
Contrainteligencia para todos: del Cono del Silencio al Santor Harp
abril 10, 2025
Por Gustavo Ibáñez Padilla.
En un mundo donde hasta tu tostadora podría estar espiándote (¡y no solo por tu gusto por el pan quemado!), proteger nuestras conversaciones cara a cara se ha convertido en una cuestión de supervivencia informativa. Vivimos en la era del micrófono omnipresente: teléfonos, relojes, asistentes virtuales, auriculares, bolígrafos espías y hasta lámparas con alma de James Bond. La privacidad, ese bien intangible que antes dábamos por hecho, hoy se ha convertido en un lujo… o en una estrategia de contrainteligencia.
¿Recuerdan el Cono del Silencio de Superagente 86? Ese armatoste transparente que descendía del techo para que el Agente 86 y el Jefe pudieran hablar en secreto… aunque, en realidad, nunca funcionaba. Pues bien, afortunadamente la tecnología ha avanzado desde entonces, y hoy tenemos opciones reales —y portátiles— para mantener nuestras charlas fuera del alcance de oídos indiscretos. Señoras y señores, les presento al Santor HARP: el ninja acústico del siglo XXI.

.
Cuando las paredes oyen (y graban)
No es paranoia si realmente te están escuchando. Cualquiera que haya pronunciado la frase “creo que necesito una aspiradora nueva” cerca de su teléfono y haya visto una avalancha de anuncios al respecto, lo sabe. ¿Y si esa conversación hubiera sido sobre una fusión empresarial, un plan de innovación o una traición amistosa en el póker del viernes? Pues ahí está el peligro.
En este escenario de vigilancia ubicua, la contravigilancia no es solo cosa de espías con gabardina y gafas oscuras. Es una necesidad estratégica tanto para directivos como para cualquier ciudadano que valore su privacidad. Y ahí es donde entra en acción el Santor HARP: un dispositivo diseñado con precisión quirúrgica para proteger conversaciones cara a cara en tiempo real.
La sinfonía del desconcierto: cómo funciona el Santor HARP
El Santor HARP no bloquea micrófonos como si fuera un inhibidor de señal al estilo de un tanque de guerra. No, eso sería demasiado burdo y, además, ilegal en muchos lugares. Lo que hace es mucho más elegante: confunde, desorienta y sabotea cualquier intento de grabación.
Modo de Mezcla de Voz: imagina una fiesta de cumpleaños en la que todos cantan a distintas velocidades y tonos. Eso es lo que escucha cualquier dispositivo espía cuando el HARP entra en acción: una cacofonía premeditada que se superpone a la conversación real, impidiendo su aislamiento mediante softwares de limpieza forense.
Modo Discreto: para los que prefieren el sigilo absoluto, este modo emite un ruido casi imperceptible, como un susurro constante que es suficiente para sabotear grabaciones sin molestar a los interlocutores. Y, por si fuera poco, puedes camuflarlo reproduciendo música desde tu lista de Spotify. ¡Espía eso, Siri!
Escudo Acústico Personalizado: con la app Santor Connect, puedes cargar tus propias frecuencias de voz al dispositivo. Así, la protección se ajusta a ti, como un traje a medida para tus cuerdas vocales. ¿Te imaginas a tu voz generando su propio campo de fuerza? Ya no hace falta imaginarlo.
Portabilidad letal (en el buen sentido)
El Santor HARP es tan compacto como un altavoz de escritorio y tan fácil de usar como una tostadora (esperemos que más seguro). No necesita cables interminables ni técnicos con destornilladores. Lo colocas sobre la mesa, eliges el modo que más te guste, y listo: tienes un escudo de invisibilidad auditiva.
Además, su diseño sobrio y minimalista no delata su verdadero poder, algo fundamental si no quieres que parezca que estás haciendo una película de espías en plena reunión de presupuesto.
Espías corporativos, abstenerse
No es casualidad que este dispositivo ya esté en manos de agencias gubernamentales y unidades militares alrededor del mundo. Pero su verdadera revolución está en acercar ese nivel de protección al ciudadano común, al ejecutivo preocupado por la filtración de una patente o al abogado que sabe que las paredes tienen oídos y micrófonos 4K.
La empresa detrás de esta maravilla es SANTOR Security Inc., una compañía canadiense fundada en 2011 y especializada en técnicas de contramedidas de vigilancia. ¿Su objetivo? Hacer que lo que se dice cara a cara, se quede cara a cara. Nada de archivos .mp3 con tu voz diciendo cosas comprometedoras.
¿Exageración o precaución sensata?
Algunos dirán que todo esto es paranoia tecnológica. Otros, que es simplemente sentido común adaptado al siglo XXI. Lo cierto es que, en un contexto donde la información puede valer más que el oro y donde cualquier micrófono puede convertirse en un testigo no deseado, proteger nuestras conversaciones debería ser una prioridad, no un lujo.
No se trata solo de evitar el espionaje empresarial o gubernamental. Se trata de proteger nuestras ideas, decisiones y planes. De preservar la confianza que surge en una conversación íntima o profesional. De no dejar que las máquinas escuchen lo que está reservado para los humanos.

.
Contrainteligencia: una necesidad, no una moda
Vivimos en tiempos donde la vigilancia pasiva ha dejado de ser ciencia ficción y se ha instalado cómodamente en nuestros bolsillos, escritorios y salones. Frente a esta realidad, la contrainteligencia no es solo un juego de espías ni una táctica militar. Es un acto de libertad personal y profesional. Es la manera en que recuperamos el control sobre nuestras propias palabras.
Así que la próxima vez que tengas una conversación importante, no invoques al Cono del Silencio ni te refugies en una cabina telefónica del siglo pasado. Hazlo con inteligencia. Hazlo con contrainteligencia. Hazlo con el Santor HARP.
Porque en un mundo donde todos te escuchan, el verdadero poder está en saber cuándo y cómo no ser escuchado. ¿Privacidad o complacencia? Tú decides.
Fuente: Ediciones EP, 10/04/25.

Más información:
Contrainteligencia empresarial
Vivir en un mundo incierto y complejo
Inteligencia y Contrainteligencia empresarial
La Seguridad Personal y Familiar en el Siglo XXI
Carlos Atachahua, el narcotraficante experto en Contrainteligencia
Contrainteligencia y Contravigilancia: cómo proteger tus conversaciones
Seguridad Humana Multidimensional: Una clave para enfrentar los retos contemporáneos
.
.
Una Taxonomía del concepto Inteligencia
septiembre 13, 2024
El término inteligencia proviene del latín intelligentia, que a su vez deriva de inteligere. Esta es una palabra compuesta por otros dos términos: intus (“entre”) y legere (“escoger”). Por lo tanto, el origen etimológico del concepto de inteligencia hace referencia a quien sabe elegir: la inteligencia posibilita la selección de las alternativas más convenientes para la resolución de un problema. De acuerdo a lo descrito en la etimología, un individuo es inteligente cuando es capaz de de escoger la mejor opción entre las posibilidades que se presentan a su alcance para resolver un problema.
Tipos de Inteligencia
Por Rafael Jiménez.
Análisis GESI, 43/2018
Resumen: El tratamiento de cualquier materia induce muy pronto a clasificar todas sus formas o modalidades. Este hecho es más acusado cuando se trata de una materia como la inteligencia, cuya aparición en el dominio público es relativamente reciente, aunque su práctica se remonte al principio de los siglos.
Este capítulo relaciona una amplia taxonomía de la inteligencia, que abarca las dimensiones que puede presentar (a qué se puede referir el concepto inteligencia: producto, proceso u organización); las clases que puede presentar el producto según el nivel de decisión de sus destinatarios; la identificación de ese mismo producto según su finalidad; los tipos de dicho producto según la necesidad de información que satisface; las formas de determinar el producto según el medio en el que se encuentre la información de la que parte; la identificación del mismo producto en función del método de obtención de la información de partida; las modalidades de la inteligencia según el territorio sobre el que se elabora; y cómo se la puede identificar en función de la materia o campos del conocimiento.
*****
1. Dimensiones de la inteligencia
Antes de abordar la clasificación de los tipos de inteligencia es preciso referirse a las dimensiones o conceptos que se pueden expresar con el término inteligencia.
