
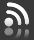
La inteligencia estratégica en los negocios del siglo XXI
noviembre 12, 2025
Anticipación, protección y ventaja competitiva en un mundo incierto
Por Gustavo Ibáñez Padilla.
.
En un escenario global signado por la complejidad, la velocidad del cambio y la interdependencia tecnológica, la inteligencia estratégica se ha convertido en una herramienta esencial para gobiernos, empresas y organizaciones. Si antes era considerada un ámbito casi exclusivo del mundo militar o estatal, hoy constituye un componente transversal en la planificación corporativa, la gestión del riesgo, la toma de decisiones y la protección de activos críticos. Su importancia radica en su capacidad para transformar datos dispersos en conocimiento accionable y, a partir de ello, orientar decisiones responsables y eficaces.
Inteligencia: del dato a la sabiduría
La inteligencia puede entenderse como un proceso destinado a descubrir el orden oculto detrás de lo aparente. Su etimología —intelligere, “leer entre líneas”— resume bien esta idea: observar, comparar, interpretar y conectar puntos. Este recorrido se expresa en la conocida Pirámide del Conocimiento: los datos se convierten en información cuando se organizan; la información se transforma en conocimiento cuando se analiza; y cuando este conocimiento se aplica reiteradamente para tomar decisiones acertadas, se adquiere sabiduría.
La inteligencia es, simultáneamente, un método, un producto y una función organizacional. Y su finalidad es clara: Reducir la incertidumbre del decisor, permitiéndole actuar con fundamento técnico y no por impulso o mera intuición.
.
Inteligencia y Contrainteligencia: la espada y el escudo
La inteligencia busca conocer el entorno para anticipar tendencias, riesgos y oportunidades. La contrainteligencia procura impedir que actores externos —competidores, delincuentes, grupos de presión, Estados adversarios o incluso empleados desleales— accedan a información valiosa o amenacen los activos propios. Ambas funciones son complementarias: sin inteligencia no hay anticipación; sin contrainteligencia no hay seguridad.
Aunque muchas organizaciones no tengan un “Departamento de Inteligencia”, estas funciones existen de facto en áreas como marketing, recursos humanos, seguridad informática, auditoría, compliance o planificación estratégica. Cada una aporta piezas que, integradas, permiten comprender mejor el entorno y proteger los activos críticos.
Los activos sensibles no son solo financieros o tecnológicos: incluyen reputación, conocimiento interno, infraestructura, datos personales de clientes, estrategias de mercado y hasta la propia cultura institucional. En un contexto donde las filtraciones, el espionaje corporativo y los ciberataques están en aumento, desarrollar prácticas de contrainteligencia se vuelve indispensable.

.
El factor humano: el eslabón más débil del sistema
La mayor parte de las vulneraciones de seguridad no provienen de sofisticadas operaciones de hackers, sino de errores humanos. Según informes recientes de empresas de ciberseguridad, más del 80% de los ciberataques exitosos comienzan con fallas básicas: contraseñas débiles, sesiones abiertas, archivos compartidos sin control, o ingeniería social.
Un ejemplo paradigmático se dio en 2025, cuando una histórica empresa británica de servicios logísticos —con más de 150 años de trayectoria— quedó paralizada por un ataque de ransomware que explotó una clave débil utilizada por un empleado externo. La empresa no logró recuperarse, debió declararse en quiebra y dejó a setecientos personas sin empleo. No fue un ataque técnicamente complejo: fue una falla cultural.
Casos similares se observaron en aeropuertos europeos —en septiembre de 2025— afectados por incidentes informáticos que generaron congestiones masivas y pérdidas millonarias. La tecnología avanzó, pero la conducta humana sigue siendo un punto de vulnerabilidad constante.
Por eso, la inteligencia moderna enfatiza la formación del personal, la cultura organizacional y la concientización sobre riesgos emergentes.

.
Inteligencia en los negocios: el caso Moneyball y más allá
El ejemplo de los Oakland Athletics, popularizado por la película Moneyball, es ilustrativo. Un equipo sin grandes recursos incorporó métodos estadísticos para identificar jugadores subvalorados por el mercado. El análisis de datos permitió competir —y ganar— contra organizaciones más poderosas. Así nació una revolución en el deporte profesional: la inteligencia aplicada al desempeño deportivo, demostrando que el análisis racional puede superar los prejuicios y la intuición tradicional.
Ese modelo hoy atraviesa todos los sectores: desde las finanzas algorítmicas hasta las cadenas de suministro, pasando por la industria cultural, los seguros o la logística. Netflix decide qué series producir basándose en patrones de consumo global; Amazon y UPS optimizan rutas en tiempo real; aerolíneas fijan precios dinámicos según modelos predictivos. Todo esto es inteligencia aplicada a los negocios.
El auge de las fuentes abiertas
Más del 95% de la inteligencia que utilizan Estados y empresas proviene de Fuentes abiertas (OSINT, Open Source Intelligence). Noticias, redes sociales, bases de datos públicas, registros comerciales, documentos académicos, movimientos financieros, imágenes satelitales de libre acceso. Hoy, un analista puede reconstruir la estructura económica de una organización criminal, el despliegue militar de un Estado o las tendencias de consumo en una ciudad solo con información abierta.
Esto genera un desafío: la sobreabundancia de datos (infoxicación). El problema ya no es la falta de información, sino el exceso. La clave es filtrar, validar, sintetizar y convertir ese océano de datos en conocimiento útil.
Analistas entrenados para ver lo invisible
El analista debe identificar patrones, detectar anomalías y reconocer señales débiles. La historia ofrece ejemplos elocuentes: antes del atentado del 11 de septiembre de 2001, instructores de vuelo reportaron comportamientos extraños de alumnos que solo buscaban aprender maniobras en altura sin despegar ni aterrizar. Esa información existía, pero no se integró. La falla no fue de datos, sino de análisis y coordinación.
Hoy, muchos países trabajan con sistemas de alerta temprana que integran información de múltiples agencias. El modelo más desarrollado es el de la comunidad de inteligencia estadounidense luego del 9/11, donde se estableció un sistema de cooperación interagencial para evitar otra falla sistémica.
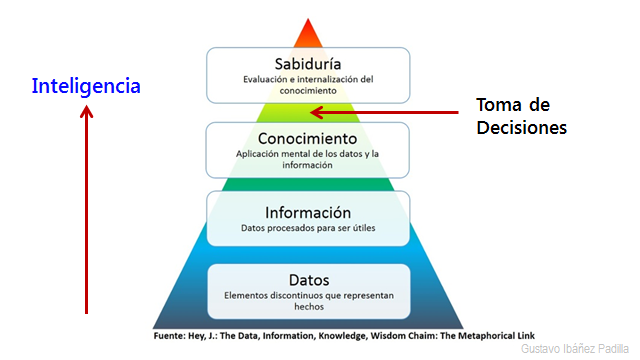
Inteligencia económica, turística y geopolítica
En el ámbito económico, la inteligencia permite anticipar fluctuaciones de precios, detectar oportunidades de inversión y evaluar vulnerabilidades en cadenas de suministro. La reciente reconfiguración global generada por la guerra en Ucrania, las tensiones en el Mar de China Meridional y las disrupciones pospandemia demostraron la importancia de prever escenarios alternativos y contar con planes contingentes.
La inteligencia turística —cada vez más relevante para países cuya economía depende de este sector— permite analizar flujos de visitantes, percepciones de seguridad, tendencias culturales y la competencia entre destinos.
En la geopolítica contemporánea, donde la rivalidad entre grandes potencias se proyecta sobre recursos estratégicos (energía, minerales críticos, rutas marítimas, infraestructura digital), la inteligencia se convierte en un instrumento indispensable para planificar políticas públicas y anticipar movimientos en el tablero internacional.
.
Tecnología e inteligencia: IA, Big data y autonomía
La revolución tecnológica ha multiplicado las capacidades de análisis. La inteligencia artificial permite procesar volúmenes gigantescos de datos; los algoritmos de aprendizaje automático identifican patrones invisibles para los humanos; los sistemas autónomos generan información en tiempo real; y las cadenas de bloques ofrecen nuevas formas de trazabilidad y verificación.
Sin embargo, la tecnología no reemplaza al analista. Los algoritmos son potentes, pero necesitan interpretación humana. Pueden detectar correlaciones, pero no comprender contextos culturales, estrategias políticas o motivaciones humanas. La inteligencia moderna se apoya en la tecnología, pero depende del criterio humano para convertir la información en decisiones.
El valor estratégico de una alerta temprana
Las crisis rara vez aparecen de manera súbita: suelen anunciarse mediante señales que, observadas con atención, permiten anticipar su desarrollo. El aumento de tensiones geopolíticas, la volatilidad de mercados financieros, los cambios regulatorios, la conflictividad social extrema, los movimientos migratorios o la disrupción de rutas comerciales pueden ser indicadores tempranos de escenarios futuros.
Por eso, los sistemas de inteligencia eficientes trabajan con modelos de prospectiva, análisis de riesgos, simulaciones y construcción de escenarios. El objetivo no es predecir el futuro, sino prepararse para futuros posibles.
Una nueva cultura para las organizaciones
La inteligencia estratégica se está convirtiendo en una cultura institucional. No es una actividad reservada a especialistas aislados, sino un enfoque transversal: desde el CEO hasta el empleado de soporte técnico. Las empresas y los Estados que logran instalar esta cultura son los que mejor se adaptan a entornos cambiantes.
La inteligencia no solo mejora las decisiones: evita costosos errores. Y en un mundo donde una mala decisión puede destruir una organización, esa capacidad vale tanto o más que cualquier acierto brillante.
El desafío del nuevo siglo
El siglo XXI exige organizaciones capaces de observar, interpretar y actuar con rapidez y precisión. La inteligencia estratégica es el puente entre la complejidad del mundo real y las decisiones que construyen el futuro. Quienes desarrollen estas capacidades no solo sobrevivirán: liderarán.
El mundo que viene será más interconectado, más tecnológico y más incierto. La inteligencia —junto con la ética, el análisis riguroso y la visión estratégica— será la herramienta central para navegarlo.
Fuente: Ediciones EP, 12/11/25.
Información sobre Gustavo Ibáñez Padilla
Más información:
El importante mensaje de Los tres días del cóndor
La Inteligencia y sus especialidades en la Sociedad del conocimiento
Seguridad Humana Multidimensional: Una clave para enfrentar los retos contemporáneos
Actuación policial basada en la inteligencia: una pieza clave para enfrentar el crimen organizado y el terrorismo
Vigilar a los que vigilan: cómo evitar los abusos de un Estado policial hipervigilante
Especialización en Inteligencia Estratégica y Crimen Organizado

Artículo completo en formato PDF:

Diploma
.
.
Vigilar a los que vigilan: cómo evitar los abusos de un Estado policial hipervigilante
octubre 20, 2025
Por Gustavo Ibáñez Padilla.
«Quis custodiet ipsos custodes?»
En las últimas décadas la tecnología cambió la geometría del poder. Lo que antes exigía enormes recursos humanos y logísticos —seguir a una persona, intervenir correspondencia, mantener una red de informantes— hoy puede realizarse a escala industrial con unas pocas líneas de código y acceso a los canales globales de las telecomunicaciones. Esa transformación ha elevado la eficacia potencial de los servicios de inteligencia, pero también ha multiplicado los riesgos: la posibilidad de que el Estado —o actores privados aliados a él— transforme la vigilancia en un hábito sistémico que invade derechos, erosiona la confianza pública y corroe el tejido democrático.
La historia reciente ofrece advertencias concretas. Ya a fines del siglo XX surgieron denuncias sobre sistemas de interceptación que operaban más allá de controles nacionales y sin una supervisión democrática adecuada; el caso conocido como Echelon puso en evidencia, ante el Parlamento Europeo y la opinión pública, una red de cooperación entre los «Five Eyes» (servicios de inteligencia de Estados Unidos, Australia, Canadá, Gran Bretaña y Nueva Zelanda) que interceptaba comunicaciones comerciales y privadas a escala global. La investigación parlamentaria subrayó no sólo la existencia de capacidades técnicas, sino la dificultad institucional para auditar prácticas transnacionales de SIGINT (intelligence of signals).

