientas y metodologías para la gestión de la inteligencia estratégica en una organización; para finalizar se presentan las conclusiones obtenidas en la investigación.
2. Marco conceptual
La realización de investigaciones con el rigor académico basado en análisis bibliométrico es cada vez más frecuente, ya que la utilización de metodologías estructuradas en la recopilación de información científica, procesamiento de la misma e identificación de las tendencias en publicaciones, determinan el grado de progreso de las diferentes disciplinas. También el uso de la bibliometría sirve como base para establecer el conocimiento de la fundamentación teórica, su nivel de evolución, e identificar posibles aportes en la construcción de conocimiento.
El concepto de inteligencia estratégica está estrechamente ligado con las estrategias militares; en general, se ha entendido como un conocimiento específico, codificado, secreto y oculto que manejan algunas entidades militares y gubernamentales, concebido como un producto integrado a la seguridad nacional y desarrollo de un país (Garden, 2003, Nelson y Rose, 2012). Este conocimiento específico es requerido para la creación de planes nacionales de defensa, generar planes en operaciones militares y la protección integral de un país, a partir de lo cual se generan planes de prevención ante catástrofes relacionadas con las guerras (Hussain, 2009, Marrin, 2011).
La inteligencia estratégica está influenciada por distintas disciplinas académicas como economía, finanzas, administración e incluso ingeniería. Adicionalmente, existen diferentes herramientas asociadas al concepto, como la vigilancia tecnológica, la inteligencia competitiva, roadmapping tecnológico, prospectiva estratégica e incluso la gestión del conocimiento. Con la finalidad de comprender de forma integral cómo son entendidos estos conceptos, se realiza una aproximación teórica de la fundamentación de estos.
La vigilancia tecnológica tiene un gran número de definiciones abordadas en referentes de la literatura, entre ellos se destacan las propuestas de la Fundación para la innovación tecnológica–COTEC (1999), Palop y Vicente (1999), Rouach y Santi (2001), Asociación Española de Normalización y Certificación–AENOR (2011), Canongia (2007), Sanchez y Medina (2008), Castellanos, Torres, Fonseca y Montañes (2008), Escorsa (2009), Medina y Sanchez (2010), Aguirre et al. (2013), entre otros. De estas definiciones se analizan los factores que presentan en común, donde todas consideran que la vigilancia tecnológica es un proceso estructurado para la obtención, depuración y tratamiento de la información.
Por otro lado, la inteligencia competitiva reporta la mayor cantidad de trabajos académicos en la literatura científica, donde principalmente se caracteriza la posición competitiva de una empresa dependiendo del entorno, analizando variables económicas, financieras, contables, sociales, legales, medioambientales y culturales, que configuran el marco de la competencia, los clientes y proveedores de la cadena de valor y los mercados locales e internacionales. Si bien este concepto se ha explorado desde diferentes perspectivas, con enfoques asociados a variables económicas en diferentes sectores industriales, en la actualidad los trabajos más relevantes presentan un enfoque asociado al planeamiento, la gerencia y el análisis multidisciplinario (Escorsa, 2009, Liebowitz, 2010, Pineda, 2009, Cobb, 2011, Colakoglu, 2011, Ziegler, 2012, Bartes, 2013), donde también se logran identificar estudios de caso relevantes que exponen ventajas, desventajas y aplicabilidad de casos prácticos de la inteligencia competitiva en diferentes contextos (Bitman, 2005, Dishman y Calof, 2008, Du Toit, 2003, Ilie et al., 2009).
De igual forma la prospectiva es considerada una disciplina para el análisis de tendencias futuras, a partir del conocimiento del presente, realizando análisis de escenarios probables a partir de información de tendencias, mercados y entorno social; con ello se facilita el encuentro de la oferta científica y tecnológica con las necesidades actuales y futuras de los mercados y del entorno social (Aguirre et al., 2013). Vale la pena resaltar que en esta dirección se han realizado una gran variedad de estudios en diversas áreas del conocimiento, donde se analizan los factores de riesgo, tendencias, desempeño, estudios comparativos, propuestas de políticas, cuidados y prevenciones, y análisis de tecnologías, entre otros (Kuhlmann, 2003, Barnicki y Siirola, 2004, Castellanos et al., 2008, Hu et al., 2008, Barczak et al., 2009, Gabrielová, 2010, Shih et al., 2010, Lara, 2012, Yoon y Kim, 2012).
Para finalizar, el planeamiento estratégico es un proceso organizado y estructurado mediante el cual se preparan una serie de actividades que impactan directamente en la toma de decisiones de una organización; para lograr esto se procesa y analiza la información interna y externa que sea relevante, apropiada y que demuestre la realidad actual del entorno económico, el cual se desempeña con el fin de realizar un diagnóstico del estado actual de la empresa, identificando el nivel de competitividad con el propósito de anticipar y decidir el futuro de la organización (Ernst, 1998, Ernst y Soll, 2003, Serna Correa y Miranda Miranda, 2003, Coyne y Bell, 2011, Willardson, 2013). En este sentido, el planeamiento estratégico es un método que contiene un proceso de análisis racionalizado del contexto interno y externo en el cual opera la empresa y la elaboración de un diagnóstico de la situación en que se encuentra, a partir de la cual se facilita la fijación de objetivos, estrategias y los medios tácticos para el cumplimiento de la meta, con la finalidad de mejorar el rendimiento competitivo a favor de la empresa (Estrada y Heijs, 2005), teniendo la claridad de identificar los programas, proyectos y planes de acción que se requieren para dar cumplimiento a la estrategia establecida.
A partir de las definiciones previamente concebidas, se identifica la estrecha relación que existe entre estas herramientas y la posibilidad de uso complementario entre sí, dado que cada una de ellas tiene un objeto de trabajo específico que puede ser implementado en la gestión administrativa de una organización.
3. Metodología
En la actualidad, los estudios bibliométricos se utilizan para identificar los avances de los patrones de colaboración y tendencias de los investigadores, e identificar los líderes que durante diferentes periodos de interés han publicado en documentos de rigor académico como libros, artículos de revistas científicas, memorias de eventos internacionales y similares (Aguirre et al., 2013).
La utilización de los resultados bibliométricos puede caracterizar la orientación de una investigación, desempeñando un papel importante y primordial en la clasificación y segmentación de las áreas de interés, a partir de la creación de ecuaciones de búsquedas específicas, que aporten en el hallazgo de los documentos de mayor relevancia. Por otro lado, los datos que se pueden encontrar en algunas ocasiones presentan grandes volúmenes. Para depurar esta información se requiere la implementación de recursos tecnológicos especializados en la minería de datos, los cuales permiten realizar análisis multivariante, filtrado de información relevante y generación de mapas tecnológicos, todos los cuales aportan claridad respecto a la relevancia de la investigación desarrollada.
Para la presente investigación se utilizó un software especializado en búsqueda de información así como el software IHS Goldfire® que tiene la capacidad de realizar búsquedas específicas en la web a partir de criterios de búsqueda con leguaje natural humano2. Para el tratamiento de la información se dispuso del software Vantage Point® para la depuración, filtrado y análisis de los datos, con la finalidad de realizar análisis completos del objeto de estudio.
En primera instancia, en la investigación se realizaron búsquedas específicas asociadas al concepto «inteligencia estratégica» en diferentes publicaciones internacionales indexadas; principalmente se emplearon las publicaciones en las bases de datos ISI y SCOPUS, inicialmente en español, donde sus resultados fueron prácticamente nulos, por lo que se procedió a la búsqueda en inglés del término «strategic intelligence» donde se identificaron publicaciones que presentaran una relación al criterio de búsqueda, sin incluir una escala de tiempo.
Los resultados obtenidos presentaron una variedad elementos que se encontraban fuera del criterio central de la investigación; por tal razón se generaron filtros de búsqueda donde se excluyeron criterios como: artes, medicina, enfermería, farmacia, simulación, algoritmos, entre otros, con la finalidad de obtener artículos centrados principalmente en temas económicos, administrativos y gerenciales. Posteriormente, se analizaron las subáreas que reportaban los artículos y se seleccionaron principalmente las relacionadas con management, engineering, economics finance, decision sciences, entre otras, y se realizó un filtro por tópicos relacionados con el objeto principal del estudio. Luego, se llevó a cabo una depuración manual, a partir de los títulos y resúmenes de las publicaciones encontradas, con el fin de garantizar la obtención de artículos realmente pertinentes. A partir de lo anterior, se obtuvo como resultado una depuración de más del 65% de los artículos hallados en primera instancia, porque pertenecían a otros contextos, o se mencionaban algunos de los tópicos de forma independiente o aislada.
Una vez seleccionada la base de datos específica, acorde con el objeto de estudio y para un periodo enmarcado dentro de los últimos 20 años, se realizó una depuración de los datos con Vantage Point®. Para esto se hizo un análisis de filtración y depuración de autores, redes de trabajo, citaciones, títulos, años y países de publicación, para proceder con la generación de reportes, mapas tecnológicos, redes de trabajo y tendencias.
Para finalizar, se procedió con la identificación de publicaciones que realizaran propuestas para la implementación del concepto de inteligencia estratégica o similares, y se obtuvo como resultado que en la actualidad no se cuenta con ningún artículo que haga una propuesta desde el enfoque administrativo, con implicaciones en modelos de gestión, para incrementar la competitividad y la innovación en una organización. Por esta razón, se propuso una definición conceptual a partir de la revisión detallada de la bibliografía, de la cual surge una propuesta para un proceso de gestión de inteligencia estratégica donde se integran diferentes herramientas aplicables en el contexto académico, en el cual se vinculan los elementos más relevantes obtenidos en la literatura para tener en cuenta en la implementación de inteligencia estratégica, y de esta forma generar un avance en el conocimiento a partir de la rigurosidad que se requiere en aplicaciones gerenciales y directivas, y que puede ser implementada en las organizaciones para incrementar su desempeño innovador.
A partir de esta necesidad identificada, se realiza un análisis de temas que presentan estrecha relación con la inteligencia estratégica bajo el enfoque de la administración y las ciencias económicas, donde se llevan a cabo propuestas conceptuales y gráficas para vigilancia tecnológica, inteligencia competitiva, prospectiva y planeamiento estratégico, y de esta manera generar una propuesta conceptual para inteligencia estratégica en un esquema gráfico que facilita el entendimiento del mismo, teniendo como referente que es aplicable en contextos administrativos. Consecuentemente, se propone la estructura de un macroproceso para otorgar una comprensión general del sistema definiendo cuáles son los procesos claves que se deben realizar y la forma de articular cada uno de ellos dentro del marco de la inteligencia estratégica.
4. Resultados
Con base en la revisión de la literatura realizada, se identifica que existen diferentes interpretaciones teóricas y académicas en relación con la inteligencia estratégica, en donde se resaltan los trabajos de Aguirre et al. (2013), Bartes (2013), Chopin, Irondelle y Malissard (2011), Coyne y Bell (2011), Nasri (2011) y Nikpour, Shahrakipour y Karimzadeh (2013); a partir de lo cual se demuestra que en la actualidad es notoria la carencia de una definición integradora que sea aplicable a la gerencia de las organizaciones.
Dado lo anterior, esta investigación realiza una propuesta conceptual que aborda la inteligencia estratégica como un conjunto integral de elementos de análisis, depuración, filtrado, interpretación, planeamiento, evaluación y gestión de la información a partir de diferentes conceptos consolidados en la literatura. Por esta razón es de vital importancia analizar los tópicos que en la literatura han reportado mayor influencia en la estructuración teórica, para de esta forma poder analizar las perspectivas de estudio y sus posibles impactos en aplicaciones gerenciales y directivas que tengan estrecha relación con el incremento de la competitividad en los sistemas de innovación (Aguirre y Restrepo, 2012, Oquendo y Acevedo, 2012, Palacio, 2011).
Aunque en términos académicos el concepto de inteligencia estratégica ha presentado una evolución creciente en lo referente a publicaciones y presenta una trasformación relacional que está estrechamente ligada con las ciencias administrativas, de gestión y de dirección (Gilad, 2011, Nikpour et al., 2013, Reginato y Gracioli, 2012, Willardson, 2013), en la última década los investigadores se han apropiado del concepto de inteligencia estratégica como una herramienta clave para dirigir compañías o para proponer planes estratégicos de una organización. La evidencia de esto se refleja en la tendencia creciente de publicaciones y desarrollo de proyectos de investigación científica basados en inteligencia estratégica (fig. 1).