El primero que lo hizo, siempre referido a la inteligencia como componente de la seguridad nacional, fue Sherman Kent en 1949[1], que identificó el término con tres conceptos: a) el producto derivado de la transformación de la información y el conocimiento en inteligencia; b) la organización que realiza esta tarea; y c) el procesomediante el que se lleva a cabo.

La inteligencia como producto es el resultado que se obtiene al someter los datos, la información y el conocimiento a un proceso intelectual que los convierte en informes adecuados para satisfacer las necesidades de los decisores políticos, militares, policiales, empresariales, etc., así como para proteger a aquellos mediante las tareas de contrainteligencia.
La inteligencia como proceso comprende los procedimientos y medios que se utilizan para definir las necesidades de los decisores, establecer la búsqueda de información, su obtención, valoración, análisis, integración e interpretación hasta convertirla en inteligencia, y su difusión a los usuarios. También incluye los mecanismos y medidas de protección del proceso y de la inteligencia creada por medio de las actividades de contrainteligencia necesarias.
La inteligencia como organización se refiere a los organismos y unidades que realizan las anteriores actividades de transformar la información en inteligencia y la protegen.
2. La Inteligencia según el nivel de decisión
Una vez determinado el concepto de inteligencia como producto, su contenido puede referirse a materias políticas y generales del Estado o más detalladas. Por tanto, en función del nivel de decisión del usuario para quien se elabora, la inteligencia puede ser de los siguientes tipos:
2.1. Inteligencia nacional
Es la que precisa el Gobierno de la Nación para definir y desarrollar su política en el más alto de sus niveles de decisión. La inteligencia nacional la elaboran los servicios de inteligencia de nivel nacional, cuya dependencia funcional suele ser del Presidente del Gobierno, aunque administrativamente estén adscritos o integrados en algún departamento ministerial.
2.2. Inteligencia departamental
Es la que necesitan los titulares de los distintos Ministerios del Gobierno de la Nación para ejecutar la política de sus respectivos departamentos. La elaboran los servicios de información e inteligencia dependientes de los respectivos departamentos ministeriales, cuyos productos tienen una aplicación directa en la ejecución de las correspondientes políticas ministeriales. A diferencia de la inteligencia nacional, que se elabora para decisores externos, la departamental constituye un insumo propio de los titulares y altos cargos de los Ministerios en su responsabilidad de ejecución de la política ministerial, así como de los mismos servicios que la elaboran.
2.3. Inteligencia operativa
Es la inteligencia que se genera y se utiliza para planear y ejecutar cualquier tipo de operaciones, tanto de carácter militar como policial o de inteligencia. Su nivel de elaboración y utilización es el más elemental y tiene una aplicación directa en el desarrollo de las operaciones de cualquier organismo o unidad.
3. La inteligencia según su finalidad
De forma similar a la que se ha definido anteriormente según el nivel de decisión del usuario para quien se elabora la inteligencia, esta puede tener distintas finalidades, que permiten clasificarla de la siguiente manera:
3.1. Inteligencia estratégica
Es la inteligencia que se elabora para facilitar la definición de los objetivos de la política y los planes generales de un Estado, para lo que debe tenerse en cuenta el entorno en que se encuentra y las metas que ha fijado el Gobierno.
Para ello, la inteligencia estratégica debe identificar los actores que intervienen en ese entorno, sus características y cómo pueden evolucionar. De esta manera presta una atención especial a los indicios que pueden significar riesgos y derivar en amenazas, o proporcionar oportunidades para la Nación.
La inteligencia estratégica se halla muy vinculada a la prevención y a la prospectiva, advirtiendo de amenazas a los intereses vitales de la seguridad nacional y de las oportunidades para el Estado, con lo que se convierte en la principal herramienta en poder de los gobernantes para diseñar y desarrollar las políticas exterior y la de seguridad nacional.
En el ámbito militar, la inteligencia estratégica tiene como finalidad facilitar la elaboración de los planes relativos a la conducción de las operaciones de nivel estratégico.
En el ámbito empresarial, la inteligencia estratégica tiene la finalidad de facilitar la toma de decisiones de sus directivos ante las amenazas o riesgos para la empresa, o aquellas que puedan facilitar un éxito u oportunidad de desarrollo. En concreto, se especializa en el análisis de los competidores para entender sus éxitos futuros, estrategias actuales, la posible evolución industrial y comercial, y sus capacidades. También incluye la inteligencia sobre los principales clientes, proveedores y socios.
Un caso particular de la inteligencia estratégica lo constituye la denominadainteligencia de alerta, que es la que tiene por finalidad prevenir al usuario de las amenazas contra los intereses nacionales o empresariales, para que pueda decidir con tiempo las medidas políticas, diplomáticas, militares, económicas, industriales, comerciales o de cualquier otro tipo que puedan neutralizarlas o hacerles frente.
3.2. Inteligencia táctica
La inteligencia táctica es la que se elabora para contribuir a la planificación y el diseño de las acciones concretas que permitan alcanzar un objetivo de alcance limitado, subordinado a los grandes objetivos de la inteligencia estratégica.
En el ámbito militar, la inteligencia táctica está destinada a la elaboración de los planes que permitan la conducción de las operaciones tácticas.
En el ámbito empresarial tiene un carácter más operacional, al consistir en la adopción de acciones concretas para conseguir un objetivo en una situación inmediata. Incluye aspectos como los términos de venta de los competidores, sus políticas de precios y los planes que tienen para cambiar la forma en que se diferencian sus productos de los propios.
3.3. Inteligencias operativa y operacional
La inteligencia operativa es la que se elabora para permitir la organización y ejecución de acciones para el cumplimiento de una misión, entendiendo por esta la que le es encomendada a un oficial de inteligencia, solo o dirigiendo un grupo, para lograr un propósito determinado.
En el ámbito militar, el término apropiado es inteligencia operacional y se encuentra en una posición intermedia entre la estratégica y la táctica. Su elaboración tiene como finalidad apoyar la planificación y la realización de campañas en el teatro de operaciones, en el nivel operativo.
3.4. Inteligencia prospectiva
La inteligencia prospectiva se inicia a partir de la inteligencia estratégica y está orientada a determinar de modo anticipado las opciones de evolución de una situación y las posibilidades y probabilidades de actuación de los elementos involucrados en ella, con objeto de reducir la incertidumbre por el futuro en entornos caracterizados por la complejidad, el cambio y la inestabilidad.
El término de inteligencia prospectiva se emplea específicamente para precisar los objetivos estratégicos de una organización y planificar las acciones necesarias para lograrlos. Asimismo, se utiliza para adoptar decisiones que contribuyan a conducir una realidad determinada hacia un escenario futuro deseable.
Tiene un alto componente de estimación, por lo que también se la conoce comointeligencia estimativa o predictiva.
Se trata de una inteligencia muy compleja y costosa, por la necesidad de contar con especialistas instruidos en las técnicas de la prospectiva y en los diversos campos que influyen en el futuro de una organización, así como por la necesidad de contar con tiempo para elaborarla. Ambas circunstancias condicionan de tal modo su generación que no es habitual que se elabore en las organizaciones ni servicios de inteligencia, más ocupados por los demandantes en elaborar inteligencia actual y de inmediato futuro.
4. La inteligencia según la necesidad de información que satisface
La elaboración de inteligencia se produce como consecuencia de la aparición de un requerimiento concreto, sea de los potenciales usuarios o del propio servicio de inteligencia que debe elaborarla. De esta forma, la inteligencia puede ser:
4.1. Inteligencia básica
La inteligencia básica es la que se produce para satisfacer los requerimientos de inteligencia permanentes y generales de la organización de que se trate.
Se emplea sobre todo para responder a las necesidades de información que se plantean durante la producción de inteligencia estratégica e inteligencia prospectiva o estimativa. Por tanto, se elabora atendiendo a los objetivos estratégicos de la organización. Dado que se convierte en un importante almacén de inteligencia, también se utiliza para atender demandas de información durante la producción de inteligencia táctica, operativa y operacional.
La producción de inteligencia básica se realiza de un modo rutinario y programado a partir de fuentes de información abiertas, generalmente obras de referencia, estados y descripciones generales, guías de seguimiento, etc., como enciclopedias, bases de datos, anuarios, directorios, etc.
Esta inteligencia tiene un grado de permanencia mayor que cualquier otra y a ella se incorpora la que se extrae de la inteligencia estratégica que se ha elaborado durante el desarrollo de la actividad de la organización, por lo que también suele recibir la denominación de inteligencia general de la organización, convirtiéndose en un activo informacional de esta.