.
Diez años después, en 2013, las filtraciones de Edward Snowden mostraron el alcance actual de esa capacidad: programas como PRISM o XKeyscore ilustraron que la recolección masiva de metadatos y contenidos no es una ficción de película, sino una práctica sistemática, con implicaciones políticas directas —incluidas intervenciones sobre líderes y aliados internacionales— y con instrumentos que, cuando quedan sin control, afectan derechos fundamentales. Esas revelaciones provocaron debates internacionales sobre legalidad, proporcionalidad y supervisión.
Frente a esa realidad técnica y política, la comunidad internacional empezó a afirmar límites normativos: informes y resoluciones de la ONU y de relatores especiales han marcado con nitidez que la vigilancia masiva, indiscriminada o sin recursos de supervisión judicial vulnera estándares de derechos humanos y debe limitarse por ley y por controles independientes. Como subrayó un Relator de la ONU, “la vigilancia masiva y generalizada no puede justificarse en un Estado de derecho.” Ese pronunciamiento inauguró un corpus de recomendaciones sobre transparencia, rendición de cuentas y derecho a reparación para víctimas de espionaje indebido.
Las respuestas normativas no son mera retórica: el Reglamento General de Protección de Datos (GDPR) de la Unión Europea y directivas conexas impusieron un marco robusto sobre el tratamiento de datos personales, incluso ante autoridades del Estado, y exigieron principios —minimización, propósito, responsabilidad— que limitan la acumulación indiscriminada de información. Aunque estas normas nacieron en el ámbito civil y comercial, imprimen un estándar conceptual útil para discutir las prácticas de inteligencia en sociedades democráticas.
El lado oscuro: tecnología en manos del poder y sus efectos sociales
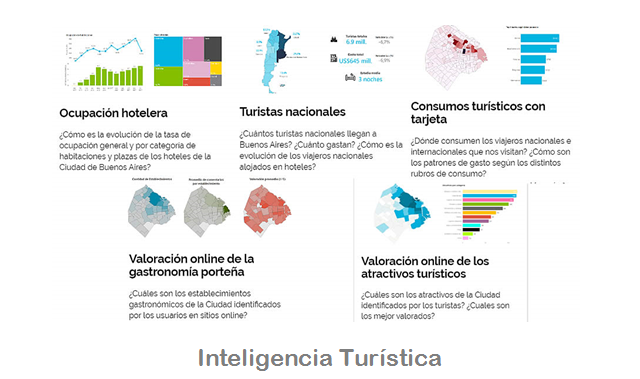
No todos los abusos vienen de estados con regímenes autocráticos; en numerosos casos, democracias consolidadas han incurrido en prácticas problemáticas al invocar seguridad. Pero además existe un fenómeno contemporáneo que complica la trazabilidad del poder: la proliferación de empresas privadas que venden herramientas de intrusión —desde sistemas de interceptación hasta spyware que transforma teléfonos en micrófonos remotos— y que operan en mercados opacos. El escándalo de Pegasus puso a la vista cómo estas tecnologías, originalmente justificadas para combatir el crimen organizado o el terrorismo, terminaron siendo utilizadas para vigilar periodistas, defensores de derechos humanos y adversarios políticos en varios países. La evidencia forense y periodística sobre el uso indebido de estas herramientas provocó condenas y pedidos de regulación internacional.
El efecto social es doble: por un lado, la intrusión directa en la privacidad de sujetos y colectivos; por otro, el impacto indirecto sobre la libertad de expresión y la autonomía de la prensa. Cuando periodistas y fuentes temen que sus comunicaciones sean interceptadas, renuncian a investigar, censuran conversaciones y se reduce la transparencia sobre el ejercicio del poder. No es mera metáfora: organizaciones internacionales han documentado la paralización de investigaciones sensibles y la desmovilización de denuncias ciudadanas ante la sospecha de pinchazos o intrusiones.
.
América Latina: entre la digitalización del control y la fragilidad institucional
En la región latinoamericana las tensiones son palpables. Países con instituciones robustas conviven con Estados frágiles donde la supervisión parlamentaria y judicial sobre actividades de inteligencia es limitada o está politizada. El caso mexicano, con investigaciones que vinculan el uso del spyware Pegasus a aparatos estatales para espiar políticos y periodistas, funcionó como detonante regional: mostró que el problema no era tecnológico sino institucional. El gravamen específico en Latinoamérica es la acumulación de herramientas de vigilancia en contextos donde los mecanismos de rendición de cuentas son débiles, y donde la cultura política puede tolerar el uso discrecional de la inteligencia para objetivos partidarios o empresariales.
América Latina enfrenta además un déficit de marcos legales actualizados: leyes aprobadas en décadas anteriores no contemplan la interoperabilidad digital global ni el papel de proveedores y empresas tecnológicas transnacionales. La Comisión Interamericana de Derechos Humanos y otros organismos han insistido en la necesidad de marcos regionales que protejan a periodistas, activistas y a la sociedad civil frente al abuso de tecnologías de intrusión. La recomendación común es clara: actualizar la normativa, crear instancias independientes de control y garantizar recursos técnicos para auditorías.
Argentina: controles formales y desafíos prácticos
En Argentina el andamiaje legal de inteligencia remonta a la Ley de Inteligencia Nacional [Ley 25.520 (2001)], que establece principios y mecanismos de actuación del sistema de inteligencia. Sin embargo, la persistencia de denuncias y episodios de opacidad han mostrado la tensión entre la letra de la norma y la práctica institucional. Informes de organizaciones de la sociedad civil han criticado la eficacia real de los órganos de control —como la Comisión Bicameral— por limitaciones en acceso a información, recursos técnicos y garantías de independencia. Es decir: existe un marco formal, pero su aplicación y capacidad de fiscalización siguen siendo puntos débiles que requieren reforma profunda.
Un país que aspire a un equilibrio entre seguridad y derechos debe atender tres vertientes simultáneas: 1) legislación actualizada que defina límites claros y sanciones proporcionales; 2) organismos de control con autonomía, acceso técnico y transparencia operativa; y 3) mecanismos de reparación para víctimas de vigilancia ilícita. Sin estas piezas, la supervisión se vuelve ritual y la impunidad permanece.
.
¿Cómo vigilar a quienes vigilan? Instrumentos para un control efectivo
A partir de la experiencia comparada y las recomendaciones internacionales, pueden proponerse medidas concretas:
1. Transparencia institucional y divulgación pública de algoritmos y criterios de selección: explicar qué datos se recaban, con qué criterios se priorizan objetivos y qué algoritmos automatizados son empleados. Transparencia no significa revelar operaciones sensibles, sino dar trazabilidad técnica y legal a los procesos decisionales.
2. Control judicial previo y auditoría independiente: cualquier interceptación debe requerir autorización judicial fundada y sujeta a revisiones posteriores por auditores con acceso a registros y metadatos. Las auditorías técnicas independientes (por ejemplo, por universidades o laboratorios forenses acreditados) son esenciales para comprobar el uso legítimo de herramientas.
3. Prohibición y control de transferencia de tecnologías ofensivas: limitar la compra y el uso de spyware sin mecanismos de supervisión; exigir cláusulas contractuales de responsabilidad y auditoría en los contratos con proveedores privados.
4. Capacitación técnica del poder legislativo y judicial: sin conocimiento técnico, los controles se vuelven simbólicos. Equipar a comisiones y tribunales con peritos y unidades técnicas estables es crucial.
5. Registro público de solicitudes de vigilancia y balances anuales: estadísticas desagregadas que permitan evaluar la proporcionalidad y el sesgo en la selección de objetivos.
6. Protecciones específicas para periodistas, defensores y opositores: umbrales más exigentes para autorizar intervenciones sobre actores políticamente sensibles.
Estas medidas no son una utopía; forman parte de los estándares propuestos por organismos internacionales y ya han sido esbozadas en jurisprudencia y recomendaciones de relatores de la ONU. Implementarlas exige voluntad política y litigiosidad pública —pero también cultura institucional.
Recordar para no repetir
Como advirtió Benjamin Franklin —en una frase que hoy resuena con inquietante actualidad—, quien sacrifica la libertad por seguridad no merece ni libertad ni seguridad. Más contemporáneamente, los relatores de derechos humanos han insistido: la vigilancia indiscriminada erosiona la democracia misma. Estas máximas no constituyen dogma; son recordatorios prácticos de que la tecnología, por sí sola, no nos salva: somos nosotros, con instituciones fuertes y normas claras, quienes debemos decidir los límites.
Vigilancia responsable
Vigilar a los que vigilan no es una postura antipatriótica; es la condición mínima de una República que respete a sus ciudadanos. La defensa de la seguridad y la protección de los derechos no son objetivos opuestos sino complementarios: sólo una inteligencia legítima —limitada, transparente y auditada— puede preservar la seguridad sin devorar las libertades que dice proteger.
Es hora de un compromiso colectivo: parlamentos que actualicen leyes, magistrados que exijan pruebas fundadas, comisiones que cuenten con pericia técnica, periodistas que investiguen y ciudadanía informada que exija cuentas. Si algo enseñan Echelon, Snowden, Pegasus y los informes internacionales, es que el riesgo no es un futuro posible: ya está aquí. La pregunta es si permitiremos que la tecnología decida por nosotros o recuperaremos, con herramientas democráticas, el control sobre quienes nos vigilan.
Actuemos. Reformemos marcos legales, blindemos institutos de control, prohíbanse ventas opacas de tecnologías de intrusión y construyamos auditorías técnicas independientes. No hay seguridad durable sin legitimidad; no hay legitimidad sin vigilancia popular sobre la vigilancia estatal.
Fuente: Ediciones EP, 20/10/25.
Información sobre Gustavo Ibáñez Padilla
Más información:
El importante mensaje de Los tres días del cóndor
La Inteligencia y sus especialidades en la Sociedad del conocimiento
Seguridad Humana Multidimensional: Una clave para enfrentar los retos contemporáneos
Actuación policial basada en la inteligencia: una pieza clave para enfrentar el crimen organizado y el terrorismo
.

.
.
Actuación policial basada en la inteligencia: una pieza clave para enfrentar el crimen organizado y el terrorismo
septiembre 26, 2025
Por Gustavo Ibáñez Padilla.
La actuación policial basada en la inteligencia —conocida por sus siglas en inglés como intelligence-led policing (ILP)— no es una moda operativa: es un cambio de paradigma en la Gestión del riesgo que traslada la iniciativa desde la reacción hacia la anticipación. En esencia, plantea que la prevención eficaz de actos graves —desde redes de narcotráfico transnacional hasta celdas terroristas— depende de transformar datos en conocimiento accionable, y conocimiento en decisiones que prioricen recursos, operaciones y políticas públicas. Analizaremos por qué ese enfoque resulta hoy imprescindible, cómo se ha desarrollado internacionalmente, qué lecciones arroja su aplicación práctica y qué desafíos y oportunidades presenta para Argentina.

.
El crecimiento y la convergencia de amenazas
En la última década el paisaje global delictivo ha mostrado dos tendencias persistentes y peligrosas: la expansión de mercados ilícitos —especialmente de estupefacientes sintéticos y cocaína— y la sofisticación de las organizaciones criminales transnacionales. El informe mundial sobre drogas de la ONU documenta incrementos significativos en la producción y en las rutas de salida de estupefacientes, lo que multiplica recursos, redes y violencia asociada. Al mismo tiempo, organismos internacionales de policía constatan la intensificación de modalidades delictivas como el fraude en línea, el lavado de activos y la ciberdelincuencia, fenómenos que refuerzan la capacidad operativa de las organizaciones ilícitas.
Paralelamente se observa una convergencia entre crimen organizado y terrorismo: alianzas puntuales para financiación, utilización de rutas de contrabando o tecnologías compartidas, y la imbricación funcional cuando actores violentos recurren a actividades criminales para sostenerse. En América Latina este nexo ha sido objeto de análisis y alerta por parte de organizaciones académicas y de cooperación (a nivel global UNICRI; en Argentina: ISSP, IUSE, UBA), que describen escenarios donde el intercambio entre grupos armados, carteles y actores ideológicos genera riesgos híbridos complejos.

.
¿Qué es y qué aporta la ILP?
El enfoque ILP articula cuatro bloques operativos: recolección y verificación de información multisectorial; análisis sistemático para detectar patrones y actores; priorización y asignación de recursos sobre objetivos que generan mayor daño social; y toma de decisiones estratégicas y tácticas informadas por inteligencia. A diferencia de la mera vigilancia reactiva, la ILP busca reducir daños agregando valor analítico a la gestión policial: identificar ‘puntos calientes’ (hotspots), redes logísticas, eslabones financieros y vectores tecnológicos que sostienen la amenaza. Esta arquitectura convoca no sólo a unidades policiales sino a toda la comunidad de seguridad —agencias de inteligencia, organismos judiciales, fiscales, aduanas, reguladores financieros y actores privados clave— configurando una red de información y acción.
Modelos y experiencias internacionales
El ILP tiene raíces conceptuales y prácticas en el Reino Unido, donde el National Intelligence Model (NIM) formalizó procesos de priorización y flujo de inteligencia a comienzos de los 2000. Ese modelo inspiró adaptaciones en Estados Unidos —entre ellas la proliferación de fusion centers para articular información entre niveles federal, estatal y local— y en múltiples policías europeas que integraron análisis espacial y temporal en su toma de decisiones. Las experiencias muestran éxitos operacionales —reducción de delitos focales, desarticulación de células logísticas— pero también límites: carencias de gobernanza, problemas de interoperabilidad tecnológica y cuestionamientos de derechos y privacidad en contextos mal regulados.
Un ejemplo ilustrativo es el de la Policía de Kent (Reino Unido), que con un enfoque analítico logró focalizar recursos sobre actores responsables de crímenes de alto impacto y documentó reducciones apreciables en indicadores locales; sin embargo, otras experiencias —como algunas fusiones en Estados Unidos— evidenciaron riesgos de dispersión de objetivos y de información irrelevante si no existe una gobernanza clara.

.
Lecciones y desafíos en el caso argentino
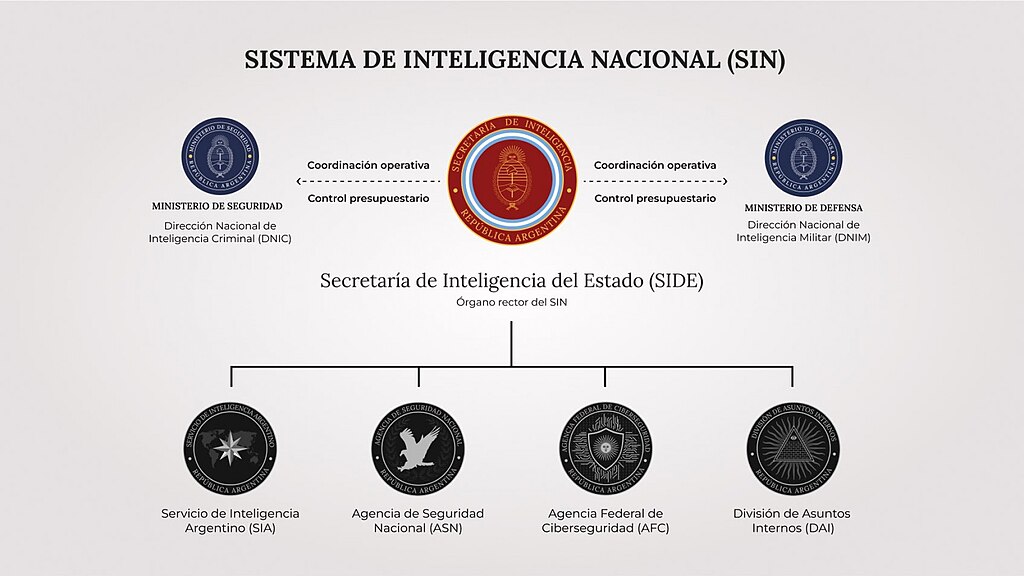
Argentina reúne lecciones dolorosas sobre la necesidad de inteligencia eficaz y responsable. Atentados como los de la Embajada de Israel (1992) y la AMIA (1994) dejaron en evidencia fallas en coordinación, en la cadena investigativa y en mecanismos institucionales de control, con consecuencias públicas y políticas de larga duración. La investigación y las controversias alrededor de esos eventos han moldeado demandas sociales por mayor profesionalización y transparencia en los servicios de inteligencia. Más recientemente, la reestructuración del sistema nacional mediante el Decreto 614/2024 (que disolvió la AFI y reorganizó competencias bajo la nueva Secretaría de Inteligencia de Estado, SIDE) plantea una oportunidad para modernizar procesos, pero exige garantías de controles legales y de respeto a derechos.
Para un país tan extenso como el nuestro, donde las rutas de narcotráfico internacionales utilizan corredores y nodos locales y donde los vacíos institucionales han sido aprovechados por actores ilícitos, la ILP no es un lujo técnico: es una herramienta operativa para romper cadenas logísticas, detectar financiamiento ilícito y prevenir atentados mediante la gestión de riesgos acumulativos.
Comunidad de Inteligencia y Cultura de Inteligencia: dos condiciones necesarias
La Comunidad de Inteligencia en el marco policial implica más que compartir bases de datos: supone acuerdos operativos, protocolos de intercambio, régimen claro de responsabilidades y mecanismos para convertir información en productos analíticos útiles para mandos y fiscales. La gobernanza interinstitucional debe contemplar interoperabilidad técnica, estándares mínimos de calidad y procedimientos de validación.
La Cultura de Inteligencia es el cambio interno que demanda la ILP: valorar el análisis frente a la impulsividad operativa; profesionalizar roles del analista; aceptar errores controlados en la experimentación táctica; y reconocer límites legales y éticos del empleo de información. Sin esa cultura —que se construye con formación, disciplina, incentivos y reglas claras— los sistemas se transforman en archivos inertes o en instrumentos de abuso. Implementar ILP exige por tanto inversión en capital humano, plataformas analíticas y, fundamentalmente, liderazgo que promueva la colaboración sostenida entre agencias y con la sociedad.
Algunas recomendaciones prácticas
1. Consolidar marcos legales y de transparencia que permitan intercambio de inteligencia con salvaguardas de derechos.
2. Implementar modelos de gobernanza interoperable —sobre la base del NIM y experiencias adaptadas localmente— que orienten prioridades nacionales frente a riesgos transnacionales.
3. Fortalecer capacidades analíticas y docentes en la policía y en agencias afines, creando carreras profesionales para analistas y canales ágiles con la fiscalía y la justicia.
4. Desarrollar unidades operativas conjuntas para desarticular nodos logísticos (finanzas, transporte, puertos) y cortar fuentes de financiamiento.
5. Establecer controles civiles y auditorías técnicas que prevengan desvíos y resguarden libertades públicas.
Un llamado a la coordinación
La complejidad y la virulencia de las amenazas no admiten fragmentación institucional ni soluciones aisladas. Argentina necesita consolidar una comunidad de inteligencia profesional, regulada y legitimada, y cultivar una cultura de inteligencia que priorice análisis riguroso, colaboración y respeto por los derechos. La ILP ofrece el andamiaje metodológico: traducir datos en decisiones; priorizar lo que verdaderamente amenaza a la seguridad nacional; y operar con eficacia y control republicano. Pero esa promesa sólo se cumple si el conjunto de actores —gobierno, agencias de inteligencia, fuerzas de seguridad, justicia, organismos de control, sector privado y sociedad civil— coordina tareas, comparte riesgos y asume responsabilidades.
Hoy, la respuesta no puede limitarse a más recursos aislados; exige diseño institucional, formación profesional y voluntad política para integrar saberes y acciones. Convocamos —valorando la seguridad como bien público— a articular un compromiso nacional: modernizar los procesos de inteligencia y contrainteligencia, proteger las libertades, y coordinar con solvencia la lucha contra quienes, desde el crimen organizado o desde el terrorismo, ponen en riesgo la vida y el porvenir de los argentinos. El tiempo de la prevención inteligente es ahora.
Fuente: Ediciones EP, 26/09/25.
Información sobre Gustavo Ibáñez Padilla
Más información:
Inteligencia es anticipación
Antecedentes del Ciclo de Inteligencia de Sherman Kent
La Inteligencia y sus especialidades en la Sociedad del conocimiento

.
.
El importante mensaje de Los tres días del cóndor
septiembre 16, 2025
Por Gustavo Ibáñez Padilla.
La muerte de Robert Redford revive inevitablemente la memoria de una de sus interpretaciones más icónicas: Joseph Turner, el lector y analista de la CIA en Three Days of the Condor (Los tres días del cóndor, 1975). Una película que, bajo el ropaje de un thriller de suspenso, puso en primer plano una figura poco comprendida y muchas veces relegada por el imaginario popular: la del Analista de inteligencia, el eslabón clave en la transformación de datos dispersos en conocimiento estratégico capaz de guiar decisiones de vida o muerte.
Lejos del glamour del espía con gabardina, Turner es un lector meticuloso que detecta patrones ocultos en libros, artículos y publicaciones aparentemente inocuas. Su tarea consiste en “leer entre líneas” para identificar tendencias, amenazas y estrategias ocultas. Es decir, hacer aquello que en la jerga se denomina Análisis de inteligencia, el corazón del trabajo que sostiene a los servicios y que, en última instancia, protege a las naciones.