La metodología de investigación realizada para identificar la evolución del concepto centra el interés en la búsqueda de referentes académicos a partir de 2003 hasta 20123, filtrando las búsquedas a los tópicos de interés administrativos; de esta manera se logra identificar específicamente el segmento de publicaciones en el tema, obteniendo como resultado 108 publicaciones en español, inglés y francés, lo que demuestra que este es un tópico nuevo de investigación académica. En la figura 2 se identifica la cantidad de palabras clave y su recurrencia en la muestra de artículos seleccionados, donde se logra identificar que los tópicos de interés son acordes con los criterios de búsqueda.

Por otro lado, la figura 3 representa la distribución porcentual de las áreas en las cuales se están adelantando investigaciones en este tópico; vale la pena destacar que en su mayoría están relacionadas con temas administrativos, sociales, negocios, economía, entre otros, ratificando el creciente interés que tienen los investigadores en identificar diferentes herramientas o sistemas de gestión para optimizar el desempeño de las organizaciones. Las búsquedas se realizaron en inglés, principalmente porque el número de publicaciones en español en estos tópicos no es considerable en la muestra.

Para identificar las redes de cooperación en producción científica en el tema en cuestión, se realizó un análisis de los países y su nivel de publicaciones, donde se resalta EE. UU. como el país que presenta mayor número de desarrollos, seguido por Reino Unido y Francia; adicionalmente se encuentra que estos países trabajan en redes colaborativas de investigación, como se evidencia en la figura 4, mientras que se identifican algunos países que lo hacen de forma independiente y su nivel de producción es bajo.

La investigación también permitió identificar las redes de colaboración en la producción académica de los autores (en la figura 5 se exponen las redes de trabajo de los autores que son líderes en investigación en el tema). Dado lo anterior, se resalta que en la actualidad hay pocas publicaciones en el tema, demostrando que esta es una disciplina nueva y emergente, que despierta el interés de la comunidad científica; lo cual se puede visualizar en los notorios esfuerzos por realizar publicaciones conjuntas y su tendencia de crecimiento.

Analizando de manera integral la inteligencia estratégica entendida como una forma de generar, filtrar y organizar la información estructurada para que permita tomar decisiones estratégicas en una organización, se requiere hacer un análisis integral que contemple los estudios del pasado, investigaciones, tendencias, proyectos ya realizados y en general todo lo relacionado con el estado del arte para cada tema particular, aplicando el rigor del caso mediante la implementación de herramientas cienciométricas y recursos tecnológicos propios de la vigilancia tecnológica.
Adicionalmente, se debe hacer un análisis del entorno de la actualidad del mercado, los clientes, sus necesidades, los competidores, los productos complementarios y suplementarios, para lo cual se requiere el rigor de la inteligencia competitiva. De igual forma es pertinente hacer una proyección de estos resultados en el futuro, analizando los diferentes escenarios de acción, ante lo cual cobra importancia la prospectiva; finalmente, toda esta información, del pasado, de la actualidad y del futuro, requiere ser articulada y procesada para la toma de decisiones a partir de un planeamiento estratégico, en el cual se fijen los objetivos claros, los hitos, los recursos necesarios y la forma adecuada que se requiere implementar para la realización de los mismos.
La vigilancia tecnológica es un sistema organizacional, conformado por un conjunto de métodos, herramientas, recursos tecnológicos y humanos, con capacidades altamente diferenciadas para seleccionar, filtrar, procesar, evaluar, almacenar y difundir información del pasado, transformándola en conocimiento para la toma de decisiones estratégicas. De esta manera se concluye que la vigilancia tecnológica es un proceso que analiza la información cronológica del pasado (fig. 6). A su vez la vigilancia tecnológica puede especializarse en diferentes enfoques dependiendo de la necesidad por adquirir información de los diferentes entornos: normativo, económico, comercial, competitivo, sociocultural y ambiental, entre otros.

Adicionalmente, se distinguen diversos tipos de vigilancia tecnológica, entre los que se destacan los siguientes: vigilancia competitiva que se ocupa de la información sobre los competidores actuales y los potenciales (política de inversiones, entrada en nuevas actividades, entre otros), la vigilancia comercial que estudia los datos referentes a clientes y proveedores (evolución de las necesidades de los clientes, solvencia de los clientes, nuevos productos ofrecidos por los proveedores, entre otros), y la vigilancia del entorno que se especializa en la detección de aquellos hechos exteriores que pueden condicionar el futuro, y que se relacionan con áreas como la sociología, la política, el medio ambiente, las reglamentaciones, entre otros.
La inteligencia competitiva es un sistema organizacional de referenciación del estado actual de la compañía, clientes, competidores, proveedores y todos los agentes relacionados en la cadena de valor, identificando variables económicas, sociales, tecnológicas, de mercado, de competencia y laborales, con el fin conocer el entorno dinámico y cambiante de la actualidad (fig. 7).

La inteligencia competitiva es una herramienta que provee información específica para aquellas personas encargadas de tomar decisiones en las compañías, aunque en la actualidad se corre un riesgo inminente, asociado a la saturación de información disponible en la web. De esta forma, para no incurrir en problemas asociados con la «infoxicación»4 se debe recurrir al uso de recursos informáticos y tecnológicos que apoyen la depuración, filtrado y selección de información relevante, teniendo en cuenta que este proceso está asociado a una experticia humana especializada.
La inteligencia competitiva es un componente de importancia para el desarrollo de capacidades, es la que permite identificar y dar alertas tempranas acerca de las tendencias, necesidades y oportunidades tecnológicas para el sector, y adicionalmente suministra información oportuna, veraz y estratégica acerca del desarrollo y evolución de los mercados y negocios. En consecuencia, la información inteligente tendrá la forma de «alertas» sobre cambios importantes en el entorno que tienen implicaciones para la organización y sus planes y programas, o la de «propuestas de decisión» sobre ajustes que deban realizarse a programas, proyectos y metas que se encuentran en ejecución.
El uso de herramientas de prospectiva se ha convertido en un aspecto fundamental para el planeamiento estratégico, para generar visiones compartidas de futuro, orientar políticas de largo plazo y tomar decisiones estratégicas en el presente, dadas las condiciones y las posibilidades locales, nacionales y globales. Además, también se debe comprender como un proceso de análisis de escenarios futuros de la organización, en función del mercado, de los agentes de directa relación, de las metas y del entorno social, con la finalidad de orientar estrategias de largo plazo (fig. 8).

La técnica de construcción de escenarios se utiliza cada vez más para fines de planificación estratégica, ya que proporciona un marco de referencia de alternativas futuras, y es un apoyo para la formulación de políticas y procesos para la toma de decisiones. Sin embargo, a pesar de que la construcción de escenarios no acaba con la incertidumbre, ayuda a perfilar las posibilidades de la evolución de la realidad; es decir, es una visión de las secuencias futuras de hechos o circunstancias en un tiempo predefinido.
En este sentido, la construcción de escenarios permite vislumbrar la interrelación de varias tendencias, para comprobar la consistencia de un conjunto de previsiones que conforman las diferentes posibilidades futuras. Sobre la base de esas descripciones, se puede evaluar la idoneidad de las políticas actuales o alternativas eventuales que forman la planificación de los países y las organizaciones. Por tanto, la prospectiva no es predicción, utopía, ciencia ficción, profecía ni adivinación; es la aplicación de herramientas, técnicas y metodologías para la realización de estudios del futuro, utilizados en la actualidad por organizaciones internacionales en todo el mundo.
Por lo tanto, la planeación estratégica es un proceso estructurado de gestión para el cumplimiento de objetivos estratégicos, enmarcados dentro del futuro deseable de la organización, teniendo claridad en las metas que se desean alcanzar, bajo los diferentes escenarios probables, con la respectiva asignación de recursos, conocimientos, tecnologías y metas a realizar con indicadores medibles para control, avance y cumplimiento de los objetivos fijados (fig. 9).

La planeación estratégica tiene la finalidad de establecer una serie de objetivos y metas que se deben alcanzar en el futuro, los cuales deben ser medibles y alcanzables, y que se puedan evidenciar de forma concreta. El proceso de planeamiento estratégico consiste fundamentalmente en responder las siguientes preguntas: ¿En dónde se está actualmente?, ¿A dónde se debe ir?, ¿A dónde se puede ir?, ¿Cómo se está trabajando para llegar a las metas?, ¿Cuáles son las capacidades diferenciadoras propias?, ¿Cuáles son los riesgos que se deben afrontar para cumplir la visión?, ¿Cuáles son los recursos necesarios?, ¿El personal interno cuenta con las habilidades necesarias para lograr los objetivos?, ¿Se cuenta con un sistema para controlar la evolución de los objetivos?, ¿Se están utilizando las tecnologías adecuadas?, ¿Se cuenta con un sistema de monitorización de tendencias?, ¿Cuáles son los escenarios futuros probables?, ¿Cuál es el nicho de mercado?, ¿Se tiene claro el plan de capacitación?, ¿La estrategia principal se concentra en ser pioneros o imitadores?, ¿Cuál es el porcentaje de ventas destinado a investigación, desarrollo e innovación?, entre otras.
Así, la planeación estratégica tiene los siguientes componentes fundamentales: los estrategas (alta dirección de la empresa, gerentes, juntas directivas, directores, presidentes, etc.), el direccionamiento estratégico (principios corporativos, visión y misión) y el diagnóstico estratégico. De esta manera, se podrá redefinir la estrategia a partir del análisis de tendencias del mercado, propiciando la formulación estratégica y contemplando planes de acción (definición de responsables, área funcional, objetivos específicos y presupuesto estratégico), ejecución de los mismos y la auditoria estratégica con evaluación y medición periódicas (Dishman y Calof, 2008, Erickson y Rothberg, 2010, Gutiérrez, 2012).
El planeamiento estratégico asume que una organización debe responder a un entorno que es dinámico, cambiante y difícil de predecir, que tiene asociados inminentes riesgos que pueden ser controlables y no controlables. De esta forma se hace hincapié en la importancia de tomar decisiones para responder con éxito a los cambios en el entorno, incluidos los cambios de los competidores y colaboradores. La planificación estratégica es la gestión estratégica, es decir, la aplicación del pensamiento estratégico a la tarea de dirigir una organización para el logro de su propósito (Erickson y Rothberg, 2010).
Dadas las anteriores consideraciones, la inteligencia estratégica se concibe como un sistema organizacional holístico que permite gestionar la innovación a partir del planeamiento estratégico de las organizaciones basado en información del pasado, presente y futuro, empleando la vigilancia tecnológica, inteligencia competitiva y prospectiva, aplicando un conjunto de métodos, herramientas y recursos tecnológicos, con capacidades altamente diferenciadas para seleccionar, filtrar, procesar, evaluar, almacenar y difundir información, transformándola en conocimiento útil para la toma de decisiones estratégicas en un entorno dinámico y cambiante (fig. 10).