4.2. Inteligencia actual
Es la inteligencia que tiene por finalidad satisfacer los requerimientos de inteligencia puntuales y concretos de una organización. Presenta el estado de una situación o de un acontecimiento en un momento dado y puede señalar opciones de evolución en un corto plazo, así como indicios de riesgos inmediatos.
Se emplea principalmente para responder a las demandas de información que surgen durante la aparición de un fenómeno o acontecimiento imprevisto, durante un proceso de toma de decisiones sobre un acontecimiento de interés nacional o durante la planificación y el desarrollo de una misión.
Suele ser la más demandada por los gobernantes, cuyos plazos de previsión y decisión son generalmente cortos.
Como fin complementario, la inteligencia actual pone al día la inteligencia básica y los análisis realizados por la inteligencia estratégica. Esto permite disminuir las necesidades de información durante las gestiones de crisis.
Los productos de la inteligencia actual suelen adoptar la forma de informes específicos para atender una demanda concreta y actual de información; o la de informes breves y periódicos, muchas veces diarios, sobre cuestiones de interés general y frecuente sobre las que los decisores políticos desean mantener un conocimiento permanente.
4.3. Inteligencia crítica
Como un caso particular de la inteligencia actual surge el concepto de inteligencia crítica, que es la que se elabora para satisfacer los requerimientos informativos que se producen durante la gestión de una crisis.
El tiempo dedicado a la obtención y procesamiento de datos e información y a la valoración, análisis, integración e interpretación durante una crisis se reduce al mínimo imprescindible con objeto de dar a conocer el estado de la situación con la máxima urgencia posible, que además suele evolucionar con rapidez. Por tanto, elaborar inteligencia que permita al responsable político tomar decisiones rápidas y acertadas exige tanto disponer de información concreta sobre lo que ocurre como contar con unas buenas reservas de inteligencias básica y actual que permitan contextualizar el sentido de la nueva información disponible y mejorar su comprensión.
Los productos más habituales durante la gestión de crisis son alertas e informes de situación sobre la evolución de los acontecimientos. La forma de materialización de dichos informes se convierte muchas veces en modo de gráficos, mapas, esquemas, croquis, etc., que, convenientemente ilustrados, permiten un rápido conocimiento de dicha evolución de la situación.
En situaciones de crisis puede ocurrir que, ante la perentoria necesidad de tomar una decisión, se suministre información a los responsables sin analizar ni interpretar suficientemente, o con una estimación provisional muy sujeta a la evolución de los acontecimientos. En estos casos se deja a dichos responsables la tarea de valorar la información que se les suministra, en beneficio de la urgencia con que se puede poner a su disposición. Esta excepcionalidad es motivo de debate, por lo que supone de trasladar la responsabilidad del análisis de inteligencia a los decisores políticos, modificando el funcionamiento habitual del ciclo de inteligencia.
5. La Inteligencia según el medio en el que se encuentra la información
La información de partida para la elaboración de inteligencia puede encontrarse en muy diferentes medios, dando lugar a distintos tipos de inteligencia que reciben el nombre de la que haya sido su componente principal. De esta manera, la inteligencia puede clasificarse del siguiente modo:
5.1. Inteligencia HUMINT o de fuentes humanas
Es la que se elabora a partir de información recogida o suministrada directamente por personas. Sus resultados dependen fundamentalmente de la actuación del hombre mediante sus sentidos, ayudándose o no con medios auxiliares (cámaras, grabadoras, fotocopiadoras, etc.).
En los servicios de inteligencia se consideran diversos tipos de fuentes humanas, cuya actividad facilita en algún grado la obtención de información. En el CNI esta diversidad ha dado lugar a la siguiente clasificación:
- Contacto: persona ajena a un servicio de inteligencia al que proporciona información, de modo consciente o inconsciente y de forma ocasional o regular, pero cuya dirección no es posible o conveniente realizar por parte del servicio. Puede recibir algún tipo de contraprestación.
- Informador: persona ajena a un servicio de inteligencia al que proporciona información, de modo consciente o inconsciente y de forma ocasional o regular, bajo la dirección de un miembro del servicio. Suele percibir algún tipo de contraprestación.
- Colaborador: persona ajena a un servicio de inteligencia, que coopera para este, de modo consciente o inconsciente y de forma ocasional o regular, realizando una serie de actividades, dirigidas por un oficial de inteligencia, en beneficio de los cometidos asignados al servicio. También suele percibir algún tipo de contraprestación. Por tanto, se diferencia del informador en que no suele facilitar información, o al menos no es su cometido principal, sino que facilita tareas que debe realizar el servicio.
- Agente: persona ajena a un servicio de inteligencia que realiza alguna actividad abierta o encubierta en beneficio del servicio y bajo la dirección de un miembro del mismo, tras recibir adiestramiento especial. Los agentes se reclutan habitualmente para llevar a cabo o dar asistencia en tareas de obtención de información y en operaciones de contrainteligencia. Normalmente el agente recibe algún tipo de contraprestación. No debe confundirse el tipo de agentecomo fuente humana, con la misma denominación de agente con que se identifica a los miembros de los servicios de inteligencia que realizan actividades secretas, abiertas o encubiertas, generalmente encuadrados en unidades operativas de obtención de información.
La información obtenida a partir de fuentes humanas es muy útil porque puede proporcionar datos imposibles de obtener por otros medios. Para ello es necesario que se encuentren situadas en el lugar y momento adecuados para adquirir esa información, formación suficiente para apreciarla y poseer un buen y oportuno sistema de comunicación para hacerla llegar al servicio.
La obtención de información por medios humanos, para que sea valiosa, debe superar dos momentos críticos: a) la captación o infiltración de la fuente en el lugar donde pueda acceder a la información deseable; y, b) la valoración de la información adquirida por parte del oficial de relación y de los analistas; el primero es responsable de evaluar la fiabilidad de la fuente, de la que debe conocer su formación, capacidades, vulnerabilidades, intereses, posibilidades, condiciones (facilidades y riesgos) en las que actúa, etc.; mientras que los segundos, los analistas que reciban el fruto de su adquisición, son los principales responsables de evaluar la calidad de la información proporcionada, así como de remitir al órgano de obtención donde se encuentre el oficial de relación su valoración de la información recibida y, unida a ella, la percepción sobre la fiabilidad de la fuente que la ha proporcionado.
5.2. Inteligencia OSINT o de fuentes abiertas
Es la que se elabora a partir de información obtenida de recursos informativos de carácter público.
Por fuente abierta se entiende todo documento con cualquier tipo de contenido, fijado en cualquier clase de soporte que se transmite por diversos medios y al que se puede acceder en modo digital o no, puesto a disposición pública, con independencia de que esté comercializado, se difunda por canales restringidos o sea gratuito.
La información que transmiten las fuentes abiertas se caracteriza por su singularidad, su rápido modo de obtención, su fácil actualización, su bajo coste en relación con la procedente de otras fuentes y su adquisición sin correr riesgos. Es un axioma que no se debería recoger información pública mediante medios clandestinos, complejos, arriesgados y costosos en términos económicos y políticos.
La información procedente de fuentes abiertas es la más utilizada para la producción de inteligencia estratégica, inteligencia básica, inteligencia económica e inteligencia científica. Además, esta información es indispensable para analizar adecuadamente la información clandestina.
La actual y creciente reivindicación de la importancia de la información OSINT se debe a la confluencia de dos fenómenos: a) la aparición del concepto de multinteligencia, que rechaza el uso de una única autoridad informativa para crear inteligencia; y b) la ampliación del concepto de seguridad obliga a los servicios de inteligencia a recabar, analizar y evaluar información de índole muy variada y en materias donde las fuentes abiertas son imprescindibles.
Dada la amplitud y variedad de fuentes públicas, la tipología clásica la clasifica del siguiente modo[2]:
5.2.1. Fuentes de información primaria
Son las que contienen información original, de primera mano y que, por tanto, no han recibido ningún tipo de tratamiento. Dentro de este grupo se suele distinguir: fuentes de información primaria editadas, que forman parte de los circuitos habituales de publicación y distribución y cuya existencia queda verificada por procedimientos legales (ISSN, ISBN, NIPO), entre las que destacan los libros, las revistas, las películas o los discos; y las fuentes de información primaria inéditas, que pertenecen a lo que se ha dado en llamar literatura gris, y que está compuesta por tesis doctorales, presentaciones, pre-prints, actas de congresos o informes científico-técnicos, entre otras, que por lo general tienen una visibilidad menor y suelen carecer de control bibliográfico.