.
El Ciclo de Kent: de la información al conocimiento útil
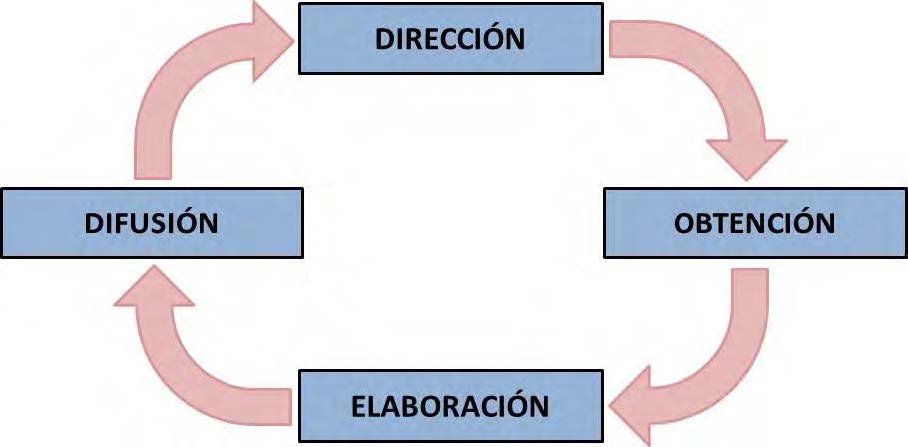
Para comprender el verdadero valor de la labor de Turner, conviene recurrir al clásico Ciclo de Kent, formulado por Sherman Kent, considerado el padre de la inteligencia moderna. Este ciclo describe el proceso continuo por el cual la información se transforma en inteligencia:
─Planeación: se definen las preguntas estratégicas que el decisor necesita responder.
─Obtención: se recolectan datos desde múltiples fuentes, abiertas y secretas.
─Procesamiento: se depura, clasifica y traduce la información.
─Análisis y producción: se interpreta y sintetiza, elaborando escenarios y estimaciones.
─Difusión: el conocimiento llega en forma clara y precisa al decisor.
─Retroalimentación: el ciclo se ajusta a partir de nuevas necesidades o fallos detectados.
En esta cadena, el analista es el alquimista, quien convierte un torrente caótico de datos en conocimiento estructurado. Turner, en la película, descubre un patrón en novelas de espionaje baratas que anticipa una operación clandestina real. Allí reside la metáfora: la inteligencia no se basa en gadgets espectaculares, sino en la capacidad de discernir lo invisible en lo evidente.
.
Inteligencia: mucho más que espionaje
El cine ha contribuido a consolidar la idea de que inteligencia equivale a espionaje. Pero la realidad es más amplia y sofisticada. La inteligencia estratégica busca dotar a los líderes de un mapa preciso de amenazas, riesgos y oportunidades.
Su función no es solo espiar; es comprender. Comprender al adversario, pero también comprender el contexto, las tendencias tecnológicas, los movimientos financieros, los cambios sociales. Inteligencia es tanto la CIA como los equipos de analistas financieros de Wall Street, los especialistas en ciberseguridad de Silicon Valley o las unidades de prevención de delitos en la policía urbana.
El mundo moderno, hiperconectado y saturado de información, multiplica la necesidad de analistas capaces de separar la señal del ruido.

.
La contracara: la Contrainteligencia
Cada disciplina tiene su espejo. En este caso, la Contrainteligencia. Si la inteligencia busca conocer al adversario, la contrainteligencia procura impedir que el adversario nos conozca a nosotros.
Se trata de un entramado de medidas defensivas y ofensivas para proteger secretos, operaciones y vulnerabilidades. Su campo abarca desde la
disciplina del secreto y el principio de necesidad de saber hasta técnicas de engaño, velo y decepción.
En palabras simples: mientras la inteligencia ilumina, la contrainteligencia oscurece. Y ambas se entrelazan en una danza perpetua.
En este punto resulta inevitable recordar a Sun Tzu, quien en El arte de la guerra afirmaba: “Conócete a ti mismo y conoce a tu enemigo y en cien batallas nunca correrás peligro”. La frase condensa la esencia de la inteligencia (conocer al otro) y de la contrainteligencia (conocerse y protegerse a uno mismo). Ambas disciplinas, como hermanas mellizas, forman el núcleo de la seguridad estratégica.
Ejemplos abundan:
─El caso de Aldrich Ames en la CIA y Robert Hanssen en el FBI muestran cómo la contrainteligencia fallida puede desangrar a un sistema entero.
─En contraste, la operación de engaño “Fortitude” durante la Segunda Guerra Mundial, que hizo creer a Hitler que el desembarco aliado sería en Calais
y no en Normandía, es un hito de contrainteligencia exitosa.
La Regla 99/1: cuando todo pasa en un instante
Aquí entra en juego la que yo denomino como Regla 99/1: “En Contrainteligencia y Seguridad, el 99% del tiempo no pasa nada, y en el 1% restante pasa todo”.
La sentencia es tan simple como brutal. Los sistemas de seguridad -estatales, corporativos o personales- enfrentan un dilema estructural: la rutina y la calma prolongada conducen a la relajación. Es humano bajar la guardia cuando nada ocurre durante meses o años. Pero es precisamente en ese instante de descuido cuando se produce la irrupción devastadora: un ataque terrorista, un hackeo masivo, un fraude financiero.

.
Ejemplos recientes lo prueban:
─El 11 de septiembre de 2001, cuando la rutina de seguridad aérea parecía suficiente hasta que no lo fue.
─El ciberataque a SolarWinds en 2020, que permaneció oculto durante meses hasta golpear simultáneamente a múltiples agencias estadounidenses.
─El colapso de Lehman Brothers en 2008, anticipado por pocos analistas que supieron ver más allá de balances maquillados.
La regla 99/1 obliga a sostener la disciplina permanente, incluso cuando nada parece amenazante. Ese es el verdadero desafío de la seguridad moderna.
Conceptos esenciales del oficio
El mundo de la inteligencia y la contrainteligencia se rige por principios técnicos que merecen ser divulgados:
─Disciplina del secreto: restringir el acceso a la información sensible.
─Necesidad de saber: solo quien requiere un dato para su función lo obtiene.
─Sigilo: la capacidad de actuar sin dejar huellas detectables.
─Velo y engaño: generar confusión deliberada en el adversario.
─Decepción: inducir al enemigo a adoptar decisiones equivocadas.
Estos conceptos son aplicables no solo en organismos estatales, sino también en la empresa privada, en la política y hasta en la vida cotidiana.
Desde proteger datos personales hasta evitar caer en una estafa digital, la inteligencia y la contrainteligencia están más cerca de lo que parece.
El legado de Robert Redford y la actualidad del Cóndor
Los tres días del cóndor sigue siendo vigente porque anticipó preguntas que hoy son centrales:
─¿Hasta qué punto los servicios de inteligencia deben actuar sin control democrático?
─¿Puede un simple analista descubrir conspiraciones que los jerarcas prefieren ignorar?
─¿Cómo evitar que la maquinaria del secreto se vuelva contra la propia sociedad que dice proteger?
Robert Redford encarnó al ciudadano común arrojado a un laberinto de poder, secreto y traición. Su personaje recordaba que detrás de cada análisis de inteligencia hay una persona de carne y hueso que debe decidir entre callar o denunciar, entre obedecer o exponer la verdad.
La inteligencia como función vital
La muerte de Robert Redford nos invita a revisitar Los tres días del cóndor, pero sobre todo a reflexionar sobre el rol insustituible de la inteligencia y la contrainteligencia en el siglo XXI.
El mundo vive bajo la ilusión de normalidad el 99% del tiempo, pero basta un 1% para que todo cambie. Solo los sistemas que comprenden esta lógica y mantienen la guardia alta sobreviven.
Por eso, la inteligencia no es un lujo de espías hollywoodenses, sino una función vital del Estado moderno, de las empresas y de los ciudadanos.
En un entorno marcado por la incertidumbre, la hiperconexión y la fragilidad, aprender a pensar como un analista de inteligencia puede marcar la diferencia entre la seguridad y el desastre.
La lección es clara: la inteligencia protege, la contrainteligencia preserva, y ambas son indispensables para la libertad, la soberanía y la vida misma. Hoy más que nunca, es momento de tomarlas en serio.
.
Fuente: Ediciones EP, 16/09/25.
Información sobre Gustavo Ibáñez Padilla
Más información:
Inteligencia es anticipación
Antecedentes del Ciclo de Inteligencia de Sherman Kent
La Inteligencia y sus especialidades en la Sociedad del conocimiento
La Regla 99/1: el uno por ciento que puede cambiarlo todo
______________________________________________________________________________

______________________________________________________________________________
Vincúlese a nuestras Redes Sociales: LinkedIn YouTube Twitter
______________________________________________________________________________

.
.
Vivir en un mundo incierto y complejo
abril 1, 2025
Por Redacción EP.
Vivimos en un mundo que se caracteriza por su volatilidad, incertidumbre, complejidad y ambigüedad (VICA). Estos rasgos no solo afectan nuestras decisiones individuales, sino también las políticas públicas, la gestión empresarial y las relaciones sociales. En este entorno, la seguridad constituye un pilar fundamental para garantizar la paz y la libertad en todos los ámbitos de nuestra vida: la familia, el barrio, la empresa y la sociedad en general. Pero la seguridad no es un concepto que pueda delegarse únicamente en especialistas; debe ser un esfuerzo colectivo que se apoya en la autonomía personal y la educación integral.
.
Para lograr esta autonomía, es crucial comprender y aplicar los principios de seguridad, inteligencia y contrainteligencia. La inteligencia nos permite conocer y analizar el entorno, identificar patrones y prever posibles riesgos. La contrainteligencia, por su parte, nos ayuda a detectar y neutralizar amenazas antes de que estas se materialicen. Como ejemplo, imaginemos a un empleado de limpieza en una Refinería de petróleo que observa comportamientos sospechosos en un proveedor y alerta al personal de seguridad. Esa simple acción podría prevenir un sabotaje o un atentado. Esto ilustra cómo la seguridad no es solo responsabilidad de un grupo especializado, sino un esfuerzo colectivo donde cada individuo juega un rol clave.

.
En Argentina, la implementación de estrategias basadas en estos conceptos enfrenta obstáculos significativos. Históricamente, la formación en seguridad, inteligencia y contrainteligencia ha estado relegada a un segundo plano en las instituciones académicas y en la formación profesional. El Equipo de Estudios en Seguridad Humana y Multidimensional, que cuenta con la participación de la Universidad del Museo Social Argentino (UMSA) y la Fundación FIDES, busca cerrar esta brecha. Este grupo interdisciplinario, coordinado por el Lic. Julio Fumagalli Macrae y el Ing. Gustavo Ibáñez Padilla, propone crear espacios de aprendizaje que formen profesionales con una visión integral de la seguridad.
Esta perspectiva incluye disciplinas como seguridad corporativa, inteligencia criminal, resolución de conflictos, planeamiento estratégico y protección ambiental, entre otras. La consulta y colaboración de renombrados expertos asegura una base sólida para abordar las amenazas contemporáneas. Como destacó el filósofo y estratega militar chino Sun Tzu: “La seguridad suprema consiste en desbaratar los planes del enemigo; no en derrotarlo por la fuerza”. Esta idea subraya la importancia de la prevención y la inteligencia en lugar de depender exclusivamente de respuestas reactivas.
La seguridad humana y multidimensional no es solo un concepto teórico; es una necesidad práctica en un mundo donde las amenazas están en constante evolución. Desde el cibercrimen hasta las catástrofes naturales, las problemáticas actuales requieren soluciones integrales que aborden las vulnerabilidades de las personas, las comunidades y las instituciones. La colaboración entre los sectores académico, público y privado es esencial para desarrollar estrategias que no solo mitiguen riesgos, sino que también fomenten la resiliencia.
Un punto crítico en este debate es la falta de formación en habilidades básicas de seguridad para todos los ciudadanos. En un contexto tan impredecible como el actual, no podemos permitirnos depender exclusivamente de especialistas. Cada individuo debe ser capaz de reconocer señales de advertencia, evaluar riesgos y actuar en consecuencia. Por ejemplo, el entrenamiento en seguridad podría ayudar a los empleados de una empresa a identificar irregularidades en el comportamiento de colegas o visitantes, contribuyendo a la prevención de fraudes o accidentes.
Además, la autonomía personal basada en estos principios fortalece el tejido social. Una comunidad informada y proactiva puede hacer frente a crisis con mayor eficacia, desde inundaciones o incendios hasta incidentes de seguridad. Parafraseando al filósofo estoico Epicteto: La experiencia no es lo que te sucede, sino lo que haces con lo que te sucede. Esta reflexión invita a tomar responsabilidad por nuestra preparación y capacidad de respuesta ante los desafíos.
Un aspecto clave para fomentar esta autonomía es la educación. Incorporar contenidos sobre seguridad, inteligencia y contrainteligencia en los programas educativos y de formación profesional es un paso indispensable. Además, las organizaciones también deben invertir en capacitación continua para sus empleados, asegurándose de que todos cuenten con las herramientas necesarias para identificar y mitigar riesgos. Esta inversión no solo protege activos tangibles, sino también fortalece la confianza y la cohesión dentro de las organizaciones.
En última instancia, construir una cultura de seguridad exige un cambio de mentalidad. Debemos pasar de una visión reactiva a una proactiva, donde la prevención sea la prioridad. Esto implica reconocer que la seguridad no es un gasto, sino una inversión en nuestro bienestar y estabilidad a largo plazo. Además, la colaboración entre individuos, comunidades y organizaciones es esencial para enfrentar un futuro incierto.
Para cerrar, es vital reflexionar sobre el papel que cada uno de nosotros puede desempeñar en este proceso. Como dijo Nelson Mandela: “La educación es el arma más poderosa que puedes usar para cambiar el mundo”. No subestimemos el poder de la información y el aprendizaje. Todos tenemos la capacidad de contribuir a un entorno más seguro si tomamos la decisión consciente de prepararnos y actuar.
La invitación es clara: asumamos la responsabilidad de nuestra propia seguridad y la de quienes nos rodean. Invirtamos en educación, promovamos el aprendizaje colectivo y trabajemos en conjunto para construir un futuro más seguro. El mundo VICA puede parecer desalentador, pero con autonomía, inteligencia y colaboración, podemos transformarlo en una oportunidad para crecer y prosperar.
Fuente: Ediciones EP, 24/01/25.
Más información:
Vaca Muerta: La joya y su vulnerabilidad
La Seguridad Personal y Familiar en el Siglo XXI
Seguridad Humana Multidimensional: Una clave para enfrentar los retos contemporáneos
Protección de Objetivos de Valor Estratégico: Análisis y propuestas al nuevo marco jurídico – Decreto 1107/24.
Ciclo de Lanzamiento 2024 del Equipo de Estudios en Seguridad Humana y Multidimensional:

.
.
.
.
La Seguridad Personal y Familiar en el Siglo XXI
octubre 10, 2024
Por Gustavo Ibáñez Padilla.
En un mundo volátil, incierto, complejo y ambiguo, cada vez más interconectado y con crecientes amenazas, la seguridad personal y familiar ha dejado de ser una preocupación limitada a contextos de guerra o conflicto. Hoy, los peligros provienen de diferentes frentes: gobiernos autoritarios, grupos de poder con intereses ocultos y delincuentes organizados. Analizaremos en forma simple cómo proteger a nuestros seres queridos, recurriendo a conceptos clave de Inteligencia, Contrainteligencia y Seguridad, y revelaremos la paradoja de que los sistemas digitales modernos, aunque avanzados, presentan vulnerabilidades más profundas que los métodos físicos antiguos.
Seguridad Personal y Familiar: Más allá del reflejo inmediato
La seguridad personal y familiar abarca todas aquellas acciones y estrategias destinadas a proteger la vida, la integridad y los bienes de una persona y sus seres queridos. Tradicionalmente, esta seguridad estaba asociada a la protección física: cerraduras, guardias, alarmas. Sin embargo, en la actualidad, los riesgos se han expandido. Las amenazas no solo son tangibles, sino que pueden ser digitales, económicas, sociales y hasta psicológicas.
Uno de los primeros pasos hacia una protección efectiva es la planificación estratégica. No se trata solo de reaccionar ante el peligro, sino de preverlo. Según el exagente de la CIA, Jason Hanson, la clave para la seguridad es “no ser un blanco fácil”. Hanson subraya que la discreción y el evitar patrones predecibles pueden reducir significativamente el riesgo. Por ejemplo, alternar las rutas de camino al trabajo, no compartir ubicaciones en redes sociales y ser cuidadoso con la información que se da en línea.