En la figura 11 se presenta una propuesta gráfica para el modelo conceptual planteado, en la cual se puede identificar de forma visual la integración y vinculación de las diferentes perspectivas empleadas; de esta forma se permite generar una comprensión integral de la inteligencia estratégica. La propuesta de inteligencia estratégica es concebida como un análisis integral, que contempla estudios del pasado, presente y futuro, transformando información en conocimiento útil para la toma de decisiones, a partir del análisis de líderes a nivel mundial, redes de cooperación, instituciones pioneras en publicación, tendencias de los mercados, de consumo, identificando potenciales socios o aliados estratégicos, a partir de un plan estratégico, en el cual se brinda la posibilidad de planificar y formular estrategias tecnológicas, minimizando la incertidumbre, con la finalidad de gestionar exitosamente proyectos de innovación y el fortalecimiento de las organizaciones.

De esta forma, teniendo identificadas las ventajas competitivas de las organizaciones, basadas en el planeamiento estratégico, se genera un efecto dinamizador entre los distintos agentes e instituciones que intervienen en el sistema de innovación. Por tal razón, se propone un proceso metodológico para la inteligencia estratégica, el cual consta de 4 pilares fundamentales, que son: diagnóstico actual, diseño de estrategias, implementación de las mismas, y por último, seguimiento y control de las diferentes acciones a realizar.
En el diagnóstico inicial se deben analizar e identificar los diferentes activos estratégicos que posee el sistema (organizacional, regional o sectorial), a nivel de recursos humanos, recursos físicos, tangibles e intangibles y conocimientos que se dominen; de esta manera se pueden identificar las tecnologías que se poseen y a su vez las capacidades de innovación (Aguirre y Robledo, 2010) (fig. 12). Estas a su vez permiten la cuantificación de los factores clave de éxito y las barreras de entrada, los cuales marcan las ventajas competitivas que posee el sistema en términos de clientes, proveedores, procesos y análisis financiero. Con estos elementos se realiza un análisis de la industria o sector, mediante la aplicación de vigilancia tecnológica e inteligencia competitiva, para obtener la información de los líderes en la comercialización, producción y nivel de desarrollo tecnológico, se identifican las brechas de competitividad y los referentes que marcan la pauta en la tecnología.

El diseño de la estrategia se realiza a partir de la identificación de elementos internos de la organización como son sus valores, la misión, la visión y el análisis FODA (fortalezas, oportunidades, debilidades y amenazas), enmarcándolos bajo la fijación de objetivos estratégicos que deben estar alineados con los planes nacionales de desarrollo; ya que esta articulación facilita el acceso de recursos gubernamentales y también se deben incluir los ejes prioritarios de trabajo que posee la organización, los cuales están fundamentados en el diagnóstico de las capacidades de innovación propios del sistema. Con estos elementos se realiza un proceso de prospectiva para identificar las tendencias y los diferentes escenarios. Este desarrollo requiere la vinculación con expertos en el tema, tanto del sector académico como productivo (fig. 13).

Con estos insumos se procede a la formulación de las diferentes estrategias que se deberán realizar contemplando la estrategia global, corporativa, de negocios, funciones, crecimiento, articulación, impacto, comunicación, bajo los contextos internos y externos que posea el sistema.
Para la implementación de la estrategia se requiere hacer un previo plan de acción, fijando actividades, responsables, objetivos, fechas de cumplimiento, enmarcados dentro de los diferentes proyectos que se realizarán, especificando por escrito cuál es el portafolio de proyectos que se llevarán a cabo, y estos a su vez requieren de una identificación y priorización de los proyectos de mayor importancia según la estrategia. Para ellos es preferible hacer una estructura de jerarquización en donde se definan cuáles serán los elementos claves que tienen mayor incidencia sobre la estrategia (fig. 14). Posteriormente, se requiere de la implementación y comercialización de cada una de las actividades indicadas en el plan estratégico propuesto. Vale la pena aclarar que algunos proyectos que son de carácter interno no requieren comercialización, por lo tanto se deben interpretar como la apropiación de los mismos dentro del sistema.

Por último, se necesita un seguimiento y control riguroso, en el cual se tengan establecidos los indicadores de seguimiento, los cuales deben ser preferiblemente cuantitativos y medibles, que contemplen integralmente los diferentes aspectos del plan estratégico, como los indicadores financieros, de eficiencia, aprendizaje (conocimiento) e innovación (productos o servicios que lleguen al mercado exitosamente). Adicionalmente, se requiere una matriz de evolución en el que se registren los avances obtenidos en la implementación y se dé cuenta del estado actual, para tomar decisiones correctivas o de mejora en los aspectos que no se logren cumplir satisfactoriamente (fig. 15).

En la figura 16 se presenta la propuesta de un macroproceso integral, en el cual se desagregan los diferentes procedimientos a realizar en cada uno de los pilares antes mencionados. Se expone la articulación y la forma de relación entre cada uno de ellos, analizando la articulación que se requiere para dinamizar el sistema y maximizando la efectividad del mismo. La articulación estructurada de forma sistémica que se presenta en cada uno de los procesos, y la relación entre las diferentes actividades proponen una ruta clara para incentivar la gestión de la innovación en una organización, vinculando diferentes elementos para ser tenidos en cuenta en la dirección o gerencia de una organización. De esta forma, como afirman Vargas y Guillen (2004), los procesos de transformación estratégica tienen una estrecha relación con la evolución de las organizaciones a partir de la generación de innovación.