5.2.2. Fuentes de información secundaria
Son las resultantes del tratamiento documental de las fuentes de información primaria y proceden de la aplicación de técnicas documentales que proporcionan valor añadido (los resúmenes, la agrupación en clasificaciones de materias, la correspondencia con otros idiomas y, sobre todo, la relación de unos documentos con otros). Entre este tipo de fuentes se encuentran las bases de datos, los catálogos, los repertorios bibliográficos y los repertorios legislativos.
5.2.3. Fuentes de información terciaria
Podrían asimilarse a las fuentes secundarias, pero el Programa General de Información de la UNESCO les atribuye una finalidad específica: la consolidación de la información mediante productos que analizan críticamente el conjunto de unidades documentales propias de una disciplina, extrayendo de cada una de ellas lo más relevante en cuanto a innovación y progreso. Formarían parte de este tipo de fuentes las revisiones (review) y los estados de la cuestión.
5.2.4. Obras de referencia
Son las que fueron ideadas para la consulta puntual de algunas de sus entradas y entre ellas destacan: enciclopedias, diccionarios, anuarios, glosarios, o las modernasFrequently Asked Questions (FAQ).
Además de esta clasificación académica, otras tipologías se fijan en el emisor (fuentes gubernamentales, parlamentarias, judiciales, policiales, académicas, etc.), en el soporte (impresas, audio, video, informáticas, etc.), en el coste (venales o gratuitas), en la periodicidad, en el destinatario o en el grado de especialización (fuentes generales y fuentes especializadas). De esta manera se pueden clasificar las fuentes OSINT de la siguiente forma:
5.2.5. Fuentes de información institucional
Publicaciones oficiales (boletines oficiales, del registro mercantil, etc.), estadísticas, legislación, jurisprudencia, sistemas de seguimiento legislativo, documentación parlamentaria, y documentación emitida por organismos internacionales.
5.2.6. Fuentes de información económica
Estudios de mercado, informes económico-comerciales de países, información sobre contratación pública, etc.
5.2.7. Fuentes de información geopolítica
Barómetros de conflictos, documentos de comités de expertos y de think tanks.
5.2.8. Fuentes de información sociológica
Estudios de opinión pública, participación electoral, flujos migratorios, encuestas demoscópicas, congresos de partidos políticos y sindicatos, etc.
5.2.9. Fuentes de información de seguridad y defensa
Blanqueo de capitales, tráfico ilícito, terrorismo, infraestructuras críticas, corrupción, ciberdelincuencia, etc.
5.2.10. Fuentes de información bibliográfica
Bases de datos bibliográficas.
5.2.11. Fuentes de información de prensa
Editoriales y editorialistas, análisis de la prensa, servicios de seguimiento de medios, recortes (clipping).
5.2.12. Fuentes de redes sociales y páginas web
Monitorización de redes y páginas informáticas.
5.2.13. Fuentes archivísticas
Destinadas a recoger la producción de documentación de las administraciones modernas y de las empresas; están sometidas a procesos de selección y constitución de colecciones.
5.3. Inteligencia SIGINT o de señales
Es la inteligencia que se elabora a partir de la obtención y el procesamiento de datos provenientes de la detección, interceptación y descifrado de señales y transmisiones de cualquier clase. Es un término genérico, pues dada la gran cantidad de posibles orígenes de señales electromagnéticas y acústicas, una primera clasificación de la inteligencia SIGINT puede diferenciar las siguientes:
5.3.1. Inteligencia COMINT o de comunicaciones
Es la inteligencia obtenida a partir de emisiones electromagnéticas de equipos y sistemas de tecnologías de la información y de las comunicaciones (STIC); por ejemplo, ordenadores, impresoras, faxes, teléfonos, télex, líneas de comunicaciones, agendas electrónicas, tarjetas inteligentes, etc.
Un caso particular de inteligencia COMINT lo constituye la inteligencia cibernética o CYBINT[3], que es la inteligencia elaborada a partir de datos, protegidos o no, del espacio cibernético. Este, a su vez, está definido como el espacio virtual compuesto por dispositivos computacionales conectados en red, donde las informaciones digitales se transmiten, son procesadas o almacenadas. Un ejemplo muy claro de inteligencia CYBINT es la que puede obtenerse a partir de datos adquiridos en las redes sociales. La inteligencia cibernética está íntimamente ligada a la de fuentes abiertas.
Cuando las emisiones de las que se obtiene la información son involuntarias o no deseadas por el emisor se denominan TEMPEST, como por ejemplo las emitidas por las líneas de conducción de comunicaciones, los teclados de ordenador, las radiaciones de las pantallas, etc.
5.3.2. Inteligencia ELINT o electrónica
Es la inteligencia obtenida a partir de emisiones electromagnéticas de medios ajenos a las telecomunicaciones (radares, equipos de ayuda a la navegación, perturbadores de sistemas de comunicación, etc.).
Este tipo de inteligencia, a su vez se subdivide en las siguientes clases:
5.3.2.1. Inteligencia RADINT o de emisiones radar
Es la inteligencia que se obtiene a partir de las emisiones de los radares.
5.3.2.2. Inteligencia TELINT o telemétrica
Es la que se obtiene a partir de emisiones de equipos electromagnéticos de telemetría.
5.3.3. Inteligencia MASINT o de medición de señales
Es la que se elabora a partir de la obtención y el procesamiento de datos provenientes de sensores destinados a recoger las señales que emiten fenómenos físicos distintos a las emisiones electromagnéticas, como el sonido, el movimiento, la radiación, etc. Estas señales se denominan firma del equipo o equipos. Los sensores se dedican a identificar toda característica distintiva asociada con la fuente o el emisor y facilitar la detección y la localización de este último.
De acuerdo con la señal que mide se distinguen diversos tipos específicos de medición de señales:
5.3.3.1. Inteligencia ACINT o acústica
Es la inteligencia derivada de la obtención y el análisis de los fenómenos acústicos producidos por cualquier emisor (buque de superficie, submarino, torpedo, aeronave, dron, vehículo terrestre, proyectil, maquinaria, etc.).
5.3.3.2. Inteligencia TELINT o telemétrica
Ya citada anteriormente (ver 5.3.2.2), permite el análisis de la firma de equipos telemétricos, instalados, por ejemplo, en misiles, satélites, armas de precisión, etc.
5.3.3.3. Inteligencia NUCINT o de radiaciones nucleares
Es la que se obtiene a partir de la medición de señales procedentes de radiaciones nucleares (bombas radiológicas o sucias, bombas atómicas, etc.).
5.4. Inteligencia IMINT o de imágenes
Es la inteligencia que se elabora a partir del análisis de imágenes adquiridas por medios técnicos, como cámaras fotográficas, medios de grabación de imágenes, radares, sensores electro-ópticos, visores térmicos o infrarrojos, ubicados en plataformas terrestres, navales, aéreas o espaciales. En este tipo de inteligencia destacan:
5.4.1. Inteligencia GEOINT o geoespacial
La observación geoespacial, identificada como GEOINT, es el resultado de la explotación y análisis de la información de imágenes y geoespacial para describir, valorar y visualizar características físicas y georreferenciar (situar) actividades en el planeta.
5.4.2. Inteligencia PHOTINT o fotográfica
Es el tipo de inteligencia obtenida mediante el análisis e interpretación de la fotografía aérea, realizada por aviones, helicópteros o drones (JSTARS) de detección y seguimiento de objetivos terrestres o móviles provistos de videofotografía y termografía. Los JSTARS son plataformas aéreas (aviones, helicópteros o drones) que disponen de medios de detección, identificación y seguimiento de objetivos terrestres y móviles, así como de medios de comunicación y señalamiento a los vectores de lanzamiento para atacar a dichos objetivos terrestres o móviles (aéreos y navales).
5.5. Inteligencia TECHINT o técnica
Es el tipo de inteligencia que se elabora a partir de la obtención y el procesamiento de información mediante el uso de medios técnicos. Es un término genérico con el que se designa el uso conjunto de datos provenientes de las inteligencias SIGINT e IMINT.