Inteligencia: Saber es Poder
La Inteligencia, en términos estratégicos, se refiere a la capacidad de recopilar información útil y transformarla en conocimiento, para decidir en forma eficaz, identificando amenazas potenciales antes de que se materialicen. Se trata de un concepto que abarca desde el espionaje estatal hasta la protección personal.
Para aplicar esta noción en la vida diaria, se pueden observar ejemplos en figuras como Warren Buffett, quien no solo es famoso por su habilidad como inversor, sino por ser meticuloso en su gestión de riesgos. El Oráculo de Omaha ha señalado que su éxito no radica en tomar decisiones impulsivas, sino en recopilar y procesar la mayor cantidad de datos posible antes de actuar. De manera similar, para garantizar la seguridad personal, es esencial estar informado de lo que sucede en el entorno. Un seguimiento adecuado de las tendencias locales, la vigilancia de cambios en el comportamiento de personas cercanas o incluso prestar atención a las señales de problemas en la comunidad pueden actuar como barreras protectoras.
Contrainteligencia: Proteger las personas, los bienes y la información
Si la Inteligencia se centra en recopilar y analizar información, la Contrainteligencia busca protegerla de actores malintencionados. En el ámbito personal, la contrainteligencia puede aplicarse de múltiples maneras: desde la protección de los datos financieros hasta evitar que terceros accedan a información sensible sobre nuestra vida.
Un ejemplo ilustrativo es el caso de Edward Snowden, quien expuso la capacidad de los gobiernos para acceder a datos personales sin el conocimiento de los ciudadanos. Snowden demostró cómo actores estatales pueden utilizar sistemas modernos para espiar a los individuos y al hacerlo doblegó a la contrainteligencia del Estado. En respuesta a estas amenazas, expertos en seguridad digital como Bruce Schneier recomiendan prácticas básicas de contrainteligencia, como el uso de comunicaciones cifradas, contraseñas robustas y la adopción de tecnologías que impidan el rastreo no autorizado.
La Paradoja de los Sistemas Modernos
Es curioso observar cómo los avances tecnológicos han facilitado la vida, pero al mismo tiempo han creado nuevas vulnerabilidades. En un pasado no tan lejano, la seguridad dependía en gran medida de barreras físicas: muros, llaves y vigilancia. Sin embargo, los sistemas de seguridad actuales, altamente digitalizados, a menudo presentan un talón de Aquiles: la interconectividad. La ironía radica en que, mientras más avanzados son estos sistemas, más puntos de acceso vulnerables pueden existir.
La Ciberseguridad es un campo que ejemplifica esta paradoja. Tomemos el caso de la empresa Target -una enorme cadena minorista norteamericana- en 2013, donde piratas informáticos comprometieron los datos de más de 70 millones de clientes, provocando pérdidas de más de 60 millones de dólares. El ataque se realizó aprovechando una brecha en el sistema de facturación digital. Este incidente demostró que, aunque los sistemas digitales parecen invulnerables desde fuera, sus estructuras internas pueden ser explotadas.
Comparativamente, los sistemas físicos antiguos, aunque rudimentarios, no dependían de la interconectividad y, por lo tanto, eran menos vulnerables a los ataques a distancia. La facilidad con la que se puede acceder a datos o controlar sistemas modernos desde cualquier parte del mundo pone en tela de juicio si realmente hemos avanzado en términos de seguridad.
Defensas Pasivas: La Protección Automática
Una de las estrategias más efectivas para proteger tanto a las personas como a sus bienes son las defensas pasivas. Estas son medidas que funcionan sin intervención humana, protegiendo de manera continua y automática. Un buen ejemplo son las cámaras de seguridad, las cuales operan día y noche, registrando todo sin necesidad de supervisión constante.
El experto en seguridad, Gavin de Becker, autor de The Gift of Fear, señala que las defensas pasivas son cruciales porque permiten una protección sin que las personas estén conscientes de su activación. Sistemas como cerraduras electrónicas, sensores de movimiento y ventanas a prueba de balas son barreras que, en caso de un ataque, pueden retrasar o detener al agresor antes de que siquiera se den cuenta.
Un ejemplo de la vida real son las propiedades de alto perfil, como las mansiones de celebridades, que suelen incorporar este tipo de defensas. Kim Kardashian, por ejemplo, después de sufrir un violento asalto en París, reforzó significativamente la seguridad de su hogar, implementando una serie de barreras automáticas, desde vallas eléctricas hasta detectores infrarrojos.
Las ventajas de estos sistemas radican en su permanencia y constancia. Mientras que la seguridad activa, como los guardias de seguridad, puede fallar o distraerse, las defensas pasivas siempre están operativas. Además, pueden ser una medida disuasoria para potenciales agresores, quienes al percibir estos sistemas optan por no arriesgarse.

La mejor muralla de protección
El mejor sistema pasivo de defensa lo constituye la Familia, hoy denostada y dejada de lado por la sociedad globalista -que pretende destruirla-. Desde tiempos inmemoriales la familia constituyó el soporte vital y defensivo de todas personas en todos los ámbitos. Tengamos en cuenta que los hombres no viven aislados, son seres sociales y la familia es el ladrillo básico de la sociedad. Nuestras familias nos brindan alimentación, vivienda, educación, ayuda financiera y cuidado -tanto en la salud como en la enfermedad, en la infancia o en la vejez-. Nuestros seres queridos siempre estarán a nuestro lado y son nuestra mejor estrategia de desarrollo, seguridad y protección.
Una persona sola es mucho más vulnerable que una rodeada por sus familiares. En Argentina, recordamos como triste ejemplo el asesinato del fiscal Alberto Nisman. Como contracara podemos ver que muchas organizaciones criminales -por ejemplo la mafia italiana- se basan en estructuras consolidadas por lazos de sangre para mantenerse inexpugnables.

Un futuro seguramente vigilante
El desafío en la era moderna no es solo identificar y neutralizar las amenazas, sino hacerlo de manera eficiente, sin comprometer la privacidad y el bienestar. En este sentido, la inteligencia y la contrainteligencia juegan un rol crucial en la defensa personal y familiar. Los sistemas de seguridad digital, aunque avanzados, deben ser complementados con medidas físicas y defensas pasivas que proporcionen una protección integral.
Un enfoque preventivo es clave: informarse, implementar tecnología segura, y sobre todo, no depender únicamente de sistemas sofisticados que, aunque impresionantes, pueden ser vulnerables. Para proteger a nuestras familias, es esencial contar con una combinación de estrategias de seguridad, tanto digital como física.
Todo lo relacionado con la seguridad y la contrainteligencia está regido por la Regla 99/1: el 99% del tiempo no pasa nada y en el restante 1% del tiempo pasa todo. Es preciso recordar la parábola evangélica de las vírgenes prudentes y las insensatas, siempre hay que mantenerse alerta y vigilante.

Mateo 25:1-13
Una Taxonomía del concepto Inteligencia
septiembre 13, 2024
El término inteligencia proviene del latín intelligentia, que a su vez deriva de inteligere. Esta es una palabra compuesta por otros dos términos: intus (“entre”) y legere (“escoger”). Por lo tanto, el origen etimológico del concepto de inteligencia hace referencia a quien sabe elegir: la inteligencia posibilita la selección de las alternativas más convenientes para la resolución de un problema. De acuerdo a lo descrito en la etimología, un individuo es inteligente cuando es capaz de de escoger la mejor opción entre las posibilidades que se presentan a su alcance para resolver un problema.
Tipos de Inteligencia
Por Rafael Jiménez.
Análisis GESI, 43/2018
Resumen: El tratamiento de cualquier materia induce muy pronto a clasificar todas sus formas o modalidades. Este hecho es más acusado cuando se trata de una materia como la inteligencia, cuya aparición en el dominio público es relativamente reciente, aunque su práctica se remonte al principio de los siglos.
Este capítulo relaciona una amplia taxonomía de la inteligencia, que abarca las dimensiones que puede presentar (a qué se puede referir el concepto inteligencia: producto, proceso u organización); las clases que puede presentar el producto según el nivel de decisión de sus destinatarios; la identificación de ese mismo producto según su finalidad; los tipos de dicho producto según la necesidad de información que satisface; las formas de determinar el producto según el medio en el que se encuentre la información de la que parte; la identificación del mismo producto en función del método de obtención de la información de partida; las modalidades de la inteligencia según el territorio sobre el que se elabora; y cómo se la puede identificar en función de la materia o campos del conocimiento.
*****
1. Dimensiones de la inteligencia
Antes de abordar la clasificación de los tipos de inteligencia es preciso referirse a las dimensiones o conceptos que se pueden expresar con el término inteligencia.
El primero que lo hizo, siempre referido a la inteligencia como componente de la seguridad nacional, fue Sherman Kent en 1949[1], que identificó el término con tres conceptos: a) el producto derivado de la transformación de la información y el conocimiento en inteligencia; b) la organización que realiza esta tarea; y c) el procesomediante el que se lleva a cabo.