5. Conclusiones
Como resultados de la presente investigación se destaca la propuesta teórico-conceptual en relación con la inteligencia estratégica, creada a partir de los resultados obtenidos en el análisis biométrico realizado, empleando técnicas y software de vigilancia tecnológica, en el contexto de las ciencias económicas y administrativas. De esta forma, se identificaron vacíos en la literatura, lo cual brindó la oportunidad de hacer aportaciones en la generación de conocimiento en esta rama específica.
Se realizó una propuesta conceptual y gráfica que integra los elementos con mayor relación y aplicación para la inteligencia estratégica, brindando un nuevo enfoque de análisis para la gestión estratégica de las ciencias económicas y administrativas. Adicionalmente, se propone una estructura de macroprocesos que permite brindar claridad para la gestión y comprensión de la inteligencia estratégica, así como su implementación en cualquier tipo de organización, ya que todas requieren información actualizada y pertinente para la toma de decisiones estratégicas.
La evolución del contexto empresarial asociado a la gestión de la innovación presiona a las organizaciones hacia la formulación de estrategias específicas que incrementen la competitividad bajo un contexto de innovación, porque en la actualidad se evidencian cambios dinámicos en los diferentes mercados, que están siendo impulsados por el desarrollo de nuevos desarrollos.
Gestionar la innovación en una organización requiere de un proceso estructurado y sistémico, donde la inteligencia estratégica aporta directamente en esta dirección, dadas las condiciones de análisis del pasado, presente y futuro que se requieren para identificar los nuevos productos o servicios que tienen posibilidad de ser una innovación. A partir de lo anterior, se evidencia un aporte interesante en el planteamiento del proceso para gestionar la inteligencia estratégica, donde se convierte en un catalizador y una herramienta apropiada para el crecimiento del desempeño de las organizaciones.
El análisis de tendencias en publicaciones científicas relacionadas con inteligencia estratégica permitió conocer el entorno actual y el nivel de vinculación de este concepto con las ciencias administrativas, aunque se destaca que en español no se reporta ningún trabajo en bases de datos indexadas; pero al realizar el mismo análisis en inglés, se puede ver que es un concepto que se encuentra en crecimiento, despertando el interés de la comunidad académica, mediante la integración de diferentes herramientas de apoyo en la gestión empresarial.
Se resalta que los resultados de la presente investigación son un aporte significativo para la literatura en estos tópicos, ya que propone un sistema integrador que permite gestionar la innovación de forma estratégica, otorgando un enfoque que puede ser aplicado para una organización, empresa o clúster empresarial, todos los cuales son elementos que se requieren para fortalecer el sistema nacional, regional y sectorial de innovación.
Conflicto de intereses
El autor declara no tener ningún conflicto de intereses.
Agradecimientos
Los resultados de investigación presentados en este artículo forman parte del estudio doctoral que está realizando el autor, de esta forma se agradece al doctor Jorge Robledo sus valiosos aportes y a la Universidad Nacional de Colombia.
Bibliografía
Aguirre et al., 2013J. Aguirre, G. Cataño, M.D. RojasAnálisis prospectivo de oportunidades de negocios basados en vigilancia tecnológicaRevista Puente, 7 (1) (2013), pp. 29-39View Record in ScopusGoogle Scholar
Aguirre y Restrepo, 2012 Aguirre, J. y Restrepo, M. (2012). Scientific Research Analysis of Sectoral Innovation Systems. En: Proceedings of PICMET ‘12: Technology Management for Emerging Technologies (PICMET 2012). Vancouver, Brtitish Columbia, Canada 29 July−2 August 2012; p. 1904-1909.Google Scholar
Aguirre y Robledo, 2010 J. Aguirre, J. RobledoEvaluación de capacidades de innovación tecnológica en la industria colombiana de software utilizando lógica difusaGestión de las capacidades de innovación tecnológica para la competitividad de las empresas antioqueñas de software, Todográficas Ltda, Medellín (2010), pp. 95-210View Record in ScopusGoogle Scholar
AENOR, 2011 Asociación Española de Normalización y Certificación–AENORNorma UNE 166.006:2011 Gestión de la I+D+i: Sistema de Vigilancia TecnológicaEspaña, Madrid (2011)Google Scholar
Barczak et al., 2009 G. Barczak, A. Griffin, K.B. KahnPerspective: Trends and drivers of success in NPD practices: Results of the 2003 PDMA Best Practices StudyJournal of Product Innovation Management, 26 (1) (2009), pp. 3-23CrossRefView Record in ScopusGoogle Scholar
Barnicki y Siirola, 2004 S.D. Barnicki, J.J. SiirolaProcess synthesis prospectiveComputers & Chemical Engineering, 28 (4) (2004), pp. 441-446ArticleDownload PDFView Record in ScopusGoogle Scholar
Bartes, 2013 F. BartesFive-phase model of the intelligence cycle of competitive intelligenceActa Universitatis Agriculturae et Silviculturae Mendelianae Brunensis, 61 (2) (2013), pp. 283-288CrossRefView Record in ScopusGoogle Scholar
Bitman, 2005 Bitman, W.R. (2005). RyD portfolio management framework for sustained competitive advantage 2, 775-779. Presentado en Engineering Management Conference, 2005. Proceedings. 2005 IEEE International.Google Scholar
Canongia, 2007 C. CanongiaSynergy between competitive intelligence (CI), knowledge management (KM) and technological foresight (TF) as a strategic model of prospecting — The use of biotechnology in the development of drugs against breast cancerBiotechnology Advances, 25 (1) (2007), pp. 57-74ArticleDownload PDFView Record in ScopusGoogle Scholar
Castellanos et al., 2008 O. Castellanos, L. Torres, S. Fonseca, V. MontañesEstudios de vigilancia tecnológica aplicados a cadenas productivas del sector agropecuario colombiano: agendas prospectivasGiro Editores Ltda, Bogotá (2008)Google Scholar
Chopin et al., 2011 O. Chopin, B. Irondelle, A. MalissardStudying intelligence: A French perspectiveÉtudier le renseignement en France (140) (2011), pp. 91-102CrossRefView Record in ScopusGoogle Scholar
Cobb, 2011 A. CobbIntelligence adaptation: The bin laden raid and its consequences for us strategyRUSI Journal, 156 (4) (2011), pp. 54-62CrossRefView Record in ScopusGoogle Scholar
Colakoglu, 2011 T. ColakogluThe problematic of competitive intelligence: How to evaluatey develop competitive intelligence?Procedia-Social and Behavioral Sciences, 24 (2011), pp. 1615-1623ArticleDownload PDFView Record in ScopusGoogle Scholar
Coyne y Bell, 2011 J.W. Coyne, P. BellThe role of strategic intelligence in anticipating transnational organised crime: A literary reviewInternational Journal of Law, Crime and Justice, 39 (1) (2011), pp. 60-78ArticleDownload PDFView Record in ScopusGoogle Scholar
Dishman y Calof, 2008 P.L. Dishman, J.L. CalofCompetitive intelligence: A multiphasic precedent to marketing strategyEuropean Journal of Marketing, 42 (7–8) (2008), pp. 766-785CrossRefView Record in ScopusGoogle Scholar
Du Toit, 2003 A.S.A. Du ToitCompetitive intelligence in the knowledge economy: What is in it for South African manufacturing enterprises?International Journal of Information Management, 23 (2) (2003), pp. 111-120ArticleDownload PDFView Record in ScopusGoogle Scholar
Erickson y Rothberg, 2010 S. Erickson, H. RothbergStrategic knowledge management in a low riskeEnvironmentProceedings of the European Conference on Knowledge Management, ECKM (2010), pp. 369-374View Record in ScopusGoogle Scholar
Ernst, 1998 H. ErnstPatent portfolios for strategic RyD planningJournal of Engineering and Technology Management, 15 (4) (1998), pp. 279-308ArticleDownload PDFView Record in ScopusGoogle Scholar
Ernst y Soll, 2003 H. Ernst, J.H. SollAn integrated portfolio approach to support market-oriented RyD planningInternational Journal of Technology Management, 26 (5/6) (2003), pp. 540-560CrossRefView Record in ScopusGoogle Scholar
Escorsa, 2009 P. EscorsaLa Inteligencia competitiva: factor clave para la toma de decisiones estratégicas en las organizacionesFundación Madri+d, Madrid (2009)Google Scholar
Estrada y Heijs, 2005 S. Estrada, J. Heijs Comportamiento innovador y competitividad: factores explicativos de la conducta exportadora en México. El caso de GuanajuatoProblemas del Desarrollo, 36 (143 [recuperado 14 Jun 2013]) (2005)Recuperado a partir de: http://ojs.unam.mx/index.php/pde/article/view/7599Google Scholar
COTEC, 1999 Fundación para la innovación tecnológica–COTEC Vigilancia tecnológica. Documentos COTEC sobre oportunidades tecnológicasFundación española para la innovación COTEC, Madrid (1999)Google Scholar
Gabrielová, 2010 H. Gabrielová New trends in European industrial policy Ekonomicky Casopis, 58 (9) (2010), pp. 888-908View Record in ScopusGoogle Scholar
Garden, 2003 T. GardenIraq: The military campaignInternational Affaires, 79 (4) (2003), pp. 701-718CrossRefGoogle Scholar
Gilad, 2011 B. GiladStrategy without intelligence, intelligence without strategyBusiness Strategy Series, 12 (1) (2011), pp. 4-11CrossRefView Record in ScopusGoogle Scholar
Gutiérrez, 2012 J.A. GutiérrezRedefinición y tendencias del concepto de estrategia para el gerente colombianoEstudios Gerenciales, 28 (122) (2012), pp. 153-167CrossRefView Record in ScopusGoogle Scholar
Hu et al., 2008 M.Y. Hu, S. Maroo, L. Kyne, J. Cloud, S. Tummala, K. Katchar, et al.A prospective study of risk factors and historical trends in metronidazole failure for Clostridium difficile infectionClinical Gastroenterology and Hepatology, 6 (12) (2008), pp. 1354-1360ArticleDownload PDFView Record in ScopusGoogle Scholar
Hussain, 2009 I. HussainPost-9/11 Canada-US security integration: Of the butcher, the baker, and the intelligence-policy MakerAmerican Review of Canadian Studies, 39 (1) (2009), pp. 38-51CrossRefView Record in ScopusGoogle ScholarIlie et al., 2009A.G. Ilie, D. Dumitriu, R. Sarbu, O.A. ColibasanuBusiness intelligence – A successful approach to creating performance management system. Case study: Application and prospect of business intelligence in metallurgical enterprises in RomaniaMetalurgia International, 14 (Special issue 4) (2009), pp. 40-45View Record in ScopusGoogle Scholar
Kuhlmann, 2003S. KuhlmannEvaluation of research and innovation policies: A discussion of trends with examples from GermanyInternational Journal of Technology Management, 26 (2–4) (2003), pp. 131-149CrossRefView Record in ScopusGoogle Scholar
Lara, 2012J. LaraProspective and retrospective processing in associative mediated primingJournal of Memory and Language, 66 (1) (2012), pp. 52-67View Record in ScopusGoogle Scholar
Liebowitz, 2010J. LiebowitzStrategic intelligence, social networking, and knowledge retentionComputer, 43 (2) (2010), pp. 87-89CrossRefView Record in ScopusGoogle Scholar
Marrin, 2011S. MarrinThe 9/11 terrorist attacks: A failure of policy not strategic intelligence analysisIntelligence and National Security, 26 (2–3) (2011), pp. 182-202CrossRefView Record in ScopusGoogle Scholar
Medina y Sanchez, 2010J. Medina, J.M. SanchezSinergia entre la prospectiva tecnológica y la vigilancia tecnológica y la inteligencia competitivaGiro Editores, Bogotá (2010)Google Scholar
Nasri, 2011W. NasriCompetitive intelligence in Tunisian companiesJournal of Enterprise Information Management, 24 (1) (2011), pp. 53-67CrossRefView Record in ScopusGoogle Scholar
Nelson y Rose, 2012C.M. Nelson, E.P.F. RoseThe US geological survey’s military geology unit in World War II: «The Army’s pet prophets»Quarterly Journal of Engineering Geology and Hydrogeology, 45 (3) (2012), pp. 349-367CrossRefView Record in ScopusGoogle Scholar
Nelson y Winter, 1982R.R. Nelson, S.G. WinterAn evolutionary theory of economic changeBelknap Press f Harvard University Press, Cambridge (1982)Google Scholar
Nikpour et al., 2013B.Z. Nikpour, H. Shahrakipour, S. KarimzadehRelationships between cultural intelligence and academic members’ effectiveness in Roudehen UniversityLife Science Journal (2013), pp. 1-7View Record in ScopusGoogle Scholar
Oquendo y Acevedo, 2012A. Oquendo, C. AcevedoEl sistema de innovación colombiano: fundamentos, dinámicas y avataresRevista Trilogía (6) (2012), pp. 105-120Google Scholar
Palacio, 2011M. PalacioLa construcción de la sociedad del conocimiento y las políticas públicas de apropiación social de la ciencia, la tecnología y la innovaciónRevista Trilogía (5) (2011), pp. 5-39Google Scholar
Palop y Vicente, 1999F. Palop, J. VicenteVigilancia tecnológica e inteligencia competitiva: su potencial para la empresa españolaCOTEC, Madrid (1999)Google Scholar
Pineda, 2009Pineda, L. (2009). Componentes de los sistemas de inteligencia competitiva y vigilancia tecnológica en cadenas productivas. Documento de Investigación, 56, Universidad del Rosario. Recuperado el 7 de septiembre del 2012 de: http://repository.urosario.edu.co/bitstream/10336/3788/1/01248219-2009-56.pdfGoogle Scholar
Reginato y Gracioli, 2012C.E.R. Reginato, O.D. GracioliStrategic management of information through the use of competitive intelligence and knowledge management – A study applied to the furniture industry in Rio Grande do SulBrazil, 19 (4) (2012), pp. 705-716CrossRefView Record in ScopusGoogle Scholar
Rouach y Santi, 2001 D. Rouach, P. SantiCompetitive intelligence adds value: Five intelligence attitudesEuropean Management Journal, 19 (5) (2001), pp. 552-559ArticleDownload PDFView Record in ScopusGoogle Scholar
Sanchez y Medina, 2008 Sanchez, J.M. y Medina, J. (2008). Apoyo en la definición de políticas públicas en ciencia, tecnología e innovación a través de vigilancia tecnológica e inteligencia competitiva. En: Estudios de vigilancia tecnológica aplicados a cadenas productivas del sector agropecuario colombiano. Recuperado el 15 de mayo del 2013 de: http://www.bdigital.unal.edu.co/2082/1/EstudiosVigilanciaJun18.pdfGoogle Scholar
Serna Correa y Miranda Miranda, 2003G. Serna Correa, J. Miranda MirandaExperiencias de planeación organizacional en centros y grupos de investigaciónEstudios Gerenciales (89) (2003), pp. 73-94Google Scholar
Shih et al., 2010M.J. Shih, D.R. Liu, M.L. HsuDiscovering competitive intelligence by mining changes in patent trendsExpert Systems with Applications, 37 (4) (2010), pp. 2882-2890ArticleDownload PDFView Record in ScopusGoogle Scholar
Vargas y Guillen, 2004J. Vargas, I. GuillenLos procesos de transformación estratégica en relación con la evolución de las organizacionesEstudios Gerenciales (94) (2004), pp. 65-80CrossRefView Record in ScopusGoogle Scholar
Willardson, 2013S. WillardsonStrategic intelligence during coin detention operations – Relational data and understanding latent terror networksDefense and Security Analysis, 29 (1) (2013), pp. 42-53CrossRefView Record in ScopusGoogle Scholar
Yoon y Kim, 2012J. Yoon, K. KimTrend Perceptor: A property–function based technology intelligence system for identifying technology trends from patentsExpert Systems with Applications (2012)Google Scholar
Ziegler, 2012C.N. ZieglerMining for strategic competitive intelligence: Foundations and applications, 406, Springer-Verlag, Berlin (2012)1
Aplicación de metodologías de vigilancia tecnológica en contextos académicos mediante la utilización de software especializado para la realización de búsqueda, depuración y filtrado de información.2
Este tipo de búsquedas permite emplear el lenguaje natural del ser humano, donde es posible utilizar expresiones comunes, y el software tiene la capacidad de hacer abstracciones y proponer soluciones que concuerden con la semántica de lenguaje.3
No se incluyen publicaciones de 2013, dado que era el año en curso en el momento de elaboración del presente artículo.4
Trastorno intelectual producto de la incapacidad de analizar y comprender una lluvia de información como la que pueden proporcionar los actuales medios electrónicos. View Abstract Copyright © 2013 Universidad ICESI. Published by Elsevier España S.L.
Fuente: sciencedirect.com, 2013.

_________________________________________________________________

.
.
El Tablero de Control en una estrategia de marketing
mayo 1, 2020
El Dashboard en una estrategia de marketing
Por Tristán Elósegui.
[En este artículo se analiza el caso de uso de Dashboards en marketing, esto puede generalizarse a muchas otras áreas en empresas y organizaciones.]
Al hablar de Dashboards o Tableros de Control, inmediatamente pensamos en Analítica digital. Es inevitable, pensamos en datos, Google Analytics,… y si eres un poco más técnico, piensas en etiquetados, Google Tag Manager (GTM), integración de fuentes, Google Data Studio, etc.
Pero en realidad, pienso que deberíamos darle la vuelta al enfoque. Por definición, la Analítica digital es una herramienta de negocio. Representa los ojos y oídos de la estrategia de marketing, y por tanto se debe definir desde el negocio y no desde el departamento de Analítica (con su ayuda, pero no liderado por ellos).
Para explicarlo, os dejo una resumen de mí ponencia en el primer congreso de marketing digital celebrado en Pontevedra (Congreso Flúor).