6. La inteligencia según el método de obtención
La inteligencia también puede clasificarse según el método utilizado para obtener los datos y la información que le sirven de base. Las denominaciones de estos tipos de inteligencia coinciden con los descritos en el punto anterior, excepto que no existe inteligencia OSINT, sino que esta puede obtenerse por métodos HUMINT, SIGINT o IMINT, o varios de ellos simultáneamente.
De esta manera, se pueden clasificar los procedimientos de obtención de información según el método utilizado para su adquisición y según el medio en que se encuentra, dando lugar a la siguiente tabla comparativa:
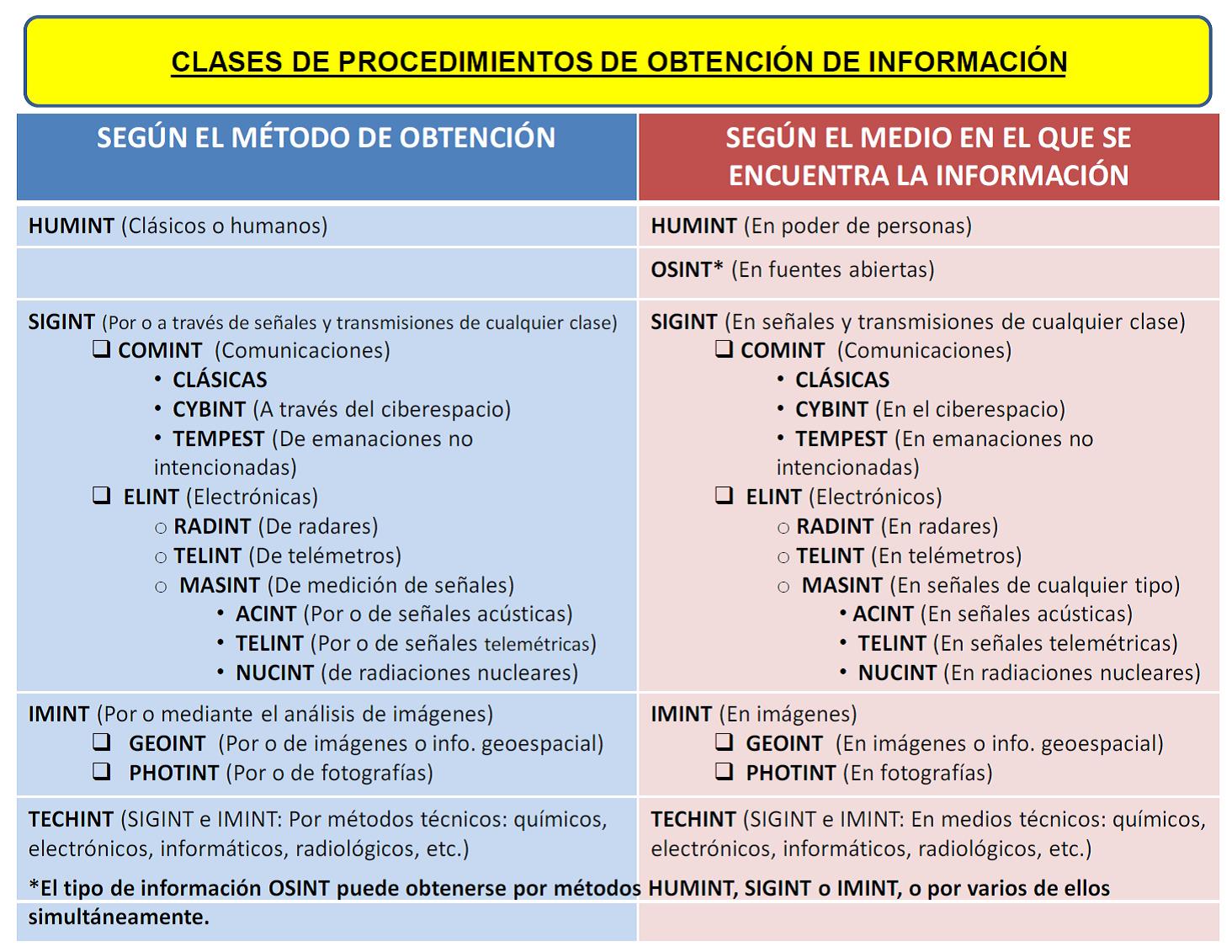
La inteligencia según el método de obtención y comparación con el medio en el que se encuentra la información que le dará nombre: procedimientos de obtención de información.
La inteligencia que se elabora con la información obtenida según un método o contenida en un medio determinado adquiere el mismo nombre. Por ejemplo, la inteligencia elaborada a partir de información obtenida, única o predominantemente, por métodos o en medios HUMINT se denomina Inteligencia HUMINT.
7. La Inteligencia según el territorio sobre el que se elabora
Aunque las amenazas sean globales, los servicios de inteligencia pueden especializar sus tareas en el territorio nacional o fuera de él, dando lugar a una nueva clasificación de la inteligencia por el lugar sobre el que se elabora. Asimismo, la cada vez mayor intervención de organismos multinacionales en misiones internacionales de mantenimiento de la paz ha obligado a generar un tipo de inteligencia específico, adaptado a las necesidades de las misiones abordadas, en el que intervienen varios de los servicios de inteligencia de los países que conforman dichos organismos multinacionales.
Generalmente, los países desarrollados tienden a contar con dos o más servicios de inteligencia de nivel nacional, mientras que la mayor parte de los países sólo cuentan con uno que atiende las necesidades del Gobierno de su país en todo el mundo. Una clasificación de la inteligencia según el territorio del que se ocupa es la siguiente:
7.1. Inteligencia interior
Es el tipo de inteligencia que se ocupa de identificar y seguir la evolución de los riesgos y amenazas a la seguridad procedentes del interior del Estado al que pertenece el servicio de inteligencia, con el fin de apoyar el proceso de adopción de medidas preventivas o de neutralización por parte del Gobierno.
Para ello, la inteligencia interior centra su atención en la investigación de las intenciones, las actividades y la capacidad de individuos y organizaciones que tienen o pueden evolucionar hacia finalidades desestabilizadoras o de franca agresión al orden político establecido o a los intereses nacionales.
7.2. Inteligencia exterior
La inteligencia exterior se ocupa de identificar y seguir la evolución de los riesgos y amenazas a la seguridad procedentes del exterior del Estado al que pertenece el servicio de inteligencia, con el fin de apoyar la adopción de medidas preventivas o de neutralización por parte del Gobierno, así como las que pueda diseñar para promover los intereses nacionales.
Para ello, la inteligencia exterior centra su atención en la investigación de las intenciones, las actividades y la capacidad de personas, organizaciones y naciones extranjeras que puedan atentar contra la soberanía, el orden político establecido, los intereses nacionales y la integridad territorial. Igualmente, se ocupa de detectar oportunidades favorables para la promoción y defensa de los intereses nacionales fuera de las propias fronteras.
7.3. Inteligencia multinacional
Es el tipo de inteligencia realizada sobre un conjunto de naciones o región geográfica, en la que intervienen servicios de distintos países con una finalidad común, como puede ser la que precisan organizaciones multinacionales, como la OTAN, la Unión Europea, la ONU, los países integrantes del Acuerdo UKUSA, etc. Los servicios que elaboran este tipo de inteligencia reciben el nombre de centros de fusión de inteligencia.
8. La Inteligencia según la materia o campos del conocimiento
Los múltiples campos sobre los que tienen que actuar los servicios y otros organismos que producen inteligencia, permiten identificar una nueva clasificación de su producto en función de la materia o campo del conocimiento sobre el que se centra. De esta forma, se pueden hallar los siguientes tipos de inteligencia:
8.1. Inteligencia geográfica
Es la que procede del estudio de las características naturales y artificiales de un espacio o zona geográfica determinada. Generalmente es complementaria de otros tipos de inteligencia.
8.2. Inteligencia política
Es la que trata la política interior y exterior de los gobiernos y las actividades de los movimientos políticos. En los servicios de inteligencia de nivel nacional ocupa una gran parte de su actividad productora.
8.3. Inteligencia sociológica
Se fundamenta en el conocimiento de la estructura y de todos los factores sociales de una nación o zona determinada.
8.4. Inteligencia militar
Identificada como MILINT, es la que se elabora a partir de la información relativa a naciones extranjeras, fuerzas o elementos hostiles o potencialmente hostiles y áreas de operaciones reales o potenciales. Es un ámbito de la inteligencia propio de las fuerzas armadas, por lo que la información que cobra mayor importancia es la relativa a la doctrina, organización, orden de batalla, capacidades, fuerzas, medios, estrategias y tácticas de fuerzas armadas u organizaciones de cualquier tipo, que empleen o puedan emplear procedimientos militares, hostiles o potencialmente hostiles.