La inteligencia como producto es el resultado que se obtiene al someter los datos, la información y el conocimiento a un proceso intelectual que los convierte en informes adecuados para satisfacer las necesidades de los decisores políticos, militares, policiales, empresariales, etc., así como para proteger a aquellos mediante las tareas de contrainteligencia.
La inteligencia como proceso comprende los procedimientos y medios que se utilizan para definir las necesidades de los decisores, establecer la búsqueda de información, su obtención, valoración, análisis, integración e interpretación hasta convertirla en inteligencia, y su difusión a los usuarios. También incluye los mecanismos y medidas de protección del proceso y de la inteligencia creada por medio de las actividades de contrainteligencia necesarias.
La inteligencia como organización se refiere a los organismos y unidades que realizan las anteriores actividades de transformar la información en inteligencia y la protegen.
2. La Inteligencia según el nivel de decisión
Una vez determinado el concepto de inteligencia como producto, su contenido puede referirse a materias políticas y generales del Estado o más detalladas. Por tanto, en función del nivel de decisión del usuario para quien se elabora, la inteligencia puede ser de los siguientes tipos:
2.1. Inteligencia nacional
Es la que precisa el Gobierno de la Nación para definir y desarrollar su política en el más alto de sus niveles de decisión. La inteligencia nacional la elaboran los servicios de inteligencia de nivel nacional, cuya dependencia funcional suele ser del Presidente del Gobierno, aunque administrativamente estén adscritos o integrados en algún departamento ministerial.
2.2. Inteligencia departamental
Es la que necesitan los titulares de los distintos Ministerios del Gobierno de la Nación para ejecutar la política de sus respectivos departamentos. La elaboran los servicios de información e inteligencia dependientes de los respectivos departamentos ministeriales, cuyos productos tienen una aplicación directa en la ejecución de las correspondientes políticas ministeriales. A diferencia de la inteligencia nacional, que se elabora para decisores externos, la departamental constituye un insumo propio de los titulares y altos cargos de los Ministerios en su responsabilidad de ejecución de la política ministerial, así como de los mismos servicios que la elaboran.
2.3. Inteligencia operativa
Es la inteligencia que se genera y se utiliza para planear y ejecutar cualquier tipo de operaciones, tanto de carácter militar como policial o de inteligencia. Su nivel de elaboración y utilización es el más elemental y tiene una aplicación directa en el desarrollo de las operaciones de cualquier organismo o unidad.
3. La inteligencia según su finalidad
De forma similar a la que se ha definido anteriormente según el nivel de decisión del usuario para quien se elabora la inteligencia, esta puede tener distintas finalidades, que permiten clasificarla de la siguiente manera:
3.1. Inteligencia estratégica
Es la inteligencia que se elabora para facilitar la definición de los objetivos de la política y los planes generales de un Estado, para lo que debe tenerse en cuenta el entorno en que se encuentra y las metas que ha fijado el Gobierno.
Para ello, la inteligencia estratégica debe identificar los actores que intervienen en ese entorno, sus características y cómo pueden evolucionar. De esta manera presta una atención especial a los indicios que pueden significar riesgos y derivar en amenazas, o proporcionar oportunidades para la Nación.
La inteligencia estratégica se halla muy vinculada a la prevención y a la prospectiva, advirtiendo de amenazas a los intereses vitales de la seguridad nacional y de las oportunidades para el Estado, con lo que se convierte en la principal herramienta en poder de los gobernantes para diseñar y desarrollar las políticas exterior y la de seguridad nacional.
En el ámbito militar, la inteligencia estratégica tiene como finalidad facilitar la elaboración de los planes relativos a la conducción de las operaciones de nivel estratégico.
En el ámbito empresarial, la inteligencia estratégica tiene la finalidad de facilitar la toma de decisiones de sus directivos ante las amenazas o riesgos para la empresa, o aquellas que puedan facilitar un éxito u oportunidad de desarrollo. En concreto, se especializa en el análisis de los competidores para entender sus éxitos futuros, estrategias actuales, la posible evolución industrial y comercial, y sus capacidades. También incluye la inteligencia sobre los principales clientes, proveedores y socios.
Un caso particular de la inteligencia estratégica lo constituye la denominadainteligencia de alerta, que es la que tiene por finalidad prevenir al usuario de las amenazas contra los intereses nacionales o empresariales, para que pueda decidir con tiempo las medidas políticas, diplomáticas, militares, económicas, industriales, comerciales o de cualquier otro tipo que puedan neutralizarlas o hacerles frente.
3.2. Inteligencia táctica
La inteligencia táctica es la que se elabora para contribuir a la planificación y el diseño de las acciones concretas que permitan alcanzar un objetivo de alcance limitado, subordinado a los grandes objetivos de la inteligencia estratégica.
En el ámbito militar, la inteligencia táctica está destinada a la elaboración de los planes que permitan la conducción de las operaciones tácticas.
En el ámbito empresarial tiene un carácter más operacional, al consistir en la adopción de acciones concretas para conseguir un objetivo en una situación inmediata. Incluye aspectos como los términos de venta de los competidores, sus políticas de precios y los planes que tienen para cambiar la forma en que se diferencian sus productos de los propios.
3.3. Inteligencias operativa y operacional
La inteligencia operativa es la que se elabora para permitir la organización y ejecución de acciones para el cumplimiento de una misión, entendiendo por esta la que le es encomendada a un oficial de inteligencia, solo o dirigiendo un grupo, para lograr un propósito determinado.
En el ámbito militar, el término apropiado es inteligencia operacional y se encuentra en una posición intermedia entre la estratégica y la táctica. Su elaboración tiene como finalidad apoyar la planificación y la realización de campañas en el teatro de operaciones, en el nivel operativo.
3.4. Inteligencia prospectiva
La inteligencia prospectiva se inicia a partir de la inteligencia estratégica y está orientada a determinar de modo anticipado las opciones de evolución de una situación y las posibilidades y probabilidades de actuación de los elementos involucrados en ella, con objeto de reducir la incertidumbre por el futuro en entornos caracterizados por la complejidad, el cambio y la inestabilidad.
El término de inteligencia prospectiva se emplea específicamente para precisar los objetivos estratégicos de una organización y planificar las acciones necesarias para lograrlos. Asimismo, se utiliza para adoptar decisiones que contribuyan a conducir una realidad determinada hacia un escenario futuro deseable.
Tiene un alto componente de estimación, por lo que también se la conoce comointeligencia estimativa o predictiva.
Se trata de una inteligencia muy compleja y costosa, por la necesidad de contar con especialistas instruidos en las técnicas de la prospectiva y en los diversos campos que influyen en el futuro de una organización, así como por la necesidad de contar con tiempo para elaborarla. Ambas circunstancias condicionan de tal modo su generación que no es habitual que se elabore en las organizaciones ni servicios de inteligencia, más ocupados por los demandantes en elaborar inteligencia actual y de inmediato futuro.
4. La inteligencia según la necesidad de información que satisface
La elaboración de inteligencia se produce como consecuencia de la aparición de un requerimiento concreto, sea de los potenciales usuarios o del propio servicio de inteligencia que debe elaborarla. De esta forma, la inteligencia puede ser:
4.1. Inteligencia básica
La inteligencia básica es la que se produce para satisfacer los requerimientos de inteligencia permanentes y generales de la organización de que se trate.
Se emplea sobre todo para responder a las necesidades de información que se plantean durante la producción de inteligencia estratégica e inteligencia prospectiva o estimativa. Por tanto, se elabora atendiendo a los objetivos estratégicos de la organización. Dado que se convierte en un importante almacén de inteligencia, también se utiliza para atender demandas de información durante la producción de inteligencia táctica, operativa y operacional.
La producción de inteligencia básica se realiza de un modo rutinario y programado a partir de fuentes de información abiertas, generalmente obras de referencia, estados y descripciones generales, guías de seguimiento, etc., como enciclopedias, bases de datos, anuarios, directorios, etc.
Esta inteligencia tiene un grado de permanencia mayor que cualquier otra y a ella se incorpora la que se extrae de la inteligencia estratégica que se ha elaborado durante el desarrollo de la actividad de la organización, por lo que también suele recibir la denominación de inteligencia general de la organización, convirtiéndose en un activo informacional de esta.
4.2. Inteligencia actual
Es la inteligencia que tiene por finalidad satisfacer los requerimientos de inteligencia puntuales y concretos de una organización. Presenta el estado de una situación o de un acontecimiento en un momento dado y puede señalar opciones de evolución en un corto plazo, así como indicios de riesgos inmediatos.
Se emplea principalmente para responder a las demandas de información que surgen durante la aparición de un fenómeno o acontecimiento imprevisto, durante un proceso de toma de decisiones sobre un acontecimiento de interés nacional o durante la planificación y el desarrollo de una misión.
Suele ser la más demandada por los gobernantes, cuyos plazos de previsión y decisión son generalmente cortos.
Como fin complementario, la inteligencia actual pone al día la inteligencia básica y los análisis realizados por la inteligencia estratégica. Esto permite disminuir las necesidades de información durante las gestiones de crisis.
Los productos de la inteligencia actual suelen adoptar la forma de informes específicos para atender una demanda concreta y actual de información; o la de informes breves y periódicos, muchas veces diarios, sobre cuestiones de interés general y frecuente sobre las que los decisores políticos desean mantener un conocimiento permanente.
4.3. Inteligencia crítica
Como un caso particular de la inteligencia actual surge el concepto de inteligencia crítica, que es la que se elabora para satisfacer los requerimientos informativos que se producen durante la gestión de una crisis.
El tiempo dedicado a la obtención y procesamiento de datos e información y a la valoración, análisis, integración e interpretación durante una crisis se reduce al mínimo imprescindible con objeto de dar a conocer el estado de la situación con la máxima urgencia posible, que además suele evolucionar con rapidez. Por tanto, elaborar inteligencia que permita al responsable político tomar decisiones rápidas y acertadas exige tanto disponer de información concreta sobre lo que ocurre como contar con unas buenas reservas de inteligencias básica y actual que permitan contextualizar el sentido de la nueva información disponible y mejorar su comprensión.
Los productos más habituales durante la gestión de crisis son alertas e informes de situación sobre la evolución de los acontecimientos. La forma de materialización de dichos informes se convierte muchas veces en modo de gráficos, mapas, esquemas, croquis, etc., que, convenientemente ilustrados, permiten un rápido conocimiento de dicha evolución de la situación.
En situaciones de crisis puede ocurrir que, ante la perentoria necesidad de tomar una decisión, se suministre información a los responsables sin analizar ni interpretar suficientemente, o con una estimación provisional muy sujeta a la evolución de los acontecimientos. En estos casos se deja a dichos responsables la tarea de valorar la información que se les suministra, en beneficio de la urgencia con que se puede poner a su disposición. Esta excepcionalidad es motivo de debate, por lo que supone de trasladar la responsabilidad del análisis de inteligencia a los decisores políticos, modificando el funcionamiento habitual del ciclo de inteligencia.
5. La Inteligencia según el medio en el que se encuentra la información
La información de partida para la elaboración de inteligencia puede encontrarse en muy diferentes medios, dando lugar a distintos tipos de inteligencia que reciben el nombre de la que haya sido su componente principal. De esta manera, la inteligencia puede clasificarse del siguiente modo:
5.1. Inteligencia HUMINT o de fuentes humanas
Es la que se elabora a partir de información recogida o suministrada directamente por personas. Sus resultados dependen fundamentalmente de la actuación del hombre mediante sus sentidos, ayudándose o no con medios auxiliares (cámaras, grabadoras, fotocopiadoras, etc.).
En los servicios de inteligencia se consideran diversos tipos de fuentes humanas, cuya actividad facilita en algún grado la obtención de información. En el CNI esta diversidad ha dado lugar a la siguiente clasificación:
- Contacto: persona ajena a un servicio de inteligencia al que proporciona información, de modo consciente o inconsciente y de forma ocasional o regular, pero cuya dirección no es posible o conveniente realizar por parte del servicio. Puede recibir algún tipo de contraprestación.
- Informador: persona ajena a un servicio de inteligencia al que proporciona información, de modo consciente o inconsciente y de forma ocasional o regular, bajo la dirección de un miembro del servicio. Suele percibir algún tipo de contraprestación.
- Colaborador: persona ajena a un servicio de inteligencia, que coopera para este, de modo consciente o inconsciente y de forma ocasional o regular, realizando una serie de actividades, dirigidas por un oficial de inteligencia, en beneficio de los cometidos asignados al servicio. También suele percibir algún tipo de contraprestación. Por tanto, se diferencia del informador en que no suele facilitar información, o al menos no es su cometido principal, sino que facilita tareas que debe realizar el servicio.
- Agente: persona ajena a un servicio de inteligencia que realiza alguna actividad abierta o encubierta en beneficio del servicio y bajo la dirección de un miembro del mismo, tras recibir adiestramiento especial. Los agentes se reclutan habitualmente para llevar a cabo o dar asistencia en tareas de obtención de información y en operaciones de contrainteligencia. Normalmente el agente recibe algún tipo de contraprestación. No debe confundirse el tipo de agentecomo fuente humana, con la misma denominación de agente con que se identifica a los miembros de los servicios de inteligencia que realizan actividades secretas, abiertas o encubiertas, generalmente encuadrados en unidades operativas de obtención de información.
La información obtenida a partir de fuentes humanas es muy útil porque puede proporcionar datos imposibles de obtener por otros medios. Para ello es necesario que se encuentren situadas en el lugar y momento adecuados para adquirir esa información, formación suficiente para apreciarla y poseer un buen y oportuno sistema de comunicación para hacerla llegar al servicio.
La obtención de información por medios humanos, para que sea valiosa, debe superar dos momentos críticos: a) la captación o infiltración de la fuente en el lugar donde pueda acceder a la información deseable; y, b) la valoración de la información adquirida por parte del oficial de relación y de los analistas; el primero es responsable de evaluar la fiabilidad de la fuente, de la que debe conocer su formación, capacidades, vulnerabilidades, intereses, posibilidades, condiciones (facilidades y riesgos) en las que actúa, etc.; mientras que los segundos, los analistas que reciban el fruto de su adquisición, son los principales responsables de evaluar la calidad de la información proporcionada, así como de remitir al órgano de obtención donde se encuentre el oficial de relación su valoración de la información recibida y, unida a ella, la percepción sobre la fiabilidad de la fuente que la ha proporcionado.
5.2. Inteligencia OSINT o de fuentes abiertas
Es la que se elabora a partir de información obtenida de recursos informativos de carácter público.
Por fuente abierta se entiende todo documento con cualquier tipo de contenido, fijado en cualquier clase de soporte que se transmite por diversos medios y al que se puede acceder en modo digital o no, puesto a disposición pública, con independencia de que esté comercializado, se difunda por canales restringidos o sea gratuito.
La información que transmiten las fuentes abiertas se caracteriza por su singularidad, su rápido modo de obtención, su fácil actualización, su bajo coste en relación con la procedente de otras fuentes y su adquisición sin correr riesgos. Es un axioma que no se debería recoger información pública mediante medios clandestinos, complejos, arriesgados y costosos en términos económicos y políticos.
La información procedente de fuentes abiertas es la más utilizada para la producción de inteligencia estratégica, inteligencia básica, inteligencia económica e inteligencia científica. Además, esta información es indispensable para analizar adecuadamente la información clandestina.
La actual y creciente reivindicación de la importancia de la información OSINT se debe a la confluencia de dos fenómenos: a) la aparición del concepto de multinteligencia, que rechaza el uso de una única autoridad informativa para crear inteligencia; y b) la ampliación del concepto de seguridad obliga a los servicios de inteligencia a recabar, analizar y evaluar información de índole muy variada y en materias donde las fuentes abiertas son imprescindibles.
Dada la amplitud y variedad de fuentes públicas, la tipología clásica la clasifica del siguiente modo[2]:
5.2.1. Fuentes de información primaria
Son las que contienen información original, de primera mano y que, por tanto, no han recibido ningún tipo de tratamiento. Dentro de este grupo se suele distinguir: fuentes de información primaria editadas, que forman parte de los circuitos habituales de publicación y distribución y cuya existencia queda verificada por procedimientos legales (ISSN, ISBN, NIPO), entre las que destacan los libros, las revistas, las películas o los discos; y las fuentes de información primaria inéditas, que pertenecen a lo que se ha dado en llamar literatura gris, y que está compuesta por tesis doctorales, presentaciones, pre-prints, actas de congresos o informes científico-técnicos, entre otras, que por lo general tienen una visibilidad menor y suelen carecer de control bibliográfico.
5.2.2. Fuentes de información secundaria
Son las resultantes del tratamiento documental de las fuentes de información primaria y proceden de la aplicación de técnicas documentales que proporcionan valor añadido (los resúmenes, la agrupación en clasificaciones de materias, la correspondencia con otros idiomas y, sobre todo, la relación de unos documentos con otros). Entre este tipo de fuentes se encuentran las bases de datos, los catálogos, los repertorios bibliográficos y los repertorios legislativos.
5.2.3. Fuentes de información terciaria
Podrían asimilarse a las fuentes secundarias, pero el Programa General de Información de la UNESCO les atribuye una finalidad específica: la consolidación de la información mediante productos que analizan críticamente el conjunto de unidades documentales propias de una disciplina, extrayendo de cada una de ellas lo más relevante en cuanto a innovación y progreso. Formarían parte de este tipo de fuentes las revisiones (review) y los estados de la cuestión.
5.2.4. Obras de referencia
Son las que fueron ideadas para la consulta puntual de algunas de sus entradas y entre ellas destacan: enciclopedias, diccionarios, anuarios, glosarios, o las modernasFrequently Asked Questions (FAQ).
Además de esta clasificación académica, otras tipologías se fijan en el emisor (fuentes gubernamentales, parlamentarias, judiciales, policiales, académicas, etc.), en el soporte (impresas, audio, video, informáticas, etc.), en el coste (venales o gratuitas), en la periodicidad, en el destinatario o en el grado de especialización (fuentes generales y fuentes especializadas). De esta manera se pueden clasificar las fuentes OSINT de la siguiente forma:
5.2.5. Fuentes de información institucional
Publicaciones oficiales (boletines oficiales, del registro mercantil, etc.), estadísticas, legislación, jurisprudencia, sistemas de seguimiento legislativo, documentación parlamentaria, y documentación emitida por organismos internacionales.
5.2.6. Fuentes de información económica
Estudios de mercado, informes económico-comerciales de países, información sobre contratación pública, etc.
5.2.7. Fuentes de información geopolítica
Barómetros de conflictos, documentos de comités de expertos y de think tanks.
5.2.8. Fuentes de información sociológica
Estudios de opinión pública, participación electoral, flujos migratorios, encuestas demoscópicas, congresos de partidos políticos y sindicatos, etc.
5.2.9. Fuentes de información de seguridad y defensa
Blanqueo de capitales, tráfico ilícito, terrorismo, infraestructuras críticas, corrupción, ciberdelincuencia, etc.
5.2.10. Fuentes de información bibliográfica
Bases de datos bibliográficas.
5.2.11. Fuentes de información de prensa
Editoriales y editorialistas, análisis de la prensa, servicios de seguimiento de medios, recortes (clipping).
5.2.12. Fuentes de redes sociales y páginas web
Monitorización de redes y páginas informáticas.
5.2.13. Fuentes archivísticas
Destinadas a recoger la producción de documentación de las administraciones modernas y de las empresas; están sometidas a procesos de selección y constitución de colecciones.
5.3. Inteligencia SIGINT o de señales
Es la inteligencia que se elabora a partir de la obtención y el procesamiento de datos provenientes de la detección, interceptación y descifrado de señales y transmisiones de cualquier clase. Es un término genérico, pues dada la gran cantidad de posibles orígenes de señales electromagnéticas y acústicas, una primera clasificación de la inteligencia SIGINT puede diferenciar las siguientes:
5.3.1. Inteligencia COMINT o de comunicaciones
Es la inteligencia obtenida a partir de emisiones electromagnéticas de equipos y sistemas de tecnologías de la información y de las comunicaciones (STIC); por ejemplo, ordenadores, impresoras, faxes, teléfonos, télex, líneas de comunicaciones, agendas electrónicas, tarjetas inteligentes, etc.
Un caso particular de inteligencia COMINT lo constituye la inteligencia cibernética o CYBINT[3], que es la inteligencia elaborada a partir de datos, protegidos o no, del espacio cibernético. Este, a su vez, está definido como el espacio virtual compuesto por dispositivos computacionales conectados en red, donde las informaciones digitales se transmiten, son procesadas o almacenadas. Un ejemplo muy claro de inteligencia CYBINT es la que puede obtenerse a partir de datos adquiridos en las redes sociales. La inteligencia cibernética está íntimamente ligada a la de fuentes abiertas.
Cuando las emisiones de las que se obtiene la información son involuntarias o no deseadas por el emisor se denominan TEMPEST, como por ejemplo las emitidas por las líneas de conducción de comunicaciones, los teclados de ordenador, las radiaciones de las pantallas, etc.
5.3.2. Inteligencia ELINT o electrónica
Es la inteligencia obtenida a partir de emisiones electromagnéticas de medios ajenos a las telecomunicaciones (radares, equipos de ayuda a la navegación, perturbadores de sistemas de comunicación, etc.).
Este tipo de inteligencia, a su vez se subdivide en las siguientes clases:
5.3.2.1. Inteligencia RADINT o de emisiones radar
Es la inteligencia que se obtiene a partir de las emisiones de los radares.
5.3.2.2. Inteligencia TELINT o telemétrica
Es la que se obtiene a partir de emisiones de equipos electromagnéticos de telemetría.
5.3.3. Inteligencia MASINT o de medición de señales
Es la que se elabora a partir de la obtención y el procesamiento de datos provenientes de sensores destinados a recoger las señales que emiten fenómenos físicos distintos a las emisiones electromagnéticas, como el sonido, el movimiento, la radiación, etc. Estas señales se denominan firma del equipo o equipos. Los sensores se dedican a identificar toda característica distintiva asociada con la fuente o el emisor y facilitar la detección y la localización de este último.
De acuerdo con la señal que mide se distinguen diversos tipos específicos de medición de señales:
5.3.3.1. Inteligencia ACINT o acústica
Es la inteligencia derivada de la obtención y el análisis de los fenómenos acústicos producidos por cualquier emisor (buque de superficie, submarino, torpedo, aeronave, dron, vehículo terrestre, proyectil, maquinaria, etc.).
5.3.3.2. Inteligencia TELINT o telemétrica
Ya citada anteriormente (ver 5.3.2.2), permite el análisis de la firma de equipos telemétricos, instalados, por ejemplo, en misiles, satélites, armas de precisión, etc.
5.3.3.3. Inteligencia NUCINT o de radiaciones nucleares
Es la que se obtiene a partir de la medición de señales procedentes de radiaciones nucleares (bombas radiológicas o sucias, bombas atómicas, etc.).
5.4. Inteligencia IMINT o de imágenes
Es la inteligencia que se elabora a partir del análisis de imágenes adquiridas por medios técnicos, como cámaras fotográficas, medios de grabación de imágenes, radares, sensores electro-ópticos, visores térmicos o infrarrojos, ubicados en plataformas terrestres, navales, aéreas o espaciales. En este tipo de inteligencia destacan:
5.4.1. Inteligencia GEOINT o geoespacial
La observación geoespacial, identificada como GEOINT, es el resultado de la explotación y análisis de la información de imágenes y geoespacial para describir, valorar y visualizar características físicas y georreferenciar (situar) actividades en el planeta.
5.4.2. Inteligencia PHOTINT o fotográfica
Es el tipo de inteligencia obtenida mediante el análisis e interpretación de la fotografía aérea, realizada por aviones, helicópteros o drones (JSTARS) de detección y seguimiento de objetivos terrestres o móviles provistos de videofotografía y termografía. Los JSTARS son plataformas aéreas (aviones, helicópteros o drones) que disponen de medios de detección, identificación y seguimiento de objetivos terrestres y móviles, así como de medios de comunicación y señalamiento a los vectores de lanzamiento para atacar a dichos objetivos terrestres o móviles (aéreos y navales).
5.5. Inteligencia TECHINT o técnica
Es el tipo de inteligencia que se elabora a partir de la obtención y el procesamiento de información mediante el uso de medios técnicos. Es un término genérico con el que se designa el uso conjunto de datos provenientes de las inteligencias SIGINT e IMINT.
6. La inteligencia según el método de obtención
La inteligencia también puede clasificarse según el método utilizado para obtener los datos y la información que le sirven de base. Las denominaciones de estos tipos de inteligencia coinciden con los descritos en el punto anterior, excepto que no existe inteligencia OSINT, sino que esta puede obtenerse por métodos HUMINT, SIGINT o IMINT, o varios de ellos simultáneamente.
De esta manera, se pueden clasificar los procedimientos de obtención de información según el método utilizado para su adquisición y según el medio en que se encuentra, dando lugar a la siguiente tabla comparativa:
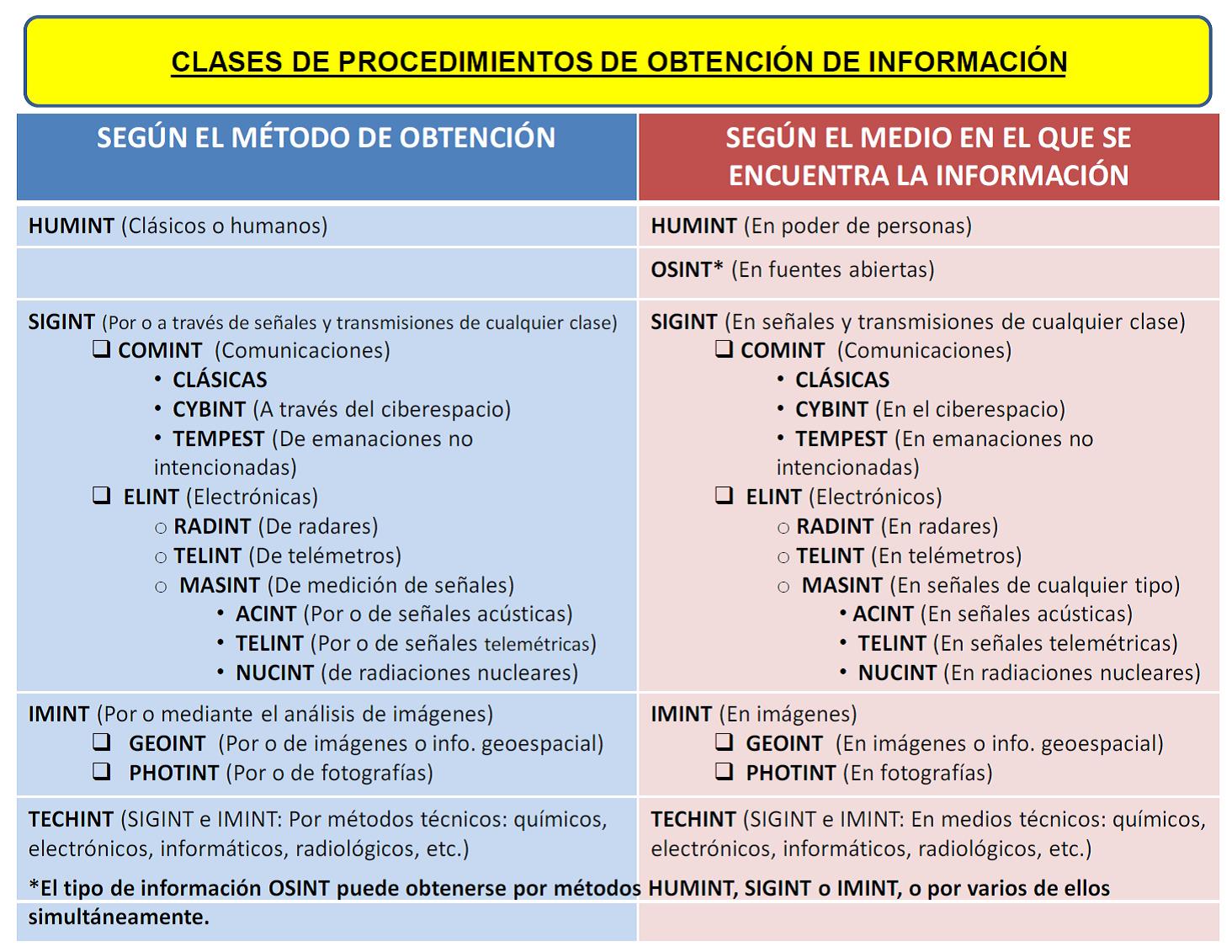
La inteligencia según el método de obtención y comparación con el medio en el que se encuentra la información que le dará nombre: procedimientos de obtención de información.