Para definir correctamente un dashboard, debemos partir de la estrategia de marketing y seleccionar las fuentes de datos y métricas que mejor la representen. Las que mejor nos describan el contexto de nuestra actividad de marketing, y nos permitan tomar las mejores decisiones.
Para entender el papel de un dashboard en una estrategia vamos a ver cinco puntos:
- ¿Qué es un dashboard?
- ¿Cómo se define un cuadro de mando?
- Caso práctico real.
- Consejos para aportar valor con un dashboard de marketing.
- Ejemplos de dashboard.
Pero, empecemos la historia por el principio.
¿Qué es un dashboard?
Me gusta enfocar la definición de dashboard, de dos maneras, mejor dicho de una manera que concluye en la clave de todo:
Es una representación gráfica de las principales métricas de negocio (KPI), y su objetivo es propiciar la toma de decisiones para optimizar la estrategia de la empresa.
Un dashboard de indicadores debe transformar los datos en información y estos en conocimiento para el negocio.
[Obsérvese la similitud con la definición de Inteligencia.]
Esta transformación de los datos nos debe llevar a una mejor Toma de decisiones. Este es el objetivo principal que no debemos perder de vista. Algo que suele pasar con cierta frecuencia en este proceso. Nos centramos tanto en el proceso de creación del Tablero de Control, que tendemos a olvidar que su objetivo es la toma de decisiones y no la acumulación de datos. Pero esta es otra historia.
A todo esto tenemos que añadir un elemento más, ya que la base para la toma de decisiones está en un buen análisis de los datos.
[No debe confundirse el concepto de Tablero de Control (Dashboard) con el de Cuadro de Mando Integral (Balanced Scorecard).]
¿Qué necesitamos para hacer un buen análisis de un dashboard de control?
Pues fundamentalmente dos cosas:
- Visión estratégica de negocio.
- Pilares del análisis de datos.
Visión estratégica de negocio:
- Correcta definición de los objetivos de marketing y de negocio: es lo que nos va a marcar el camino a seguir, lo que va a definir el éxito de nuestro marketing.
- Definición de la macro y micro conversiones: debemos traducir nuestras metas a hechos objetivos medibles en nuestra web, y además ser capaces de asignarlos a cada una de las etapas del proceso de compra de nuestra audiencia.
- Conocer el contexto: en nuestros resultados incluyen muchas variables: mercado, competencia, regulaciones, etc. En ocasiones son tantas, que dejamos de mirar. Pero un buen punto de arranque para entender los porqués de gran parte de las variaciones en los datos, está en la estrategia de marketing y sus acciones planificadas.
Pilares del análisis de datos:
- Personal cualificado: debemos ser capaces de vencer la tentación de pensar que una herramienta de medición nos va a solucionar el problema. La clave del buen análisis está en las personas que lo realizan. Son las que realizan la transformación de los datos en información y esta en conocimiento para la empresa.
Para tenerlo claras las proporciones, se estima que de cada 100 € invertidos en medición, 90 deben ir a personas y 10 a herramientas. - Calidad del dato: nos tenemos que asegurar de que lo datos que estamos analizando se acercan lo máximo a la realidad. Digo lo máximo, porque es normal que en algunas métricas veamos variaciones entre los datos que nos da la herramienta de analítica y los sistemas internos.
Además de tener la tranquilidad de que estamos usando los datos correctos para tomar decisiones, vamos a eliminar las discusiones internas sobre cuál es el dato real y cual no. - Tablero de Control (Dashboard):
- Definición: selección de KPIs y métricas.
- Implementación técnica: configuración de la herramienta de medición, y etiquetado (web y acciones).
- Integración de fuentes en herramienta de cuadro de mandos.
- Definición de la visualización más adecuada.
- Informes y herramientas de análisis adicionales: necesarios para complementar los diferentes niveles de análisis necesarios.
Para realizar un análisis correcto de un dashboard debemos ir de lo global a los específico
El dashboard de métricas debe contar una historia. Nos debe enseñar el camino desde los principales indicadores, a la explicación de la variación del dato.
Además este cuadro de mando no debe contar con más de 10 KPIs (aproximadamente), primero porque no debería haber más y segundo, porque nos complicamos el análisis.
- Objetivos y KPIs de la estrategia.
- Métricas contextuales.
- Fuentes de datos que necesitaremos para componer el dashboard.
- Siguiente paso: seleccionar el tipo de dashboard más adecuado.
Y por último, aconsejo que el Tablero de Control sea una foto fija de la realidad. Existen herramientas de dashboard que permiten profundizar en el análisis y cruzar variables, pero las desaconsejo (al menos en una primera fase). ¿por qué? El tener estas posibilidades nos llevará a invertir tiempo en darle vueltas a los datos, y nos alejará de la toma de decisiones (objetivo principal de todo cuadro de mando).
Un buen dashboard comercial o de marketing es como un semáforo: Nos muestra las luces rojas, amarillas y verdes de nuestra actividad y las decisiones a tomar .

¿Cómo se define un Tablero de Control de marketing?
Para hacerlo debemos partir del planteamiento de nuestra estrategia (ya que es lo que queremos controlar). Cómo ya adelantaba al hablar de las claves de un buen análisis, tenemos que tener muy claros varios puntos:
- Objetivos por etapa del embudo de conversión (purchase funnel).
- Macro y microconversiones: traducción de estos objetivos a métricas que podamos medir en nuestra página web.
- Métricas de contexto, que nos ayudan a entender la aportación de los medios pagados, propios y ganados a la consecución de los objetivos de cada etapa del embudo de marketing.
La imagen que os dejo a continuación, os ayudará a estructurar mejor la información y sobre todo a no olvidar métricas importantes.
Definición de macro y micro conversiones – Tristán Elósegui
.
¿Qué tenemos hasta el momento?
- Objetivos y KPIs de la estrategia.
- Métricas contextuales.
- Fuentes de datos que necesitaremos para componer el dashboard.
- Siguiente paso: seleccionar el tipo de dashboard más adecuado.
Con esta información ya podemos hacer la selección de las métricas y definir nuestro dashboard de indicadores en formato borrador.
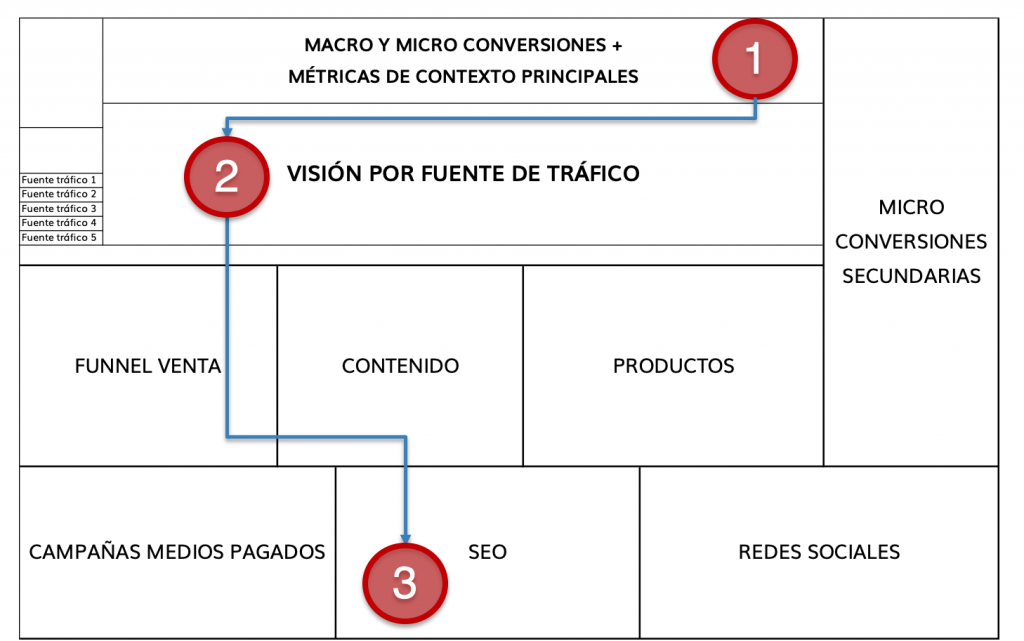
Borrador Dashboard de marketing – Tristán Elósegui
.
Cómo veis en este ejemplo de dashboard, podemos hacer un seguimiento desde el origen de la variación en las KPI principales, hasta el canal o campaña que las causó. Es decir, hemos definido un cuadro de mando que nos cuenta la “historia” de lo que ha ocurrido en el periodo analizado.
Caso práctico real (PCcomponentes.com):
El proceso real es algo más complejo, pero voy a simplificarlo para facilitar la lectura y comprensión.
NOTA: No tengo relación alguna con PCcomponentes.com, por lo que todo lo que vais a ver a continuación son supuestos que realizo para poder explicaros la definición de un Dashboard de indicadores.
Siguiendo la metodología que os acabo de explicar tendríamos que definir:
- Objetivos: para definir el cuadro de mando vamos a partir de una serie de objetivos por etapa que me he inventado.
- Macro y microconversiones: para definirlas para este ejemplo, vamos a hacerlo por medio de un análisis de las llamadas a la acción de la web. Una vez detectadas las más importantes, vamos a ordenarlas por etapa (normalmente lo haríamos analizando que llamadas a la acción han intervenido en las conversiones obtenidas, pero obviamente no tengo acceso de los datos).
- Representación de estas métricas en nuestro borrador de dashboard de métricas.
A continuación os dejo: el pantallazo de una página de producto, la definición de macro y microconversiones y el borrador de dashboard de control.

PCcomponentes página producto
.