La finalidad de la inteligencia militar es facilitar la toma de decisiones en los procesos de dirección y ejecución de las operaciones militares, disminuyendo las incertidumbres de los jefes y sus estados mayores, proporcionándoles la inteligencia oportuna, pertinente, precisa, predictiva y adaptada sobre el enemigo y otros aspectos del área de operaciones que permitan la planificación, ejecución y conducción de las operaciones.
La inteligencia militar, en el siglo XXI, no es la mera descripción de las fuerzas enemigas, de sus medios y capacidades de combate, sino que consiste también en el entendimiento de su cultura, motivaciones, finalidad y objetivos que persiguen. Es decir, no sólo se debe conocer y entender al adversario, sino que es imprescindible conocer y valorar la población de la que surge o proviene, el apoyo que recibe o puede recibir de ella y el apoyo que pueden recibir las fuerzas propias. Se trata de entender el entorno en el que se realizan las acciones de una operación, el llamado entorno operativo.
8.5. Inteligencia científica y tecnológica
Es la que se ocupa de la obtención y el procesamiento de información de carácter científico y tecnológico en los ámbitos civil y militar de interés para la seguridad. Su finalidad es detectar y efectuar el seguimiento de proyectos y actividades de investigación y de desarrollo científico y tecnológico emprendidos por organizaciones o países extranjeros, que puedan derivar en situaciones de riesgo para la seguridad nacional e internacional, con objeto de poder adoptar contramedidas efectivas. Mediante sus análisis puede valorarse el carácter y la capacidad armamentística de posibles adversarios, así como los avances científicos y tecnológicos que pueden derivar en la creación de armas u otros productos susceptibles de representar una amenaza para la seguridad.
La inteligencia científica y tecnológica está ampliando cada vez más su objetivo de atención tradicional, el armamento y los sistemas de armas, para abarcar los campos de las inteligencias económica y competitiva, lo que supone que se ocupe también de la identificación, seguimiento y evaluación de los avances científicos y tecnológicos, dentro de los marcos legales, que se producen en los distintos sectores de interés económico público o privado, con independencia de su posible uso militar.
Una última finalidad de la inteligencia científica y tecnológica lo constituye la que permite adoptar avances tecnológicos ajenos para evitar pasar por largas y costosas etapas previas de investigación.
La inteligencia científica usa de modo intensivo las fuentes de información abiertas, ya que se dedica a vigilar las investigaciones que se realizan en los mundos académico y empresarial antes de que se efectúe su aplicación industrial. En cambio, la inteligencia tecnológica, por estar más relacionada con el seguimiento de las aplicaciones que realizan empresas y organismos públicos de investigación de los conocimientos obtenidos en la investigación básica, también utiliza información procedente del espionaje industrial o de medios técnicos, como la fotografía aérea, la observación por satélite, la cibernética y la interceptación y escucha de señales acústicas.
La inteligencia tecnológica no se debe confundir con la inteligencia técnica (TECHINT), que, como se expresa en el punto 6, es la que se elabora a partir de información obtenida por métodos técnicos (SIGINT e IMINT).
8.6. Inteligencia económica
La creciente integración de los asuntos económicos en el concepto de seguridad ha dado lugar a la necesidad de elaborar inteligencia sobre ellos. Sin que exista unanimidad en el concepto de inteligencia económica, esta puede entenderse como la que se ocupa de la obtención y el procesamiento de la información financiera, económica y empresarial de un Estado para permitir una eficaz salvaguarda de los intereses nacionales, tanto en el interior como en el exterior.
En el mismo ámbito de la inteligencia económica también se incluyen otras acciones complementarias más específicas, como la sensibilización de las empresas nacionales sobre la necesidad de adoptar medidas preventivas contra el espionaje económico, la realización de análisis macroeconómicos de los Estados en los que se pretende invertir o hay inversiones de empresas del país, la protección interna y la promoción y protección externa en el mercado de la industria nacional, el control del tráfico de material de defensa y de doble uso civil y militar, y la creación de una cultura de inteligencia económica.
Las fuentes de información abiertas predominan para la producción de inteligencia económica, pero también se hace uso, cuando es necesario, de información secreta obtenida por medios encubiertos. Esto último es lo que diferencia la inteligencia económica que realizan los servicios de inteligencia y la que producen otros órganos de la Administración o empresas privadas especializadas.
La acepción «inteligencia económica» tuvo su origen en la década de 1970-80 en Francia, entendiéndola como los conocimientos que precisan el Estado o las empresas para alcanzar sus objetivos estratégicos. El Informe Martre[4] (1994), enfocado esencialmente al desarrollo de la inteligencia económica y estratégica de las empresas, definió la inteligencia económica como «el conjunto de acciones coordinadas de investigación, tratamiento y distribución, en vista a su explotación, de la información útil a los actores económicos −ya sean empresas u organizaciones estatales−. Informaciones que se han de aportar mediante métodos legales, con todas las garantías de protección necesarias para preservar el patrimonio empresarial en las mejores condiciones de coste y marco temporal».
La inteligencia económica «implica ir más allá de acciones parciales provenientes del análisis documental, de acciones de vigilancia, de la protección del patrimonio competitivo, de acciones de influencia, etc., para lograr una intencionalidad estratégica y táctica»[5]. De esta forma se entronca con la estrategia y su puesta en acción (táctica), y es el elemento esencial de investigación e interpretación de las intenciones y capacidades de los competidores, ya sea como defensa de la posición actual del Estado o empresa que la practica, o como medio para obtener una supremacía concreta de acuerdo con los intereses estratégicos. La inteligencia económica, por tanto, se apoya en la vigilancia del entorno competitivo, diferenciándose de otros procesos o sistemas de inteligencia en tres elementos principales: sus fines son exclusivamente económicos; trabaja con fuentes abiertas; y debe ser ética en todas sus acciones.
No obstante estas descripciones de la inteligencia económica en sus orígenes, en el presente siglo se ha empezado a determinar la inteligencia económica como la obtenida a partir de información financiera, económica y empresarial de un Estado, diferenciándola de la competitiva o empresarial, que la realizan las empresas. De esta forma, la inteligencia económica la llevan a cabo tanto los servicios de inteligencia −que utilizan información secreta obtenida por medios encubiertos−, como otros órganos de la Administración, fundamentalmente de los Ministerios de Hacienda y de Economía (o sus órganos adscritos), y empresas especializadas, que sólo utilizan fuentes abiertas.
8.7. Inteligencia competitiva
De la misma forma que se produce con la inteligencia económica, no hay unanimidad en la definición de inteligencia competitiva, que, además, se ha visto identificada en su definición como inteligencia empresarial, como término más moderno que englobaría a la inteligencia competitiva y a la inteligencia de negocios (business intelligence).
El Equipo Económico del CNI definió en 2009 la inteligencia competitiva como «una herramienta de gestión o práctica empresarial que consiste en un proceso sistemático, estructurado, legal y ético, por el que se recoge y analiza información que, una vez convertida en inteligencia, se difunde a los responsables de la decisión para facilitar esta, de forma que se mejora la competitividad de la empresa, su poder de influencia y su capacidad de defender sus activos materiales e inmateriales».
Los objetivos de la inteligencia competitiva son planificar y adoptar medidas para mantener la competitividad de la empresa y afrontar con mayores garantías los rápidos y continuos cambios a los que se ve sometida toda organización. Para lograrlo se ocupa de la obtención y el procesamiento de información sobre los elementos que caracterizan la realidad política, social, económica, cultural, legal y tecnológica que rodea a la empresa y sobre los agentes que actúan en ella. Presta una especial atención a la identificación y el seguimiento de señales indicadoras de cambios significativos en el entorno, por lo que trabaja con datos procedentes del exterior de la organización, que obtiene sobre todo de fuentes de información abiertas.
Por tanto, la diferencia principal entre la inteligencia económica y la inteligencia competitiva es que la económica la realiza el Estado fundamentalmente, mientras que la competitiva la realizan las empresas.
Por otra parte, la diferencia entre la inteligencia competitiva y la de negocios estriba en que la competitiva analiza el entorno de la empresa, utilizando fuentes externas e información abierta; mientras que la inteligencia de negocios se realiza a partir de los datos internos de la propia actividad de la empresa, para mejorar su rendimiento, fidelizar clientes y obtener beneficios.