La inteligencia que se elabora con la información obtenida según un método o contenida en un medio determinado adquiere el mismo nombre. Por ejemplo, la inteligencia elaborada a partir de información obtenida, única o predominantemente, por métodos o en medios HUMINT se denomina Inteligencia HUMINT.
7. La Inteligencia según el territorio sobre el que se elabora
Aunque las amenazas sean globales, los servicios de inteligencia pueden especializar sus tareas en el territorio nacional o fuera de él, dando lugar a una nueva clasificación de la inteligencia por el lugar sobre el que se elabora. Asimismo, la cada vez mayor intervención de organismos multinacionales en misiones internacionales de mantenimiento de la paz ha obligado a generar un tipo de inteligencia específico, adaptado a las necesidades de las misiones abordadas, en el que intervienen varios de los servicios de inteligencia de los países que conforman dichos organismos multinacionales.
Generalmente, los países desarrollados tienden a contar con dos o más servicios de inteligencia de nivel nacional, mientras que la mayor parte de los países sólo cuentan con uno que atiende las necesidades del Gobierno de su país en todo el mundo. Una clasificación de la inteligencia según el territorio del que se ocupa es la siguiente:
7.1. Inteligencia interior
Es el tipo de inteligencia que se ocupa de identificar y seguir la evolución de los riesgos y amenazas a la seguridad procedentes del interior del Estado al que pertenece el servicio de inteligencia, con el fin de apoyar el proceso de adopción de medidas preventivas o de neutralización por parte del Gobierno.
Para ello, la inteligencia interior centra su atención en la investigación de las intenciones, las actividades y la capacidad de individuos y organizaciones que tienen o pueden evolucionar hacia finalidades desestabilizadoras o de franca agresión al orden político establecido o a los intereses nacionales.
7.2. Inteligencia exterior
La inteligencia exterior se ocupa de identificar y seguir la evolución de los riesgos y amenazas a la seguridad procedentes del exterior del Estado al que pertenece el servicio de inteligencia, con el fin de apoyar la adopción de medidas preventivas o de neutralización por parte del Gobierno, así como las que pueda diseñar para promover los intereses nacionales.
Para ello, la inteligencia exterior centra su atención en la investigación de las intenciones, las actividades y la capacidad de personas, organizaciones y naciones extranjeras que puedan atentar contra la soberanía, el orden político establecido, los intereses nacionales y la integridad territorial. Igualmente, se ocupa de detectar oportunidades favorables para la promoción y defensa de los intereses nacionales fuera de las propias fronteras.
7.3. Inteligencia multinacional
Es el tipo de inteligencia realizada sobre un conjunto de naciones o región geográfica, en la que intervienen servicios de distintos países con una finalidad común, como puede ser la que precisan organizaciones multinacionales, como la OTAN, la Unión Europea, la ONU, los países integrantes del Acuerdo UKUSA, etc. Los servicios que elaboran este tipo de inteligencia reciben el nombre de centros de fusión de inteligencia.
8. La Inteligencia según la materia o campos del conocimiento
Los múltiples campos sobre los que tienen que actuar los servicios y otros organismos que producen inteligencia, permiten identificar una nueva clasificación de su producto en función de la materia o campo del conocimiento sobre el que se centra. De esta forma, se pueden hallar los siguientes tipos de inteligencia:
8.1. Inteligencia geográfica
Es la que procede del estudio de las características naturales y artificiales de un espacio o zona geográfica determinada. Generalmente es complementaria de otros tipos de inteligencia.
8.2. Inteligencia política
Es la que trata la política interior y exterior de los gobiernos y las actividades de los movimientos políticos. En los servicios de inteligencia de nivel nacional ocupa una gran parte de su actividad productora.
8.3. Inteligencia sociológica
Se fundamenta en el conocimiento de la estructura y de todos los factores sociales de una nación o zona determinada.
8.4. Inteligencia militar
Identificada como MILINT, es la que se elabora a partir de la información relativa a naciones extranjeras, fuerzas o elementos hostiles o potencialmente hostiles y áreas de operaciones reales o potenciales. Es un ámbito de la inteligencia propio de las fuerzas armadas, por lo que la información que cobra mayor importancia es la relativa a la doctrina, organización, orden de batalla, capacidades, fuerzas, medios, estrategias y tácticas de fuerzas armadas u organizaciones de cualquier tipo, que empleen o puedan emplear procedimientos militares, hostiles o potencialmente hostiles.
La finalidad de la inteligencia militar es facilitar la toma de decisiones en los procesos de dirección y ejecución de las operaciones militares, disminuyendo las incertidumbres de los jefes y sus estados mayores, proporcionándoles la inteligencia oportuna, pertinente, precisa, predictiva y adaptada sobre el enemigo y otros aspectos del área de operaciones que permitan la planificación, ejecución y conducción de las operaciones.
La inteligencia militar, en el siglo XXI, no es la mera descripción de las fuerzas enemigas, de sus medios y capacidades de combate, sino que consiste también en el entendimiento de su cultura, motivaciones, finalidad y objetivos que persiguen. Es decir, no sólo se debe conocer y entender al adversario, sino que es imprescindible conocer y valorar la población de la que surge o proviene, el apoyo que recibe o puede recibir de ella y el apoyo que pueden recibir las fuerzas propias. Se trata de entender el entorno en el que se realizan las acciones de una operación, el llamado entorno operativo.
8.5. Inteligencia científica y tecnológica
Es la que se ocupa de la obtención y el procesamiento de información de carácter científico y tecnológico en los ámbitos civil y militar de interés para la seguridad. Su finalidad es detectar y efectuar el seguimiento de proyectos y actividades de investigación y de desarrollo científico y tecnológico emprendidos por organizaciones o países extranjeros, que puedan derivar en situaciones de riesgo para la seguridad nacional e internacional, con objeto de poder adoptar contramedidas efectivas. Mediante sus análisis puede valorarse el carácter y la capacidad armamentística de posibles adversarios, así como los avances científicos y tecnológicos que pueden derivar en la creación de armas u otros productos susceptibles de representar una amenaza para la seguridad.
La inteligencia científica y tecnológica está ampliando cada vez más su objetivo de atención tradicional, el armamento y los sistemas de armas, para abarcar los campos de las inteligencias económica y competitiva, lo que supone que se ocupe también de la identificación, seguimiento y evaluación de los avances científicos y tecnológicos, dentro de los marcos legales, que se producen en los distintos sectores de interés económico público o privado, con independencia de su posible uso militar.
Una última finalidad de la inteligencia científica y tecnológica lo constituye la que permite adoptar avances tecnológicos ajenos para evitar pasar por largas y costosas etapas previas de investigación.
La inteligencia científica usa de modo intensivo las fuentes de información abiertas, ya que se dedica a vigilar las investigaciones que se realizan en los mundos académico y empresarial antes de que se efectúe su aplicación industrial. En cambio, la inteligencia tecnológica, por estar más relacionada con el seguimiento de las aplicaciones que realizan empresas y organismos públicos de investigación de los conocimientos obtenidos en la investigación básica, también utiliza información procedente del espionaje industrial o de medios técnicos, como la fotografía aérea, la observación por satélite, la cibernética y la interceptación y escucha de señales acústicas.
La inteligencia tecnológica no se debe confundir con la inteligencia técnica (TECHINT), que, como se expresa en el punto 6, es la que se elabora a partir de información obtenida por métodos técnicos (SIGINT e IMINT).
8.6. Inteligencia económica
La creciente integración de los asuntos económicos en el concepto de seguridad ha dado lugar a la necesidad de elaborar inteligencia sobre ellos. Sin que exista unanimidad en el concepto de inteligencia económica, esta puede entenderse como la que se ocupa de la obtención y el procesamiento de la información financiera, económica y empresarial de un Estado para permitir una eficaz salvaguarda de los intereses nacionales, tanto en el interior como en el exterior.
En el mismo ámbito de la inteligencia económica también se incluyen otras acciones complementarias más específicas, como la sensibilización de las empresas nacionales sobre la necesidad de adoptar medidas preventivas contra el espionaje económico, la realización de análisis macroeconómicos de los Estados en los que se pretende invertir o hay inversiones de empresas del país, la protección interna y la promoción y protección externa en el mercado de la industria nacional, el control del tráfico de material de defensa y de doble uso civil y militar, y la creación de una cultura de inteligencia económica.
Las fuentes de información abiertas predominan para la producción de inteligencia económica, pero también se hace uso, cuando es necesario, de información secreta obtenida por medios encubiertos. Esto último es lo que diferencia la inteligencia económica que realizan los servicios de inteligencia y la que producen otros órganos de la Administración o empresas privadas especializadas.
La acepción «inteligencia económica» tuvo su origen en la década de 1970-80 en Francia, entendiéndola como los conocimientos que precisan el Estado o las empresas para alcanzar sus objetivos estratégicos. El Informe Martre[4] (1994), enfocado esencialmente al desarrollo de la inteligencia económica y estratégica de las empresas, definió la inteligencia económica como «el conjunto de acciones coordinadas de investigación, tratamiento y distribución, en vista a su explotación, de la información útil a los actores económicos −ya sean empresas u organizaciones estatales−. Informaciones que se han de aportar mediante métodos legales, con todas las garantías de protección necesarias para preservar el patrimonio empresarial en las mejores condiciones de coste y marco temporal».
La inteligencia económica «implica ir más allá de acciones parciales provenientes del análisis documental, de acciones de vigilancia, de la protección del patrimonio competitivo, de acciones de influencia, etc., para lograr una intencionalidad estratégica y táctica»[5]. De esta forma se entronca con la estrategia y su puesta en acción (táctica), y es el elemento esencial de investigación e interpretación de las intenciones y capacidades de los competidores, ya sea como defensa de la posición actual del Estado o empresa que la practica, o como medio para obtener una supremacía concreta de acuerdo con los intereses estratégicos. La inteligencia económica, por tanto, se apoya en la vigilancia del entorno competitivo, diferenciándose de otros procesos o sistemas de inteligencia en tres elementos principales: sus fines son exclusivamente económicos; trabaja con fuentes abiertas; y debe ser ética en todas sus acciones.
No obstante estas descripciones de la inteligencia económica en sus orígenes, en el presente siglo se ha empezado a determinar la inteligencia económica como la obtenida a partir de información financiera, económica y empresarial de un Estado, diferenciándola de la competitiva o empresarial, que la realizan las empresas. De esta forma, la inteligencia económica la llevan a cabo tanto los servicios de inteligencia −que utilizan información secreta obtenida por medios encubiertos−, como otros órganos de la Administración, fundamentalmente de los Ministerios de Hacienda y de Economía (o sus órganos adscritos), y empresas especializadas, que sólo utilizan fuentes abiertas.
8.7. Inteligencia competitiva
De la misma forma que se produce con la inteligencia económica, no hay unanimidad en la definición de inteligencia competitiva, que, además, se ha visto identificada en su definición como inteligencia empresarial, como término más moderno que englobaría a la inteligencia competitiva y a la inteligencia de negocios (business intelligence).
El Equipo Económico del CNI definió en 2009 la inteligencia competitiva como «una herramienta de gestión o práctica empresarial que consiste en un proceso sistemático, estructurado, legal y ético, por el que se recoge y analiza información que, una vez convertida en inteligencia, se difunde a los responsables de la decisión para facilitar esta, de forma que se mejora la competitividad de la empresa, su poder de influencia y su capacidad de defender sus activos materiales e inmateriales».
Los objetivos de la inteligencia competitiva son planificar y adoptar medidas para mantener la competitividad de la empresa y afrontar con mayores garantías los rápidos y continuos cambios a los que se ve sometida toda organización. Para lograrlo se ocupa de la obtención y el procesamiento de información sobre los elementos que caracterizan la realidad política, social, económica, cultural, legal y tecnológica que rodea a la empresa y sobre los agentes que actúan en ella. Presta una especial atención a la identificación y el seguimiento de señales indicadoras de cambios significativos en el entorno, por lo que trabaja con datos procedentes del exterior de la organización, que obtiene sobre todo de fuentes de información abiertas.
Por tanto, la diferencia principal entre la inteligencia económica y la inteligencia competitiva es que la económica la realiza el Estado fundamentalmente, mientras que la competitiva la realizan las empresas.
Por otra parte, la diferencia entre la inteligencia competitiva y la de negocios estriba en que la competitiva analiza el entorno de la empresa, utilizando fuentes externas e información abierta; mientras que la inteligencia de negocios se realiza a partir de los datos internos de la propia actividad de la empresa, para mejorar su rendimiento, fidelizar clientes y obtener beneficios.
La práctica de la inteligencia de negocios se basa en el empleo de tecnologías y aplicaciones informáticas que permiten buscar, recuperar, analizar y visualizar de modo unificado datos heterogéneos y dispersos entre diferentes sistemas, con independencia de las aplicaciones empleadas para su creación y almacenamiento y de que estén en ficheros de texto o estructurados en bases de datos. Estas herramientas, haciendo uso de técnicas de minería de información, establecen asociaciones entre los datos y desvelan patrones ocultos, de acuerdo con el cumplimiento de unos criterios estadísticos y preestablecidos, que ayudan a la interpretación. La inteligencia de negocios sirve de apoyo para la gestión de diversas áreas de las empresas, como producción, finanzas, relación con clientes y proveedores, ventas, recursos humanos o logística.
Dentro de la inteligencia competitiva se encuentra incluida la inteligencia de mercados,que se obtiene a partir de la información relevante sobre el mercado en el que la empresa desarrolla su actividad y cuyo fin inmediato es proporcionar conocimiento permanente sobre el mismo, para facilitar el proceso de toma de decisiones al trabajar sobre necesidades específicas de la empresa.
8.8. Inteligencia criminal
También este término concita varias interpretaciones y se presta a confusión con otros conceptos, como inteligencia policial, inteligencia de seguridad pública, investigación criminal, criminología, criminalística, etc.
Inicialmente se entendía como inteligencia policial a la destinada al mantenimiento de la seguridad interior, el orden público y la persecución de la delincuencia. Pero desde finales del siglo XX y en este XXI, la inteligencia criminal abarca un ámbito mucho mayor que el estrictamente policial, al constituir una inteligencia que hoy elaboran, en distintos países, los servicios de inteligencia, las fuerzas armadas, unidades policiales, los servicios de aduanas, el sistema penitenciario, las instituciones financieras e incluso empresas privadas de seguridad.
De esta forma, la inteligencia criminal es un tipo de inteligencia útil para obtener, evaluar e interpretar información y difundir inteligencia necesaria para proteger y promover los intereses nacionales de cualquier naturaleza (políticos, comerciales, empresariales), frente al crimen organizado, al objeto de prevenir, detectar y posibilitar la neutralización de aquellas actividades delictivas, grupos o personas que, por su naturaleza, magnitud, consecuencias previsibles, peligrosidad o modalidades, pongan en riesgo, amenacen o atenten contra el ordenamiento constitucional y los derechos y libertades fundamentales.[6]
En cuanto a su diferenciación con la investigación criminal/policial, también identificada como actividad de policía judicial, la diferencia principal estriba en que esta se realiza al suscitarse un caso y se culmina con los logros investigativos obtenidos, alcanzando su esclarecimiento y resolución, mientras que la inteligencia es permanente; no reacciona ante la comisión de un delito, sino que opera continuamente sobre toda persona, actividad u organización que pueda parecer sospechosa de constituirse en una amenaza o implique un riesgo para la seguridad. Cuando hay ausencia de inteligencia o las medidas que propone no se aplican, el delito ya se ha cometido; el trabajo de inteligencia ha resultado infructuoso y el delito efectivamente materializado pasa a ser objeto de la investigación criminal/policial.
Por consiguiente, la inteligencia no persigue la resolución de un hecho delictivo. No opera en el ámbito de los tipos penales, sino en la esfera de las situaciones predelictuales; intenta aportar conocimiento para anticiparse y permitir a las autoridades neutralizar o disuadir las amenazas, riesgos y conflictos (carácter preventivo). La investigación criminal/policial actúa de forma absolutamente represiva, ya que interviene después de la comisión de un delito específico para identificar a sus autores y aportar las pruebas legales que posibiliten su procesamiento penal.
Otro aspecto que facilita la confusión de los términos lo constituye el hecho de que una misma información puede tener una doble finalidad: constituir indicios y pruebas para descubrir los elementos integrantes del hecho criminal para su enjuiciamiento (investigación criminal/policial), o constituir insumos que empleará el analista de inteligencia, que no el investigador policial, en la elaboración del producto de inteligencia, con independencia del momento exacto en el que se produce el conocimiento, sea este anterior o posterior al hecho delictivo. La afluencia continua de nuevos datos fruto de la comisión de delitos genera la imagen errónea de que siempre se llega tarde, resultando infructuoso cualquier esfuerzo por elaborar inteligencia.
Esta confusión se produce porque la fase de recolección de información para la elaboración de inteligencia (policial y criminal) y la fase de recolección de información, indicios y pruebas de la investigación criminal/policial, en muchas ocasiones discurren de forma simultánea versando sobre los mismos objetivos. Esta circunstancia genera confusos episodios de solapamiento al resultar harto complejo establecer las líneas de demarcación entre ambas, para identificar con nitidez donde empieza una y acaba la otra, por lo que el elemento esclarecedor reside en identificar sus utilidades y fines, que sí están bien diferenciados[7].
Por su parte, la inteligencia de seguridad pública, conocida por el acrónimo CRIMINT, puede definirse como la que sirve para identificar y neutralizar las amenazas reales y potenciales a la seguridad del Estado o a su orden constitucional resultante de actos de subversión, terrorismo y espionaje cometidos por personas, Estados o grupos nacionales o extranjeros. Asimismo, este término se aplica a las actividades de apoyo a las funciones de la policía, el mantenimiento del orden público y de la justicia criminal.
También relacionada con la inteligencia criminal y dentro de la CYBINT (ver punto 5.3.1) se encuentra la inteligencia de medios sociales (SOCMINT), que es la que está referida a las redes sociales y medios de comunicación de plataforma digital y los datos que las mismas generan. Contribuye a la seguridad pública a través de la identificación de actividades criminales, de la alerta temprana sobre desórdenes y amenazas al orden público, o a la construcción de conocimiento inmediato en situaciones rápidamente cambiantes. Es un tipo de inteligencia reciente que precisa un desarrollo legal.
8.9. Inteligencia sanitaria
Conocida como MEDINT y de aplicación fundamentalmente militar, es la que se deriva de la obtención y análisis de los elementos de epidemiología y ambientales en una determinada zona, así como los riesgos nucleares, biológicos, químicos y radiológicos (NBQR) para las fuerzas propias; de las capacidades sanitarias disponibles, propias y adversarias; de la infraestructura sanitaria y del personal sanitario existente en el teatro donde se efectúan las operaciones, tanto para su explotación en beneficio propio, como para la atención de la población civil de futuras zonas ocupadas[8].
8.10. Inteligencia de objetivos
Identificada con el acrónimo inglés TARINT es el tipo de inteligencia que facilita la selección de objetivos militares y realiza la evaluación de daños. En el apoyo a la selección de objetivos, trata de describirlos y situarlos. En caso de un objetivo compuesto por varias partes, o conjunto de blancos, indica sus vulnerabilidades, importancia relativa y la elección más conveniente de medios y momento de ataque para producir los efectos deseados. Los aspectos que deciden el ataque a un objetivo son su facilidad para ser identificado, la importancia relativa para contribuir a obtener el resultado final y el cumplimiento de la misión.
La evaluación de daños proporciona la información necesaria para conocer si se han logrado los efectos deseados.
8.11. Inteligencia psicológica
Conocida como PSYOPS es el tipo de inteligencia necesaria para la planificación, conducción y evaluación de las operaciones psicológicas, que proporciona información relativa a opiniones, creencias, actitudes o aspiraciones de las audiencias objetivo, así como sobre aspectos de carácter político, económico, militar, social y cultural de interés para las operaciones y para determinar los efectos que los productos y actividades de las operaciones psicológicas tienen en las audiencias objetivo.
8.12. Inteligencia sociocultural
Identificada por el acrónimo SOCINT, se elabora a partir de la información sobre asuntos sociales, políticos, económicos y demográficos para comprender las creencias, valores, actitudes y comportamientos de un actor o grupo social determinado, con el fin de prevenir y neutralizar amenazas a la seguridad. Es un tipo de inteligencia complementario de otras.
8.13. Inteligencia cultural
Bajo el acrónimo CULINT se identifica la inteligencia elaborada a partir de información social, política, económica y demográfica que proporciona un conocimiento que permite comprender la forma de actuar y las motivaciones de cualquier tipo de actor (aliado, neutral o enemigo), así como anticipar sus reacciones ante determinados acontecimientos. Analiza su cultura para entender mejor su visión del mundo, sus comportamientos y su forma de tomar decisiones. Ello hace posible interpretar mejor sus acciones y, por tanto, diseñar estrategias de cooperación o reacción mucho más efectivas. Es también un tipo de inteligencia identificado recientemente, que se está desarrollando debido a las cada vez más numerosas actividades multinacionales en respuesta a la globalización de las amenazas.
8.14. Inteligencia holística
Es la que se elabora por cualquier servicio que debe abordar el análisis y la interpretación de un asunto o de una situación con una perspectiva multidisciplinar, integrando información proveniente de múltiples fuentes y realizada por un equipo de trabajo de especialidades y procedencias diversas formado exclusivamente para la ocasión.
El concepto de inteligencia holística es relativamente reciente y está motivado por la continua ampliación del concepto de seguridad y, por tanto, el aumento de la complejidad de los asuntos que atienden los servicios de inteligencia, a lo que cabe añadir la sobreabundancia de información que se obtiene por medios técnicos.
Rafael Jiménez Villalonga es Emérito del Centro Nacional de Inteligencia y profesor delMáster on-line en Estudios Estratégicos y Seguridad Internacional de la Universidad de Granada.
Bibliografía
Díaz Fernández, Antonio M. (director): Conceptos fundamentales de inteligencia. Tirant lo Blanch, Valencia, 2016.
Díaz Fernández, Antonio M. (director de obra): Diccionario LID INTELIGENCIA Y SEGURIDAD. LID Editorial Empresarial, 2013.
Esteban Navarro, Miguel Ángel (coordinador): Glosario de inteligencia. Ministerio de Defensa, Madrid, 2007.
González Cussac, José Luis (coordinador): Inteligencia. Tirant lo blanch, Valencia, 2012.
Inteligencia Militar Terrestre-Manual de Fundamentos, Exército Brasileiro, 2015. En línea,http://bdex.eb.mil.br/jspui/bitstream/123456789/95/1/EB20-MF-10.107.pdf(Consultado 24jun2017).
Jiménez Moyano, Francisco. Manual de Inteligencia y Contrainteligencia. CISDE Editorial, 2012.
Kent, Sherman: Strategic Intelligence for American World Policy. Princeton, NJ, 1949. Edición en castellano 4ª Edic.: Buenos Aires, Editorial Pleamar, 1986.
Martre, Henri. Intelligence économique et stratégie de enterprises. Rapport du Commisariat Général au Plan. París. La Documentation franÇaise, 1994. En línea,http://www.entreprises.gouv.fr/files/files/directions_services/informati…. (Consultado 02jul2017).
[1] Kent, Sherman: Strategic Intelligence for American World Policy. Princeton, NJ, 1949. Edición en castellano: 4ª Edic. Buenos Aires, Editorial Pleamar, 1986.
[2] Sánchez Blanco, E.: OSINT (inteligencia de fuentes abiertas), en Díaz Fernández, A. M.:Conceptos fundamentales de inteligencia. Tirant lo blanch, Valencia, 2016, pp. 274-276.
[3] Inteligencia Militar Terrestre-Manual de Fundamentos, Exército Brasileiro, 2015. En línea, http://bdex.eb.mil.br/jspui/bitstream/123456789/95/1/EB20-MF-10.107.pdf(consultado 24jun2017).
[4] Martre, Henri (1994), Intelligence économique et stratégie de enterprises. Rapport du Commisariat Général au Plan. París. La Documentation franÇaise. En línea,http://www.entreprises.gouv.fr/files/files/directions_services/informati…. (Consultado 02jul2017).
[5] Op. cit.
[6] Sansó-Rubert Pascual, D. ¿Inteligencia criminal?: Líneas de demarcación y áreas de confusión. La necesidad de reevaluar su rol en la esfera de la seguridad y en la lucha contra la criminalidad organizada, en Velasco, Fernando y Rubén Arcos (eds.), Cultura de Inteligencia, un elemento para la reflexión y la colaboración internacional, Plaza y Valdés. Madrid. 2012. pp. 347-360.
[7] Sansó-Rubert Pascual, D. Inteligencia criminal, en Díaz Fernández, Antonio, (Dtor).Conceptos fundamentales de inteligencia. Tirant lo blanch. Valencia. 2016. pp. 223-231.
[8] Jiménez Moyano, F. Manual de Inteligencia y Contrainteligencia. CISDE Editorial. 2012. p. 33.
Editado por: Grupo de Estudios en Seguridad Internacional (GESI). Lugar de edición: Granada (España). ISSN: 2340-8421.
Fuente: seguridadinternacional.es, 26/11/18.
Más información:
Inteligencia es anticipación
Antecedentes del Ciclo de Inteligencia de Sherman Kent
La Inteligencia y sus especialidades en la Sociedad del conocimiento
______________________________________________________________________________
______________________________________________________________________________
Vincúlese a nuestras Redes Sociales: LinkedIn YouTube Twitter
______________________________________________________________________________