Caso real PCcomponentes – Objetivos y métricas para Dashboard de marketing
.
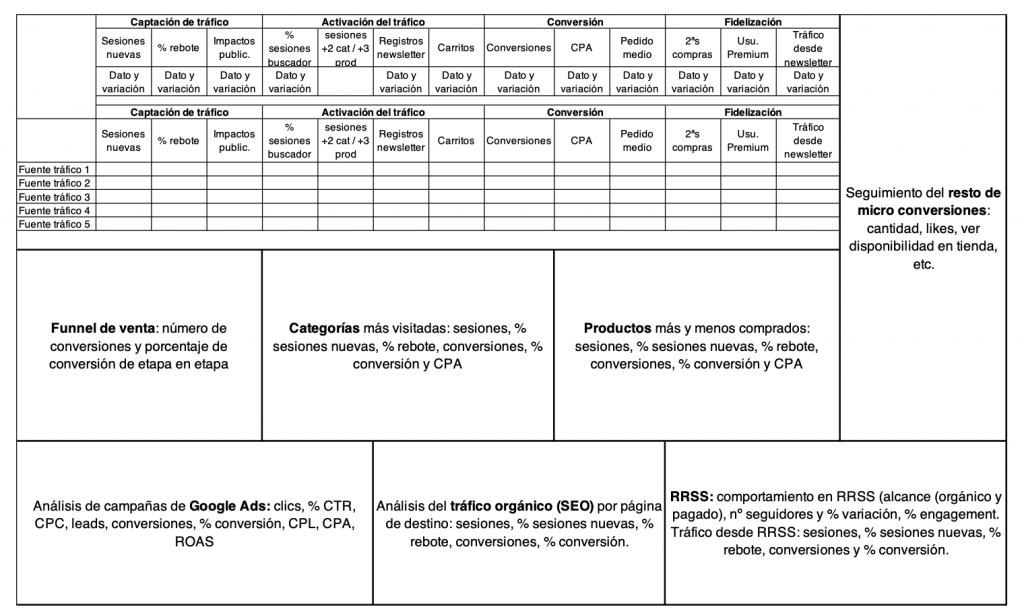
Propuesta de Dashboard de marketing para PCcomponentes – Tristán Elósegui
Consejos para aportar valor con un Dashboard de marketing
Suponiendo que hemos cumplido con todo lo dicho hasta ahora en la parte estratégica y técnica, mis principales consejos son:
- Visualización correcta: el tablero de control tiene que ser perfectamente entendible por la persona que lo va a analizar y su cliente (ya sea interno o externo).
Recuerda que no se trata de hacer cosas bonitas o espectaculares (aunque ayuden a hacerlo más fácil), si no de tomar decisiones. Por lo tanto, esta debe ser nuestra prioridad. - Correcta selección métricas: además de acertar con las métricas que mejor describen la actividad de marketing, debemos pensar en nuestro cliente ¿qué le interesa? ¿qué métrica reporta a su jefe?
Es la mejor forma de fidelizarle y provocar que cada semana o mes, lo primero que haga sea abrir el dashboard comercial o de marketing que acaba de recibir. - Analiza, no describas: el análisis es lo más importante del cuadro de mando. Describir los datos que estás viendo no aporta valor alguno. Para hacerlo, debes hablar de cuatro cosas:
- ¿Qué ha pasado?
- ¿Por qué ha pasado?
- Recomendaciones basadas en datos.
- Resultados esperados de poner en práctica tus recomendaciones.
Ejemplos de dashboard
Para terminar el artículo, os dejo con varios ejemplos de varios tipos de cuadros de mando.
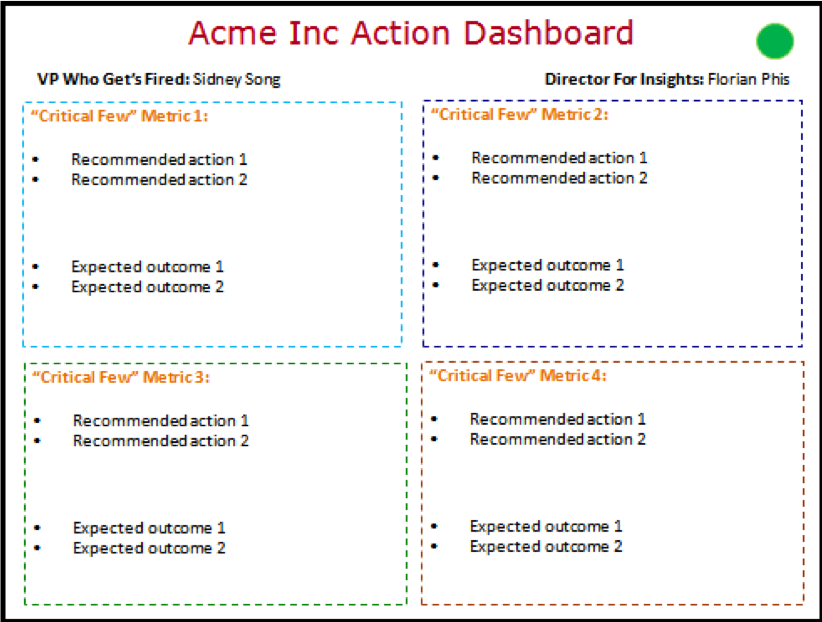
Avinash Kaushik dashboard para gerencia de empresa
.
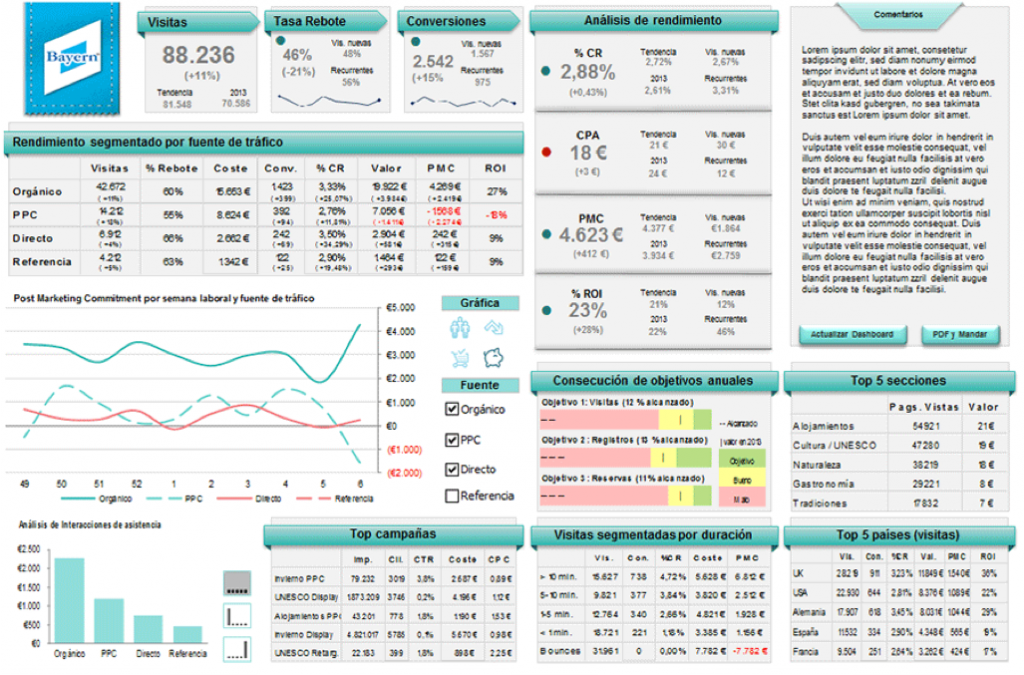
Agustín Suárez – Dashboard de Marketing
.
Fuente: tristanelosegui.com, 2019.

___________________________________________________________________
Vincúlese a nuestras Redes Sociales:
LinkedIn YouTube Facebook Twitter
___________________________________________________________________

.
.
Cómo los sesgos cognitivos afectan nuestro juicio
abril 22, 2020
25 Heurísticos y Sesgos Cognitivos: nuestros errores de juicio
Por Marta Guerri.

¿Qué son los sesgos cognitivos?
Ya sea porque nuestro cerebro posee una capacidad limitada, o porque no siempre disponemos de toda la información que desearíamos o porque nos embarga la incertidumbre de las consecuencias de tomar una u otra decisión, por lo que en muchas ocasiones tomamos “atajos” mentales para llegar a la solución de los problemas. Estos atajos mentales que tomamos de forma inconsciente, en psicología se llaman “Heurísticos”, y nos ayudan a simplificar la gran cantidad de procesos mentales que llevamos a cabo constantemente y a hacer más llevadera nuestra vida diaria.Publicidad
Y es que nuestro cerebro no es capaz de procesar toda la información que recibe a través de los sentidos, por lo que necesita hacer una selección de la misma. Cuando nuestros atajos mentales o heurísticos nos conducen a errores de conclusión, les llamamos sesgos cognitivos.
Los principales sesgos cognitivos que se conocen
Sesgo de memoria
Todos sabemos que nuestra memoria no es perfecta, se difumina con el tiempo y fácilmente nos induce a errores inconscientes. Las investigaciones realizadas revelan que cuando evaluamos recuerdos para poder tomar decisiones sobre nuestro futuro, a menudo se muestran sesgados por los acontecimientos que son muy positivos o muy negativos, y es que tendemos a recordar los hechos insólitos o poco habituales más que acontecimientos diarios, cotidianos. La cusa es que el cerebro da mucha más importancia a los fenómenos extraordinarios o no tanta a usuales, seguramente debido a la importancia que estos tenían en el aprendizaje a lo largo de la evolución. Como resultado, ese sesgo de nuestra memoria afecta a nuestra capacidad de predicción en el futuro.
Para poder evitar ese sesgo se recomienda tratar de recordar el mayor número posible de eventos similares, de esta forma se pretende evitar caer en los extremos, a menudo poco representativos.Publicidad
Falacia de planificación
Este sesgo se refiere a la tendencia que tenemos a subestimar el tiempo que tardamos en terminar una tarea. Al parecer tendemos a planear los proyectos con cierta falta de detalle que nos permitiría la estimación de las tareas individuales. La falacia de la planificación no solo provoca demoras, sino también costos excesivos y reducción de beneficios debido a estimaciones erróneas.
Como dice el científico estadounidense Douglas Hofstadter hay que tener presente que «Hacer algo te va llevar siempre más tiempo de lo que piensas, incluso si tienes en cuenta la Ley de Hofstadter». La ley de Hofstadter es un adagio autorreferencial, acuñado por Douglas Hofstadter en su libro Gödel, Escher y Bach para describir la dificultad ampliamente experimentada de estimar con precisión el tiempo que llevará completar tareas de complejidad sustancial.
Ilusión de control
Este sesgo se encuentra detrás de muchas supersticiones y comportamientos irracionales. Es la tendencia que tenemos a creer que podemos controlar ciertos acontecimientos, o al menos a influir en ellos. Es gracias a este pensamiento que los humanos, desde tiempo inmemorial, creamos rituales y supersticiones que nos aportan cierta seguridad. Un ejemplo de la actualidad se puede ver en los deportistas que repiten ciertas conductas esperando que condicionen cosas como su capacidad de marcar goles, y que evidentemente depende de muchos otros factores objetivos.
Sesgo de apoyo a la elección
En el momento en que elegimos algo (desde una pareja a una pieza de ropa) tendemos a ver esa elección con un enfoque más positivo, incluso si dicha elección tiene claros defectos. Tendemos a optimizar sus virtudes y minimizamos sus defectos.
Efecto de percepción ambiental
Aunque nos parezca extraño, el ambiente que nos rodea ejerce una gran influencia en el comportamiento humano. Un ambiente deteriorado, caótico y sucio provoca que las personas se comporten de manera menos cívica, y también les inclina a cometer más acciones vandálicas y delictivas. Este efecto es la base de la «teoría de las ventanas rotas» estudiado por el psicólogo Philip Zimbardo.
Sesgo de disponibilidad
El sesgo o heurístico de disponibilidad es un mecanismo que la mente utiliza para valorar qué probabilidad hay de que un suceso suceda o no. Cuando más accesible sea el suceso, más probable nos parecerá, cuanto más reciente la información, será más fácil de recordar, y cuanto más evidente, menos aleatorio parecerá.
Este sesgo cognitivo se aplica a muchísimas esferas de nuestra vida, por ejemplo, se ha demostrado que doctores que han diagnosticado dos casos seguidos de una determinada enfermedad no muy usual, creen percibir los mismos síntomas en el próximo paciente, incluso siendo conscientes de que es muy poco probable (estadísticamente hablando) diagnosticar tres casos seguidos con la misma enfermedad. Otro ejemplo es el de una persona que asegura que fumar no es tan dañino para la salud, basándose en que su abuelo vivió más de 80 años y fumaba tres cajetillas al día, un argumento que pasa por alto la posibilidad de que su abuelo fuera un caso atípico desde el punto de vista estadístico.
En el fondo consiste en sobreestimar la importancia de la información disponible (y extraer por tanto conclusiones erróneas). Las loterías por ejemplo, explotan el sesgo de la disponibilidad, y es que si las personas comprendiesen las probabilidades reales que tienen de ganar, probablemente no comprarían nunca más un décimo en su vida.
El efecto Dunning-Kruger
El efecto Dunning-Kruger sesgo cognitivo consiste en una de autopercepción distorsionada, según la cual los individuos con escasas habilidades o conocimientos, piensan exactamente lo contrario; se consideran más inteligentes que otras personas más preparadas, están en la certeza de que son superiores de alguna forma a los demás, midiendo así incorrectamente su habilidad por encima de lo real. Esta distorsión se debe a la inhabilidad cognitiva del sujeto de reconocer su propia ineptitud, debido a que su habilidad real debilitaría su propia confianza y autoestima. Por el contrario, los individuos competentes asumen, falsamente, que los otros tienen una capacidad o conocimiento equivalente o incluso superior al suyo.
Los autores de este descubrimiento David Dunning y Justin Kruger de la Universidad de Cornell, trataron de averiguar si existía algún remedio para nivelar la autoestima sobrevalorada de los más incapaces. Por suerte resultó que sí lo había: la educación. El entrenamiento y la enseñanza podían ayudar a estos individuos incompetentes a darse cuenta de lo poco que sabían en realidad.
Ya lo dijo en su momento Charles Darwin: “La ignorancia engendra más confianza que el conocimiento”.