La práctica de la inteligencia de negocios se basa en el empleo de tecnologías y aplicaciones informáticas que permiten buscar, recuperar, analizar y visualizar de modo unificado datos heterogéneos y dispersos entre diferentes sistemas, con independencia de las aplicaciones empleadas para su creación y almacenamiento y de que estén en ficheros de texto o estructurados en bases de datos. Estas herramientas, haciendo uso de técnicas de minería de información, establecen asociaciones entre los datos y desvelan patrones ocultos, de acuerdo con el cumplimiento de unos criterios estadísticos y preestablecidos, que ayudan a la interpretación. La inteligencia de negocios sirve de apoyo para la gestión de diversas áreas de las empresas, como producción, finanzas, relación con clientes y proveedores, ventas, recursos humanos o logística.
Dentro de la inteligencia competitiva se encuentra incluida la inteligencia de mercados,que se obtiene a partir de la información relevante sobre el mercado en el que la empresa desarrolla su actividad y cuyo fin inmediato es proporcionar conocimiento permanente sobre el mismo, para facilitar el proceso de toma de decisiones al trabajar sobre necesidades específicas de la empresa.
8.8. Inteligencia criminal
También este término concita varias interpretaciones y se presta a confusión con otros conceptos, como inteligencia policial, inteligencia de seguridad pública, investigación criminal, criminología, criminalística, etc.
Inicialmente se entendía como inteligencia policial a la destinada al mantenimiento de la seguridad interior, el orden público y la persecución de la delincuencia. Pero desde finales del siglo XX y en este XXI, la inteligencia criminal abarca un ámbito mucho mayor que el estrictamente policial, al constituir una inteligencia que hoy elaboran, en distintos países, los servicios de inteligencia, las fuerzas armadas, unidades policiales, los servicios de aduanas, el sistema penitenciario, las instituciones financieras e incluso empresas privadas de seguridad.
De esta forma, la inteligencia criminal es un tipo de inteligencia útil para obtener, evaluar e interpretar información y difundir inteligencia necesaria para proteger y promover los intereses nacionales de cualquier naturaleza (políticos, comerciales, empresariales), frente al crimen organizado, al objeto de prevenir, detectar y posibilitar la neutralización de aquellas actividades delictivas, grupos o personas que, por su naturaleza, magnitud, consecuencias previsibles, peligrosidad o modalidades, pongan en riesgo, amenacen o atenten contra el ordenamiento constitucional y los derechos y libertades fundamentales.[6]
En cuanto a su diferenciación con la investigación criminal/policial, también identificada como actividad de policía judicial, la diferencia principal estriba en que esta se realiza al suscitarse un caso y se culmina con los logros investigativos obtenidos, alcanzando su esclarecimiento y resolución, mientras que la inteligencia es permanente; no reacciona ante la comisión de un delito, sino que opera continuamente sobre toda persona, actividad u organización que pueda parecer sospechosa de constituirse en una amenaza o implique un riesgo para la seguridad. Cuando hay ausencia de inteligencia o las medidas que propone no se aplican, el delito ya se ha cometido; el trabajo de inteligencia ha resultado infructuoso y el delito efectivamente materializado pasa a ser objeto de la investigación criminal/policial.
Por consiguiente, la inteligencia no persigue la resolución de un hecho delictivo. No opera en el ámbito de los tipos penales, sino en la esfera de las situaciones predelictuales; intenta aportar conocimiento para anticiparse y permitir a las autoridades neutralizar o disuadir las amenazas, riesgos y conflictos (carácter preventivo). La investigación criminal/policial actúa de forma absolutamente represiva, ya que interviene después de la comisión de un delito específico para identificar a sus autores y aportar las pruebas legales que posibiliten su procesamiento penal.
Otro aspecto que facilita la confusión de los términos lo constituye el hecho de que una misma información puede tener una doble finalidad: constituir indicios y pruebas para descubrir los elementos integrantes del hecho criminal para su enjuiciamiento (investigación criminal/policial), o constituir insumos que empleará el analista de inteligencia, que no el investigador policial, en la elaboración del producto de inteligencia, con independencia del momento exacto en el que se produce el conocimiento, sea este anterior o posterior al hecho delictivo. La afluencia continua de nuevos datos fruto de la comisión de delitos genera la imagen errónea de que siempre se llega tarde, resultando infructuoso cualquier esfuerzo por elaborar inteligencia.
Esta confusión se produce porque la fase de recolección de información para la elaboración de inteligencia (policial y criminal) y la fase de recolección de información, indicios y pruebas de la investigación criminal/policial, en muchas ocasiones discurren de forma simultánea versando sobre los mismos objetivos. Esta circunstancia genera confusos episodios de solapamiento al resultar harto complejo establecer las líneas de demarcación entre ambas, para identificar con nitidez donde empieza una y acaba la otra, por lo que el elemento esclarecedor reside en identificar sus utilidades y fines, que sí están bien diferenciados[7].
Por su parte, la inteligencia de seguridad pública, conocida por el acrónimo CRIMINT, puede definirse como la que sirve para identificar y neutralizar las amenazas reales y potenciales a la seguridad del Estado o a su orden constitucional resultante de actos de subversión, terrorismo y espionaje cometidos por personas, Estados o grupos nacionales o extranjeros. Asimismo, este término se aplica a las actividades de apoyo a las funciones de la policía, el mantenimiento del orden público y de la justicia criminal.
También relacionada con la inteligencia criminal y dentro de la CYBINT (ver punto 5.3.1) se encuentra la inteligencia de medios sociales (SOCMINT), que es la que está referida a las redes sociales y medios de comunicación de plataforma digital y los datos que las mismas generan. Contribuye a la seguridad pública a través de la identificación de actividades criminales, de la alerta temprana sobre desórdenes y amenazas al orden público, o a la construcción de conocimiento inmediato en situaciones rápidamente cambiantes. Es un tipo de inteligencia reciente que precisa un desarrollo legal.
8.9. Inteligencia sanitaria
Conocida como MEDINT y de aplicación fundamentalmente militar, es la que se deriva de la obtención y análisis de los elementos de epidemiología y ambientales en una determinada zona, así como los riesgos nucleares, biológicos, químicos y radiológicos (NBQR) para las fuerzas propias; de las capacidades sanitarias disponibles, propias y adversarias; de la infraestructura sanitaria y del personal sanitario existente en el teatro donde se efectúan las operaciones, tanto para su explotación en beneficio propio, como para la atención de la población civil de futuras zonas ocupadas[8].
8.10. Inteligencia de objetivos
Identificada con el acrónimo inglés TARINT es el tipo de inteligencia que facilita la selección de objetivos militares y realiza la evaluación de daños. En el apoyo a la selección de objetivos, trata de describirlos y situarlos. En caso de un objetivo compuesto por varias partes, o conjunto de blancos, indica sus vulnerabilidades, importancia relativa y la elección más conveniente de medios y momento de ataque para producir los efectos deseados. Los aspectos que deciden el ataque a un objetivo son su facilidad para ser identificado, la importancia relativa para contribuir a obtener el resultado final y el cumplimiento de la misión.
La evaluación de daños proporciona la información necesaria para conocer si se han logrado los efectos deseados.
8.11. Inteligencia psicológica
Conocida como PSYOPS es el tipo de inteligencia necesaria para la planificación, conducción y evaluación de las operaciones psicológicas, que proporciona información relativa a opiniones, creencias, actitudes o aspiraciones de las audiencias objetivo, así como sobre aspectos de carácter político, económico, militar, social y cultural de interés para las operaciones y para determinar los efectos que los productos y actividades de las operaciones psicológicas tienen en las audiencias objetivo.
8.12. Inteligencia sociocultural
Identificada por el acrónimo SOCINT, se elabora a partir de la información sobre asuntos sociales, políticos, económicos y demográficos para comprender las creencias, valores, actitudes y comportamientos de un actor o grupo social determinado, con el fin de prevenir y neutralizar amenazas a la seguridad. Es un tipo de inteligencia complementario de otras.