.
.
La Inteligencia y sus especialidades en la Sociedad del conocimiento
octubre 20, 2023
De los espías a las computadoras, el creciente uso de la inteligencia en el siglo XXI
Por Gustavo Ibáñez Padilla.

Vivimos en un mundo de datos, los cuales crecen día a día en forma exponencial.
Cada transacción, cada interacción, cada acción es registrada y genera a su vez nuevos datos (la hora del registro por ejemplo) llamados metadatos. Todo este creciente cúmulo información puede ahora ser procesado a gran velocidad (big data) a fin de extraer conclusiones.

.
Captar y procesar datos, organizarlos, transformarlos en información y luego en conocimiento para facilitar la toma de decisiones es lo que se conoce como ‘inteligencia’. Hace algún tiempo se consideraba una función estratégica al servicio de las máximas autoridades, para asegurar la defensa de la nación. Así fue en los inicios, cuando se profesionalizó la actividad de la mano de Sherman Kent en los Estados Unidos y dio nacimiento a la agencia central de inteligencia, más conocida como la CIA. Por supuesto no era algo nuevo, ya nos hablaba sobre ello Sun Tzu en el siglo VI antes de Cristo. Pero fueron los estudios de Kent los que le dieron la formalidad de una disciplina, a mediados del siglo pasado.

Con el paso de los años la inteligencia se fue expandiendo al tiempo que crecía la capacidad de procesar información. Así surgieron los adjetivos que califican al sustantivo ‘inteligencia’ para diferenciar su múltiples variedades, llegando entonces a una compleja taxonomía del concepto inteligencia.
Al extender su ámbito la inteligencia se hizo accesible a la sociedad en general y comenzaron a usarla las empresas y organizaciones en general (business intelligence), para esta democratización de sus usos colaboró en forma importante la tremenda baja en los costos de adquisición y procesamiento de la información, que corría al ritmo de los avances informáticos.
Podemos mencionar como casos de éxito de inteligencia de negocios los sistemas de precios dinámicos en las aerolíneas, que acoplan los precios a las variaciones de oferta y demanda; la plataforma de venta online de Amazon, que recomienda otros artículos según los intereses del comprador y Netflix, que sugiere películas y series y orienta el rumbo de las nuevas producciones.
Es así que con la evolución de la disciplina comienzan a solaparse las áreas de influencia de la inteligencia de negocios, con la inteligencia criminal, la inteligencia financiera, la inteligencia estratégica y podríamos seguir hasta el cansancio…
Vemos que con el paso del tiempo el concepto de inteligencia ha ganado fuerza, profundidad, densidad y trascendencia. En una sociedad del conocimiento esto resulta absolutamente lógico y natural.
Pero dejemos ahora el análisis en abstracto y veamos algunos ejemplos concretos que nos muestren el enorme potencial de este concepto.
Imaginemos una organización criminal que comienza a operar una instalación clandestina de marihuana, en los suburbios, mediante el cultivo hidropónico. Esta nueva actividad se evidenciará por un consumo eléctrico superior al usual de una zona residencial, que quedará registrado en las bases de datos de la compañía de electricidad.

.
Al mismo tiempo, es probable que el nuevo suministro de droga ilegal a buen precio incremente el tránsito de consumidores y se produzca un aumento de la conflictividad y de delitos menores, lo cual podría percibirse en los registros de un eficiente mapa del delito.
.
También podrían aumentar las consultas a los servicios de guardias de los hospitales de la zona, motivados por un creciente número de intoxicaciones por estupefacientes.
Todas estas pequeñas variaciones en los registros de datos podrían detectarse gracias al eficaz empleo de la inteligencia de negocios, que permite relacionar múltiples bases de datos haciendo evidente la anomalía generada por el nuevo invernadero clandestino.