Efecto halo
El efecto de halo es un sesgo cognitivo por el cual la percepción de un rasgo es influenciado por la percepción de rasgos anteriores en una secuencia de interpretaciones. O sea, si nos gusta una persona, tendemos a calificarla con características favorables a pesar de que no siempre disponemos de mucha información sobre ella, por ejemplo, pensamos de alguien que es simpático, y esto nos hace presuponer que ya conocemos otras características más específicas como: también es inteligente.
El mejor ejemplo para entender este sesgo son las estrellas mediáticas (actores, cantantes, famosos…) demuestran el efecto de halo perfectamente. Debido a que a menudo son atractivos y simpáticos, entonces y de manera casi automática, suponemos que también son inteligentes, amables, poseen buen juicio y así sucesivamente. El problema aparece cuando estas suposiciones son erróneas, ya que se basan a menudo en aspectos superficiales.
Esta tendencia parece estar presente incluso en todos los niveles sociales, tanto bajos como altos, incluyendo donde la objetividad es primordial. Por ejemplo, se ha demostrado que, de media, a la gente atractiva le caen penas de prisión más cortas que otros que fueron condenados por delitos similares.
Sesgo del poder corrupto
Seguro que a muchos no les va a de extrañar la realidad de este sesgo, que dice que hay una tendencia demostrada en la que los individuos con poder son fácilmente corrompibles, en especial cuando sienten que no tienen restricciones y poseen plena libertad. ¿Les suena de algo? Políticos, empresarios, actores famosos, deportistas de élite e incluso la realeza están llenos de casos de corrupción.
Sesgo de proyección
Este sesgo nos habla de la tendencia inconsciente a asumir que los demás poseen pensamientos, creencias, valores o posturas parecidas a las nuestras. Como si fueran una proyección de nosotros mismos.Publicidad
Efecto del lago Wobegon o efecto mejor que la media
Es la tendencia humana a autodescribirse de manera favorable, comunicando las bondades de uno mismo y pensar que se encuentra por encima de la media en inteligencia, astucia u otras cualidades. Llamado también síndrome de superioridad ilusoria.

Sesgo de impacto
Este sesgo se refiere a la tendencia que tenemos a sobreestimar nuestra reacción emocional, sobrevalorando la duración e intensidad de nuestros futuros estados emocionales. Pero las investigaciones muestran que la mayoría de las veces no nos sentimos tan mal como esperábamos cuando las cosas no van como queremos, por ejemplo. Este sesgo es una de las razones por la que a menudo nos equivocamos en la predicción sobre cómo nos afectarán emocionalmente los acontecimientos futuros. Los estudios han demostrado que meses después de que una relación termine, las personas no suelen ser tan infelices como esperaban y que personas a las que le ha tocado la lotería, con el tiempo vuelven a su grado de felicidad habitual o que tenían antes de ganar el premio.
Efecto del falso consenso
El sesgo de falso consenso efecto es parecido al antes descrito sesgo de proyección, y es que la mayoría de personas juzgan que sus propios hábitos, valores y creencias están más extendidas entre otras personas de lo que realmente están.
Heurístico de representatividad
Este heurístico es una inferencia que hacemos sobre la probabilidad de que un estímulo (persona, acción o suceso) pertenezca a una determinada categoría. Por ejemplo, si decimos que Álex es un chico joven metódico cuya diversión principal son los ordenadores. ¿Qué le parece más probable?, ¿que Álex sea estudiante de ingeniería o de humanidades?
Cuando se hacen preguntas de este tipo, la mayoría de la gente tiende a decir que seguramente Álex estudia ingeniería. Un juicio así resulta, según el psicólogo Daniel Kahneman de la aplicación automática (inmediata o no) del heurístico de representavidad. Suponemos que estudia ingeniería porque su descripción encaja con un cierto estereotipo de estudiante de ingeniería. Pero esto pasa por alto hechos como que, por ejemplo, los estudiantes de humanidades son mucho más numerosos que los de ingeniería, por lo que sería mucho más probable encontrar estudiantes de humanidades que se correspondan con esta descripción.
Este sesgo no solo es anecdótico, sino que forma parte del fundamento de ciertos prejuicios sociales. Por ejemplo, cuando juzgamos la conducta de un miembro de un determinado colectivo, como los inmigrantes, tendemos muchas veces a basarnos en estereotipos supuestamente representativos, ignorando datos objetivos de frecuencia y probabilidad.
Defensa de status
Este sesgo se refiere a cuando una persona considera que posee cierto status, tenderá a negar y a defenderse de cualquier comentario que lo contradiga, aun si para ello debe autoengañarse.

Prejuicio de retrospectiva o recapitulación
Es la tendencia que tenemos a ver los hechos pasados como fenómenos predecibles. Las personas sesgamos nuestro conocimiento de lo que realmente ha pasado cuando evaluamos nuestra probabilidad de predicción. En realidad este es un error en la memoria. De la misma manera que también tenemos tendencia a valorar los eventos pasados de una forma más positiva a como ocurrieron en realidad.

Error fundamental de atribución
Se refiere a la tenencia que mostramos a priorizar nuestras dotes personales para valorar nuestros éxitos y a atribuir a las circunstancias externas nuestros fracasos. En cambio cuando se trata de otra persona, la tendencia es la inversa, atribuimos a la suerte o la ayuda sus éxitos y a características internas sus fallos.
Sesgo de disconformidad
Es la tendencia que tenemos a hacer una crítica negativa a la información que contradice nuestras ideas, mientras que aceptamos perfectamente aquella que es congruente con nuestras creencias o ideologías. De este modo se produce una percepción selectiva por la cual las personas perciben lo que quieren en los mensajes de los demás o de los medios de comunicación. y es que por lo general las personas tendemos a ver e interpretar las cosas en función de nuestro marco de referencia. También tenemos más probabilidades de buscar información favorable a nuestras ideas que buscar información que desafíe nuestras ideologías o línea de pensamiento.
Efecto Forer o efecto de validación subjetiva
El efecto Forer es la tendencia a aceptar descripciones personales vagas y generales como excepcionalmente aplicables a ellos mismos, sin darse cuenta que la misma descripción podría ser aplicada a cualquiera. Este efecto parece explicar, por lo menos en parte, por qué tanta gente piensa que las pseudociencias funcionan, como la astrología, cartomancia, quiromancia, adivinación, etc., porque aparentemente proporcionan análisis acertados de la personalidad. Los estudios científicos de esas pseudociencias demuestran que no son herramientas válidas de valoración de la personalidad, sin embargo cada una tiene muchos adeptos que están convencidos de que son exactas.

Heurístico de anclaje y ajuste o efecto de enfoque
Este heurístico describe la tendencia humana a confiar demasiado en la primera información que obtienen para luego tomar decisiones: el «ancla». Durante la toma de decisiones, el anclaje se produce cuando las personas utilizan una “pieza” o información inicial para hacer juicios posteriores. Una vez que el ancla se fija, el resto de información se ajusta en torno a ella incurriendo en un sesgo.
Por ejemplo, si preguntamos a unos estudiantes 1) ¿cómo de feliz te sientes con tu vida? y 2) ¿cuántas citas has tenido este año?, tenemos que la correlación es nula (según las respuestas tener más citas no alteraría el nivel de bienestar). Sin embargo, si se modifica el orden de las preguntas, el resultado es que los estudiantes con más citas se declaran ahora más felices. Es falto de lógica, pero al parecer, focalizar su atención en las citas hace que exageren su importancia.
Ilusión de frecuencia
Al parecer, cuando un fenómeno ha centrado nuestra atención recientemente, pensamos que este hecho de repente aparece o sucede más a menudo, aunque sea improbable desde el punto de vista estadístico. En realidad, esto ocurre porque ahora nosotros lo percibimos de forma diferente (antes no le prestábamos atención) y por lo tanto creemos erróneamente que el fenómeno se produce con más frecuencia.

Ilusión de la confianza
Este sesgo se trata de la confusión entre la confianza de quien nos habla con su credibilidad, de tal manera que percibimos a una persona como más creíble cuanta más confianza muestra en sus argumentaciones. La realidad es que las investigaciones han demostrado que la confianza no es un buen indicador, ni tampoco es una forma fiable de medir la capacidad o aptitud de una persona.
Punto de referencia o status-quo
Al parecer un mismo premio no posee igual valor para dos personas diferentes. Por ejemplo, si tengo dos mil euros y gano cien en una apuesta, lo valoro menos que si tengo quinientos euros y gano esos mismos cien en la apuesta. El punto de referencia es muy importante. Pero sus implicaciones pueden ser algo mayores, pues no sólo se trata de la referencia que tengo respecto a mi propia riqueza inicial, sino con la riqueza de mi círculo de personas cercano. Si alguien desconocido para mi gana cien mil euros en la lotería, yo no me veo afectado. En cambio, si los gana mi compañero de trabajo, me da la sensación de que soy más pobre y desgraciado, aunque no hubiera jugado a la lotería.
Efecto Bandwagon o efecto de arrastre
Este error consiste en la tendencia a hacer (o creer) cosas sólo porque muchas otras personas hacen (o creen) dichas cosas. Al parecer, la probabilidad de que una persona adopte una creencia aumenta en función del número de personas que poseen esa creencia. Se trata de un fuerte pensamiento de grupo.

Efecto Keinshorm
Es la predisposición a contradecir sistemáticamente las ideas o formulaciones que otra persona hace y con la cual no se simpatiza, sólo por este hecho, pues ya no deseamos que tenga la razón y estamos más predispuestos a no creer en sus palabras.
Fuente: psicoactiva.com

.
.
George W. Bush urgió en 2005 a prepararnos para futuras pandemias
abril 18, 2020
El día que George W. Bush alertó sobre el peligro de la próxima pandemia e intentó preparar a EEUU para enfrentarla
En 2005, el entonces presidente republicano pronunció un discurso en el que explicó lo que se debía hacer y cómo debía responder su país ante una crisis como la actual del coronavirus.
“Una pandemia se parece mucho a un incendio forestal. Si se detecta temprano, podría extinguirse con un daño limitado. Si se deja que arda sin ser detectado, puede convertirse en un infierno que puede extenderse rápidamente más allá de nuestra capacidad de controlarlo”, dijo en un discurso en 2005 el entonces presidente George W. Bush en la sede del Institutos Nacionales de la Salud (NIH, por sus siglas en inglés).
G. W. Bush quería que su país, y el mundo entero, estuviesen preparados ante una pandemia como la del coronavirus, que ya dejó casi 150 mil muertos y más de dos millones de contagios.
“Para responder a una pandemia, necesitamos personal médico y suministros adecuados de equipo”, dijo Bush. “En una pandemia, todo, desde jeringas hasta camas de hospital, respiradores y equipos de protección, serían escasos”, advirtió.
Bush dispuso de 7 mil millones de dólares de su Gobierno para desarrollar un plan que preparara a Estados Unidos ante una crisis de este tipo. Los secretarios de su gabinete instaron a su personal a tomarse en serio los preparativos y lanzaron el sitio web www.pandemicflu.gov, el cual todavía está en funcionamiento. Sin embargo, con el paso del tiempo, se hizo cada vez más difícil justificar la financiación.
.
![Una mujer es llevada a una ambulancia por los paramédicos en un centro de salud en Brooklyn durante el brote de coronavirus (COVID-19) en Nueva York [14 de abril de 2020] (Reuters/ Brendan McDermid)](https://www.infobae.com/new-resizer/BsZFI___U_usR4kDfn62HyEY7TU=/750x0/filters:quality(100)/arc-anglerfish-arc2-prod-infobae.s3.amazonaws.com/public/CSW5EBSQYJCQLNRKGM47R3EELY.jpg)
En su discurso en el NIH, Bush presentó toda clases propuestas y describió cómo se desarrollaría una pandemia en los Estados Unidos. Entre los presentes se encontraba el doctor Anthony Fauci, el prestigioso epidemiólogo, líder de la crisis actual en su país y quien en ese momento ya era el director del Instituto Nacional de Alergias y Enfermedades Infecciosas.
“Primero, debemos detectar los brotes que ocurran en cualquier parte del mundo; segundo, debemos proteger al pueblo estadounidense almacenando vacunas y medicamentos antivirales, y mejorar nuestra capacidad para producir rápidamente vacunas contra una cepa pandémica; y tercero, tenemos que estar preparados para responder a nivel federal, estatal y local en caso de que una pandemia llegue a nuestras costas”, dijo Bush.
Pero, ¿qué había pasado para que Bush pronunciara ese discurso?, ¿por qué el ex presidente republicano estaba preocupado ante un peligro no latente y difícil de predecir? Unos meses atrás en su rancho en Crawford, Texas, había leído el libro La gran influenza, del historiador John M. Barry. La obra cuenta la historia del brote de influenza en 1918 que mató a millones de personas en Europa y el mundo.
[Nota de EP: Este tipo de anticipación es lo que debe producir la Inteligencia Estratégica.]