.
Es interesante prestar atención a que no fue necesario realizar acciones tradicionales de inteligencia criminal, ni disponer de informantes o agentes encubiertos, que realicen las usuales tareas de inteligencia en búsqueda de los narcotraficantes. Tan solo fue preciso disponer de un sistema de información que relacione distintas bases de datos, que registran en forma habitual y monótona inmensas cantidades de información, y de esta forma poner en evidencia la “perturbación” generada por el accionar de los malvivientes.
Vemos como la superposición de inteligencia de negocios con inteligencia criminal permite obtener resultados en forma casi automática y a mucho menor costo.
También puede tomarse como ejemplo el cruce de datos de llamadas telefónicas que nos permite evidenciar relaciones entre distintas personas y prácticamente descubrir acciones conspirativas, sin necesidad de conocer el contenido de las comunicaciones y sin tener que recurrir a escuchas judiciales (ej: asesinato del fiscal Alberto Nisman, enero 2015).
.
Evidentemente, la sociedad en general y la seguridad nacional pueden beneficiarse cada día más del empleo de sistemas avanzados de análisis de inteligencia, capaces de explotar de manera eficaz y eficiente los crecientes volúmenes de datos derivados de los omnipresentes sistemas de captación y procesamiento de información.
La inteligencia en todas sus variantes es indispensable para el desempeño óptimo de las empresas y organizaciones en general y el eficaz accionar de las agencias gubernamentales que persiguen al crimen organizado, los grupos terroristas y cualquier otra amenaza contra la nación.
Fuente: Ediciones EP, 2019.
Información sobre Gustavo Ibáñez Padilla
Más información:
¿Qué es la inteligencia criminal?
La geolocalización y la investigación policial
Antecedentes del Ciclo de Inteligencia de Sherman Kent
Business Intelligence aplicada en el análisis de Inteligencia Criminal
______________________________________________________________________________
Vincúlese a nuestras Redes Sociales: LinkedIn YouTube Twitter
______________________________________________________________________________

.
.
.
Inteligencia es anticipación
junio 15, 2022
Inteligencia: entender o anticipar
Quizá las dos principales ambiciones de la inteligencia sean comprender el presente –en sentido amplio, incluyendo el pasado próximo– (podría asimilarse al popular concepto de situation awareness) y anticipar el futuro (warning). Distintos servicios, distintas comunidades de inteligencia, distintos países pueden dar más importancia a una o a otra de estas dos grandes líneas de trabajo, aunque, en mayor o menor medida ambas están siempre presentes.

La inteligencia americana, por ejemplo, se ha mostrado particularmente preocupada por evitar la sorpresa estratégica, quizá a causa de experiencias traumáticas como Pearl Harbour o el 11S, que tanta influencia han tenido en el desarrollo de la comunidad y de sus servicios componentes.[1] Y siguiendo una orientación bastante distinta, los servicios británicos han estado en general más orientados hacia la comprensión de la situación y de sus factores (inteligencia explicativa).
Los británicos, en cualquier caso, parecen estar en minoría. Todos los servicios que se inspiran en los modelos americanos (la mayoría de los occidentales) muestran un interés particular por la inteligencia predictiva (prospectiva o estimativa), en general bajo forma de “alerta temprana”.

En el fondo, ambas orientaciones son menos distintas de lo que a primera vista parecen. Porque la buena comprensión de la situación es un requisito casi imprescindible para formular un buen pronóstico. Y aquellos que saben bien dónde están pueden prever, a menudo con un margen de error aceptable, dónde pueden encontrarse a corto o corto/medio plazo (los plazos largos son casi irrelevantes para la política real).
Si sabemos que a las 16.30 dos individuos han cometido un atentado terrorista en la Plaza de la Concordia de París y que han huido a pie del lugar del atentado no es difícil tener una idea aproximada de dónde pueden encontrarse a las 17.00. Y, sobre todo, de dónde no pueden encontrarse. Por ejemplo, es prácticamente imposible que hayan abandonado el país. Este conocimiento prospectivo, derivado de una exacta comprensión de la situación actual, es el que se utiliza en la práctica para poner en marcha ‘operaciones jaula’ tras sucesos de este tipo.
Tradicionalmente, la inteligencia prospectiva ha estado muy basada en la intuición de los analistas. En la actualidad, sin embargo, modelos matemáticos que hacen uso de la capacidad de computación de los ordenadores, permiten formular predicciones mucho más exactas, menos dependientes del talento (y de los sesgos) de los equipos analíticos. Sin embargo, esta mayor calidad técnica de la predicción puede no traducirse en absoluto en una mejor alerta que permita a los decisores políticos adoptar las medidas adecuadas antes de que las amenazas se materialicen.[2]
El problema con las alertas es que su efectividad no depende únicamente del que las lanza, sino, sobre todo, del que las recibe. En 2007, la Comisión Europea organizó en Bruselas una conferencia bajo el lema “From early warning to early action – developing the EU’s response to crisis and longer-term threats”.[3] Y el propio planteamiento inicial ya indicaba la idea fuerza que la Comisión deseaba transmitir: lo importante de verdad es que las alertas den lugar a respuestas políticas eficientes, oportunas en tiempo y forma. De manera que la transmisión de la alerta y, sobre todo, su recepción pasan a tener una importancia capital. [4] Y aquí surgen los problemas:
- Los decisores políticos tienen una confianza limitada en la capacidad de la inteligencia (o de cualquier otro proveedor alternativo de conocimiento) para prever el futuro[5].
- Aunque bastantes decisores puedan sentirse fascinados por el progreso científico y las posibilidades que las nuevas tecnologías ofrecen, es muy frecuente que confíen poco en instrumentos y metodologías cuyo funcionamiento no pueden entender. En 1975, poco después de la guerra del Yom Kippur (una sorpresa estratégica que Israel no había sido capaz de anticipar) el Ministro de Asuntos Exteriores israelí Ygael Alon encargó a un equipo formado por un conocido psicólogo (especializado en la psicología de la decisión)[6] y a un analista de inteligencia que le prepararan un informe sobre cuáles serían las consecuencias de los posibles resultados de las negociaciones, entonces en curso, entre Israel y Egipto (con mediación norteamericana). El equipo planteó el proyecto desde el punto de vista de la Teoría del Análisis de Decisiones y llegó a unos resultados que fueron recibidos con indiferencia en el Ministerio: “The minister remarked politely that the probabilities were ‘interesting’”.[7] Parece claro que los decisores no comprendían la base científica del informe que les presentaban y no creían, por ello, que los resultados que proporcionaba fueran correctos. O, si acaso, aceptaban que lo eran en la medida en que coincidían con su propio análisis, basado en la experiencia personal y/o grupal procesada con sentido común.[8]
- Finalmente, hay que tener en cuenta que cualquier medida política que se adopte tiene un precio, en términos de capital político. Cuando un gobierno toma una determinada medida en respuesta a una alerta, gasta capital político (porque la medida supondrá uso de recursos, que podrían emplearse con otros fines más populares, o puede entrañar la limitación de ciertos derechos o libertades), pero, como el público no conoce en detalle los motivos reales de alarma, puede entender que la respuesta es injustificada[9]. Recuérdese el debate en España sobre el famoso ‘comando Dixán’.[10]
Una conclusión que quizá no compartan todos los lectores. En inteligencia la explicación del presente (en sentido amplio) es el objetivo fundamental que debemos intentar alcanzar. Si los decisores comprenden bien la situación, estarán en magníficas condiciones para tomar unas decisiones que no solo se aplicarán en un espacio futuro, sino que, en gran medida, contribuirán a conformarlo. En el terreno militar se ha dicho que “suele ser comparada la previsión de los grandes capitanes a la mirada del águila que, remontándose en pleno día a inmensa altura, ve mil secretos escondidos a los vulgares ojos”.[11] Es un talento que a menudo se denomina ‘coup d’oeil’ y que Clausewitz definió como “el hallar una verdad que se oculta a la mirada habitual de la inteligencia, o que solo se hace visible tras larga y reflexiva consideración”.[12] El gran capitán lo es por tomar decisiones correctas en medio de la incertidumbre (una incertidumbre en gran parte debida al carácter futuro de muchas de las amenazas a las que se va a enfrentar), y quizá baste con que comprenda bien la situación actual para estar en mejores condiciones de decidir con eficacia. Quizá no sea necesario que le digamos con antelación qué es lo que va a ocurrir.
Entre los gurús de la inteligencia moderna, Greg Treverton es uno de los que ha defendido este enfoque: “In the world looking to 2010 and beyond, the business of intelligence will be information defined as a high-quality understanding of the world using all sources, where secrets matter much less and where selection is the critical challenge”[13]. Incluso para un autor como Tom Fingar (otro de nuestros gurús), apasionado defensor de la inteligencia estimativa, el fin último de la inteligencia es (ayudar a) dar forma al futuro, no predecir cómo será[14].
NOTAS:
[1] Bowman H. Miller, que durante más de un cuarto de siglo fue el Director de Análisis para Europa en el INR, ha escrito recientemente que “Intelligence is about reducing uncertainty for policy and decisionmakers, avoiding unwelcome (especially strategic) surprises, and anticipating—as best it can—possible future developments”. Todos estos fines son de naturaleza prospectiva o tienen una carga prospectiva muy alta. Ver MILLER, B.H. (2014). U.S. Strategic Intelligence Forecasting and the Perils of Prediction. International Journal of Intelligence and CounterIntelligence, 27: 687–701. DOI: 10.1080/08850607.2014.924810.
[2] Aunque en este post nos centramos en las amenazas, en inteligencia se busca también detectar oportunidades que puedan ser aprovechadas por los clientes para alcanzar sus objetivos.
[3] Ver https://ec.europa.eu/jrc/en/event/early-warning-early-action-developing-eu-s-response-crisis-and-longer-term-threats-7760.
[4] Para más detalles, ver PALACIOS, JM (2018). Transmisión y recepción de la alerta estratégica. GESI (Grupo de Estudios en Seguridad Internacional), Blog de José-Miguel Palacios, 22 Feb 2018. http://www.seguridadinternacional.es/?q=es/print/1333.
[5] Algo completamente razonable, por otra parte. Como señala Javier Jordán, “conocer con certeza y anticipación lo que está por venir es sencillamente imposible, en especial en los ámbitos de estudio de la Ciencia Política y de las Relaciones Internacionales”. Ver JORDÁN, J. (2016). La técnica de construcción y análisis de escenarios en los estudios de Seguridad y Defensa. Análisis GESI, 24/2016. http://www.seguridadinternacional.es/?q=es/print/881.
[6] Daniel Kahneman. Años después, en 2002, recibiría el Premio Nobel de Economía. Ver https://en.wikipedia.org/wiki/Daniel_Kahneman.
[7] LANIR, Z., & KAHNEMAN, D. (2006). An experiment in decision analysis in Israel in 1975. Studies in Intelligence, 50(4). https://www.cia.gov/library/center-for-the-study-of-intelligence/csi-publications/csi-studies/studies/vol50no4/an-experiment-in-decision-analysis-in-israel-in-1975.html.
[8] Esta aceptación de la inteligencia (o del asesoramiento experto) si coincide con el análisis propio de los decisores supone, de hecho, dar la razón a los proponentes de la “teoría argumentativa”. Ver MARTÍN ORTEGA, D. (2016). El análisis de Inteligencia: técnicas de análisis y fuentes de error. Una aproximación desde la teoría argumentativa. Revista de Estudios en Seguridad Internacional, 2 (1), 103-123. DOI: http://dx.doi.org/10.18847/1.3.6.
[9] Paul Pillar (https://en.wikipedia.org/wiki/Paul_R._Pillar) lo ha explicado con claridad insuperable: “Warning from an intelligence service (or from anyone else) is one thing; having sufficient domestic or foreign support or both to act on the warning is quite another. Policymakers have repeatedly been constrained by the insufficiency of such support, more so than any insufficiency of predictions. The difficulty is in persuading larger audiences. No matter how much an intelligence service’s analysis may convince policymakers of an impending event, the American public as well as foreign governments and their publics almost always require something more. (…) Actual, graphic events—a war, a surprise attack, or whatever else leads to later recriminations about its not being predicted—have far more power to move publics and governments and to generate support for a vigorous response than even the most pointed and prescient predictions. They have far more impact than even the most elegant and well-documented analysis any intelligence service can ever offer. (…) Strong measures follow rather than precede dramatic events such as military invasions or major terrorist attacks not because the event is a revelatory, scales-dropping-from-eyes lesson to policymakers who previously were unaware of a danger, but instead because the event—as a matter of public mood and emotion—generates the necessary political support for the measures”. Ver PILLAR, P.R. (2011). Intelligence and US foreign policy: Iraq, 9/11, and misguided reform. Columbia University Press. Pp. 187-188.
[10] Puede encontrarse un breve resumen de este caso en https://elpais.com/diario/2007/02/10/espana/1171062014_850215.html.
[11] Benito Pérez Galdós en su obra Juan Martín El Empecinado, uno de los Episodios Nacionales.
[12] CLAUSEWITZ, C. (1978). De la Guerra. Madrid: Ediciones Ejército. Pg. 63.
[13] TREVERTON, G.F. (2003). Reshaping national intelligence for an age of information. Cambridge University Press. Pg. 98.
[14] “The ultimate goal is to shape the future, not to predict what it will be”. FINGAR, T. (2011). Reducing uncertainty: Intelligence analysis and national security. Stanford University Press. Pg. 53.
—José Miguel Palacios es Coronel de Infantería y Doctor en Ciencias Políticas, España.
Fuente: global-strategy.org

.
.
El Analista de inteligencia
enero 26, 2022
«Cuando los analistas son demasiado precavidos al hacer juicios estimativos sobre amenazas, se los culpa de no haber avisado. Sí son demasiado agresivos al lanzar la advertencia, se les critica por alarmistas.» Jack Davis
Artículo recomendado:

Qué es el análisis de inteligencia
El análisis de inteligencia es el proceso de evaluar y transformar los datos e información en conocimiento útil. Este conocimiento útil es solicitado y se genera para tomar una decisión.
El análisis de inteligencia comparado con el método científico
Aunque el análisis de inteligencia se base en el método científico, no son lo mismo. Tienen bastantes diferencias, principalmente por las temáticas que suelen analizarse: estrategias a largo plazo, nivel de riesgo o amenaza, probabilidad de que ocurra un evento social o político, etc.
En este tipo de análisis e investigaciones, normalmente llevados a cabo por empresas, gobiernos, organismos públicos y organizaciones diversas, se encuentran con:
- Elevada incertidumbre.
- Escasez de información contrastada y objetiva.
- Multitud de fuentes de información con diferentes grado de credibilidad.
- Diversidad de variables y multitud de actores.
- Falta de relaciones causales objetivas sobre la temática analizada.
- Necesidad de inmediatez o urgencia para llegar a conclusiones.
- Obligatoriedad de discreción y secreto.
Todas las organizaciones toman decisiones, especialmente aquellas que están más expuestas a riesgos, amenazas u oportunidades. En estos casos la no decisión no es una opción viable.
Para poder tomar una buena decisión, es necesario analizar previamente la información disponible e incluso la no disponible. Para ello se presentan dos opciones: el método científico o el análisis de inteligencia.
El análisis de inteligencia tiene muchas ventajas ya que permite racionalizar procesos de decisión complejos, con multitud de variables, diversidad de fuentes de información de diferentes grados de confianza cada una, en entornos con una alta incertidumbre.
Por otro lado, tiene algunos inconvenientes. El análisis de inteligencia, al depender de personas, no es absolutamente objetivo ni exacto, ni permite tomar una decisión correcta con seguridad ya que se basa en intuición y sus conclusiones no tienen la integridad y solidez empírica del método científico.
Por este motivo, los informes de inteligencia usualmente terminan ofreciendo una serie de estimaciones y probabilidades que reducen la incertidumbre y permiten tomar decisiones de forma más racional, pero nunca totalmente objetiva.
Si el análisis de inteligencia no es un método 100% válido para tomar decisiones objetivas, ¿por qué no se utiliza el método científico para tomar decisiones?
El método científico no resulta una técnica viable para la toma de decisiones objetivas ya que necesita de información totalmente confiable y contrastada así como tiempo para validar o refutar las hipótesis. Esas características dificilmente se disponen en el mundo empresarial o institucional, que es donde más se emplea el análisis de inteligencia.
Por tal motivo cada vez son más las organizaciones que buscan y demandan profesionales de la inteligencia, especialmente Analistas de Inteligencia para Unidades y Departamentos de Estrategia, Análisis o Seguridad, tanto en grandes empresas como en instituciones públicas.
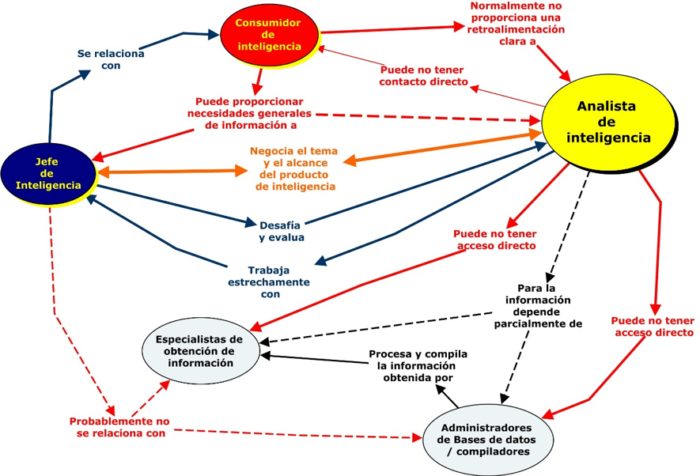
Más información:
Inteligencia Estratégica
Una Taxonomía del concepto Inteligencia
El uso de la Inteligencia en los negocios
La Inteligencia y sus especialidades en la Sociedad del conocimiento
.
.