“Tienes que leer esto”, recuerda Fran Townsend, en ese entonces asesora de seguridad nacional, lo que le dijo Bush cuando le recomendó el libro. “Mira, esto sucede cada 100 años. Necesitamos una estrategia nacional”, agregó el ex mandatario a su ex asesora.
/arc-anglerfish-arc2-prod-infobae.s3.amazonaws.com/public/2PUHT6QWURCF5JE4AR4UESRU5U.jpg)
A partir de ese momento se creó el plan de preparación ante una pandemia más completo en la historia de EEUU: incluía diagramas para un sistema global de alerta temprana, fondos para desarrollar nuevas tecnologías y producir de forma rápida vacunas y una sólida reserva nacional de suministros críticos como máscaras faciales y respiradores, informó ABC News.
Sin embargo, el proyecto no fue tomado en serio por el resto del aparato político y gran parte del ambicioso plan no se realizó o quedó archivado, a medida que otras prioridades surgían, como la crisis de 2008 que sacudió a EEUU y al mundo al entero.
Durante su discurso de hace 15 años, G. W. Bush fue claro en trazar un estrategia y dijo que lo primero y más importante era detectar los primeros brotes antes de que se propaguen por todo el mundo. Durante la pandemia de coronavirus una las principales críticas que le han hecho algunos líderes mundiales a China es haber ocultado información cuando se presentaron los primero casos en la ciudad de Wuhan.

“Una pandemia no es como otros desastres naturales, los brotes pueden ocurrir de forma simultánea en centenares o incluso miles de lugares al mismo tiempo”, dijo Bush.
“Los científicos y los médicos no pueden predecir cuándo ocurrirá la próxima pandemia o cuán severa será, pero la mayoría está de acuerdo en que, en algún momento, estaremos frente a una”, agregó.
Adaptado de infobae.com, 17/04/20.

Cómo enfrentó George W. Bush las amenazas del SIDA y el SARS
El president George W. Bush ha recibido elogios de republicanos y demócratas por el compromiso que asumió para combatir el SIDA mundialmente, pero particularmente en África.

En 2003, la administración del presidente George W. Bush creó el Plan de Emergencia para el Alivio del SIDA, una iniciativa para atender la epidemia mundial.
“Esa iniciativa fue posiblemente una de las mejores políticas de su presidencia”, dio Barry. “Básicamente recibió un aplauso universal”.
Desde su inicio, el plan de Bush proporcionó 80.000 millones de dólares para tratamiento el SIDA, prevención e investigación, convirtiéndolo en el más grande programa global de salud enfocado en una enfermedad. Se le da crédito con haber salvado a millones de personas, especialmente en el África sub-sahariana.
En abril de 2003, luego de un brote en Asia, G. W. Bush firmó una orden ejecutiva agregando el Síndrome Severo Agudo Respiratorio (SARS, por sus siglas en inglés) a una lista de enfermedades contagiosas que podrían resultar en el aislamiento forzado de personas. Eventualmente, unas 8.000 personas contrajeron el virus a nivel mundial, y unas 774 murieron durante el brote del 2003. En Estados Unidos, solo ocho casos de SARS fueron documentados con resultados clínicos.
En 2005, la administración Bush creó la Estrategia Nacional para la Pandemia de Influenza, que obliga al gobierno a mantener y distribuir un inventario de suministros médicos en el evento de un brote, y una infraestructura para que futuros presidentes puedan aprender y apoyarse al lidiar con sus propias pandemias.
Adaptado de: voanoticias.com
Vincúlese a nuestras Redes Sociales:
LinkedIn YouTube Facebook Twitter

.
.
x
National Security Act: El nacimiento de la CIA
julio 26, 2019
La National Security Act de 1947, Pub. L. No. 235, 80 Cong., 61 Stat. 496 (July 26, 1947), firmada por el presidente de Estados Unidos Harry S. Truman, fue un acta que realineó y reorganizó las fuerzas armadas estadounidenses, la política exterior, y el aparato de inteligencia, luego de finalizada la Segunda Guerra Mundial.
La mayoría de las disposiciones del acta tomaron efecto el 18 de septiembre de 1947, un día después de que el senado confirmara a James V. Forrestal como el primer secretario de Defensa.
El acta combinó el Departamento de Guerra y el Departamento de la Marina en la National Military Establishment (NME) dirigida por el secretario de Defensa. También fue responsable de la creación de un Departamento de la fuerza aérea separado del existente «United States Army Air Forces». Inicialmente, cada uno de los tres departamentos mantuvieron un estatus de cuasigabinete, pero el acta fue corregida el 10 de agosto de 1949 para asegurar su subordinación a la Secretaría de Defensa. Al mismo tiempo, la NME fue renombrada Departamento de Defensa de Estados Unidos.
Además de la reorganización militar, La National Security Act estableció el consejo de Seguridad Nacional, una central de coordinación para la política de seguridad nacional en la rama ejecutiva, y la Agencia Central de Inteligencia (CIA); la primera agencia de inteligencia estadounidense establecida en tiempos de paz.
El acta y sus cambios, junto con la doctrina del presidente Truman y el Plan Marshall, fueron los mayores componentes administrativos para la guerra fría ejecutados por su mandato.
Fuente: Wikipedia, 2019.

______________________________________________________________________________
Más información:
Inteligencia Estratégica
Sherman Kent, el creador de la Inteligencia Estratégica
.
Sherman Kent, el creador de la Inteligencia Estratégica
febrero 25, 2019
Sherman Kent: El padre del análisis en Inteligencia Estratégica
.
Sherman Kent fue durante tres décadas analista de la Oficina de Servicios Estratégicos (OSS) y, más tarde, de la CIA. En el intervalo desde su servicio en la II Guerra Mundial y su regreso a la CIA en 1950, Sherman Kent escribió la obra por la que aún hoy es considerado el padre del análisis en inteligencia estratégica. La obra, titulada Strategic Intelligence for American World Policy sigue considerándose obra de referencia para los analistas de todo el mundo. Sherman Kent permaneció en la CIA hasta su retiro en 1967.
Mucho tiempo antes, Sherman Kent se había doctorado en Historia por la Universidad de Yale e impartía clases en la facultad de Historia de esa misma universidad. El lector se preguntará, no sin motivo, cómo pudo aquél irónico y bromista profesor de Historia de la universidad de Yale (sus amigos de pregrado le llamaban Buffalo Bill «el cowboy cultivado») inventar toda una metodología en inteligencia. La respuesta está en su especialización. Como señala Jack Davis, Sherman Kent no fue un profesor de Historia convencional, sino que enseñaba la historia como una serie de cambios metodológicos y cognitivos. Explicaba a sus alumnos la importancia de verificar sus fuentes y dejar atrás sus predilecciones y prejuicios personales. Como el lector podrá comprobar eso no está muy lejos del trabajo de cualquier analista. Su modelo de evaluación de fuentes en términos de fiabilidad de la fuente y credibilidad de la información aún sigue teniendo plena vigencia en los servicios de inteligencia de todo el mundo.
Fuente: elbuhoanaltico.blogspot.com
 .
.
Libro completo en PDF: Inteligencia Estrategica _ Sherman Kent
.
Sherman Kent
 Sherman Kent (06/12/1903 – 11/03/1986) fue un profesor de historia de la Universidad de Yale que, durante la Segunda Guerra Mundial y 17 años de la Guerra Fría prestó servicios en la Agencia Central de Inteligencia , fue pionero en muchos de los métodos de Análisis de Inteligencia. A menudo se lo llama «el padre del análisis de inteligencia».
Sherman Kent (06/12/1903 – 11/03/1986) fue un profesor de historia de la Universidad de Yale que, durante la Segunda Guerra Mundial y 17 años de la Guerra Fría prestó servicios en la Agencia Central de Inteligencia , fue pionero en muchos de los métodos de Análisis de Inteligencia. A menudo se lo llama «el padre del análisis de inteligencia».
Kent era el hijo del congresista estadounidense William Kent.
Se graduó de The Thacher School y de la Universidad de Yale, donde estudió historia europea con la intención de pasar su carrera como académico. Después de graduarse en 1926, pasó varios años enseñando e investigando, y luego se unió a la Oficina de Servicios Estratégicos (OSS) con el estallido de la guerra en Europa en 1942.
Sherman Kent primero sirvió en la Rama de Investigación y Análisis del OSS como Jefe de la División Europa-África. En esta función, supervisó gran parte del proceso que ahora se consideraría preparación de inteligencia del espacio de batalla en apoyo de la planificación de la Operación Antorcha , la invasión aliada de 1942 en el norte de África.
Después de un período de posguerra en el National War College, regresó a Yale durante tres años, durante los cuales escribió su obra clásica, Strategic Intelligence for American World Policy (disponible para descargar en PDF, ver arriba). En noviembre de 1950, durante la crisis que siguió, la incursión comunista china en la Guerra de Corea, que provocó una acumulación y reorganización de la comunidad de inteligencia estadounidense, fue llamado a Washington, DC, para ayudar al historiador de Harvard William L. Langer, con quien había trabajado en OSS, para formar una nueva Oficina de Estimaciones Nacionales (ONE) de la CIA. Sucedió a Langer como jefe de ONE en 1952, sirviendo en ese puesto durante los siguientes quince años bajo cuatro directores de la Central Intelligence, en cuatro administraciones presidenciales.
ONE era una organización pequeña, formada por un Consejo de Estimaciones Nacionales de entre cinco y doce expertos de alto rango, un equipo profesional de 25-30 especialistas regionales y funcionales, y un personal de apoyo. Hasta que se disolvió, seis años después del retiro de Kent, en una reorganización de la CIA (Watergate), ONE preparó más de 1.500 estimaciones especulativas de inteligencia nacional para el presidente y los principales responsables de la política exterior.
Kent lideró ONE a través de años de desafíos y crisis, incluidas las acusaciones de McCarthy contra uno de los asesores jóvenes de Kent, el futuro asesor presidencial William Bundy , y los «fracasos predictivos» durante la Crisis de los Misiles Cubanos y otras alertas de la Guerra Fría.
El papel único y duradero de Kent dentro de la comunidad de inteligencia de los Estados Unidos. Fue formalizar metodologías y «tradecraft» analíticos, al tiempo que fomentó la creación de una «literatura de inteligencia» para proporcionar un mecanismo formal para la transferencia de conocimientos y experiencias entre generaciones de analistas (hoy lo llamaríamos Gestión del Conocimiento).
Sherman Kent se retiró de la CIA en 1967 y murió en 1986.
En 2000, la CIA estableció una escuela con el nombre de Kent dedicada a la búsqueda del profesionalismo en el arte y la ciencia del Análisis de Inteligencia.

Adaptado de: Wikipedia, 2018.
Más información:
Inteligencia Estratégica
Vincúlese a nuestras Redes Sociales:
Google+ LinkedIn YouTube Facebook Twitter
.
.