8.13. Inteligencia cultural
Bajo el acrónimo CULINT se identifica la inteligencia elaborada a partir de información social, política, económica y demográfica que proporciona un conocimiento que permite comprender la forma de actuar y las motivaciones de cualquier tipo de actor (aliado, neutral o enemigo), así como anticipar sus reacciones ante determinados acontecimientos. Analiza su cultura para entender mejor su visión del mundo, sus comportamientos y su forma de tomar decisiones. Ello hace posible interpretar mejor sus acciones y, por tanto, diseñar estrategias de cooperación o reacción mucho más efectivas. Es también un tipo de inteligencia identificado recientemente, que se está desarrollando debido a las cada vez más numerosas actividades multinacionales en respuesta a la globalización de las amenazas.
8.14. Inteligencia holística
Es la que se elabora por cualquier servicio que debe abordar el análisis y la interpretación de un asunto o de una situación con una perspectiva multidisciplinar, integrando información proveniente de múltiples fuentes y realizada por un equipo de trabajo de especialidades y procedencias diversas formado exclusivamente para la ocasión.
El concepto de inteligencia holística es relativamente reciente y está motivado por la continua ampliación del concepto de seguridad y, por tanto, el aumento de la complejidad de los asuntos que atienden los servicios de inteligencia, a lo que cabe añadir la sobreabundancia de información que se obtiene por medios técnicos.
Rafael Jiménez Villalonga es Emérito del Centro Nacional de Inteligencia y profesor delMáster on-line en Estudios Estratégicos y Seguridad Internacional de la Universidad de Granada.
Bibliografía
Díaz Fernández, Antonio M. (director): Conceptos fundamentales de inteligencia. Tirant lo Blanch, Valencia, 2016.
Díaz Fernández, Antonio M. (director de obra): Diccionario LID INTELIGENCIA Y SEGURIDAD. LID Editorial Empresarial, 2013.
Esteban Navarro, Miguel Ángel (coordinador): Glosario de inteligencia. Ministerio de Defensa, Madrid, 2007.
González Cussac, José Luis (coordinador): Inteligencia. Tirant lo blanch, Valencia, 2012.
Inteligencia Militar Terrestre-Manual de Fundamentos, Exército Brasileiro, 2015. En línea,http://bdex.eb.mil.br/jspui/bitstream/123456789/95/1/EB20-MF-10.107.pdf(Consultado 24jun2017).
Jiménez Moyano, Francisco. Manual de Inteligencia y Contrainteligencia. CISDE Editorial, 2012.
Kent, Sherman: Strategic Intelligence for American World Policy. Princeton, NJ, 1949. Edición en castellano 4ª Edic.: Buenos Aires, Editorial Pleamar, 1986.
Martre, Henri. Intelligence économique et stratégie de enterprises. Rapport du Commisariat Général au Plan. París. La Documentation franÇaise, 1994. En línea,http://www.entreprises.gouv.fr/files/files/directions_services/informati…. (Consultado 02jul2017).
[1] Kent, Sherman: Strategic Intelligence for American World Policy. Princeton, NJ, 1949. Edición en castellano: 4ª Edic. Buenos Aires, Editorial Pleamar, 1986.
[2] Sánchez Blanco, E.: OSINT (inteligencia de fuentes abiertas), en Díaz Fernández, A. M.:Conceptos fundamentales de inteligencia. Tirant lo blanch, Valencia, 2016, pp. 274-276.
[3] Inteligencia Militar Terrestre-Manual de Fundamentos, Exército Brasileiro, 2015. En línea, http://bdex.eb.mil.br/jspui/bitstream/123456789/95/1/EB20-MF-10.107.pdf(consultado 24jun2017).
[4] Martre, Henri (1994), Intelligence économique et stratégie de enterprises. Rapport du Commisariat Général au Plan. París. La Documentation franÇaise. En línea,http://www.entreprises.gouv.fr/files/files/directions_services/informati…. (Consultado 02jul2017).
[5] Op. cit.
[6] Sansó-Rubert Pascual, D. ¿Inteligencia criminal?: Líneas de demarcación y áreas de confusión. La necesidad de reevaluar su rol en la esfera de la seguridad y en la lucha contra la criminalidad organizada, en Velasco, Fernando y Rubén Arcos (eds.), Cultura de Inteligencia, un elemento para la reflexión y la colaboración internacional, Plaza y Valdés. Madrid. 2012. pp. 347-360.
[7] Sansó-Rubert Pascual, D. Inteligencia criminal, en Díaz Fernández, Antonio, (Dtor).Conceptos fundamentales de inteligencia. Tirant lo blanch. Valencia. 2016. pp. 223-231.
[8] Jiménez Moyano, F. Manual de Inteligencia y Contrainteligencia. CISDE Editorial. 2012. p. 33.
Editado por: Grupo de Estudios en Seguridad Internacional (GESI). Lugar de edición: Granada (España). ISSN: 2340-8421.
Fuente: seguridadinternacional.es, 26/11/18.
Más información:
Inteligencia es anticipación
Antecedentes del Ciclo de Inteligencia de Sherman Kent
La Inteligencia y sus especialidades en la Sociedad del conocimiento
______________________________________________________________________________

______________________________________________________________________________
Vincúlese a nuestras Redes Sociales: LinkedIn YouTube Twitter
______________________________________________________________________________


.
.
La Inteligencia y sus especialidades en la Sociedad del conocimiento
octubre 20, 2023
De los espías a las computadoras, el creciente uso de la inteligencia en el siglo XXI
Por Gustavo Ibáñez Padilla.

Vivimos en un mundo de datos, los cuales crecen día a día en forma exponencial.
Cada transacción, cada interacción, cada acción es registrada y genera a su vez nuevos datos (la hora del registro por ejemplo) llamados metadatos. Todo este creciente cúmulo información puede ahora ser procesado a gran velocidad (big data) a fin de extraer conclusiones.

.
Captar y procesar datos, organizarlos, transformarlos en información y luego en conocimiento para facilitar la toma de decisiones es lo que se conoce como ‘inteligencia’. Hace algún tiempo se consideraba una función estratégica al servicio de las máximas autoridades, para asegurar la defensa de la nación. Así fue en los inicios, cuando se profesionalizó la actividad de la mano de Sherman Kent en los Estados Unidos y dio nacimiento a la agencia central de inteligencia, más conocida como la CIA. Por supuesto no era algo nuevo, ya nos hablaba sobre ello Sun Tzu en el siglo VI antes de Cristo. Pero fueron los estudios de Kent los que le dieron la formalidad de una disciplina, a mediados del siglo pasado.

Con el paso de los años la inteligencia se fue expandiendo al tiempo que crecía la capacidad de procesar información. Así surgieron los adjetivos que califican al sustantivo ‘inteligencia’ para diferenciar su múltiples variedades, llegando entonces a una compleja taxonomía del concepto inteligencia.
Al extender su ámbito la inteligencia se hizo accesible a la sociedad en general y comenzaron a usarla las empresas y organizaciones en general (business intelligence), para esta democratización de sus usos colaboró en forma importante la tremenda baja en los costos de adquisición y procesamiento de la información, que corría al ritmo de los avances informáticos.
Podemos mencionar como casos de éxito de inteligencia de negocios los sistemas de precios dinámicos en las aerolíneas, que acoplan los precios a las variaciones de oferta y demanda; la plataforma de venta online de Amazon, que recomienda otros artículos según los intereses del comprador y Netflix, que sugiere películas y series y orienta el rumbo de las nuevas producciones.
Es así que con la evolución de la disciplina comienzan a solaparse las áreas de influencia de la inteligencia de negocios, con la inteligencia criminal, la inteligencia financiera, la inteligencia estratégica y podríamos seguir hasta el cansancio…
Vemos que con el paso del tiempo el concepto de inteligencia ha ganado fuerza, profundidad, densidad y trascendencia. En una sociedad del conocimiento esto resulta absolutamente lógico y natural.
Pero dejemos ahora el análisis en abstracto y veamos algunos ejemplos concretos que nos muestren el enorme potencial de este concepto.
Imaginemos una organización criminal que comienza a operar una instalación clandestina de marihuana, en los suburbios, mediante el cultivo hidropónico. Esta nueva actividad se evidenciará por un consumo eléctrico superior al usual de una zona residencial, que quedará registrado en las bases de datos de la compañía de electricidad.

.
Al mismo tiempo, es probable que el nuevo suministro de droga ilegal a buen precio incremente el tránsito de consumidores y se produzca un aumento de la conflictividad y de delitos menores, lo cual podría percibirse en los registros de un eficiente mapa del delito.
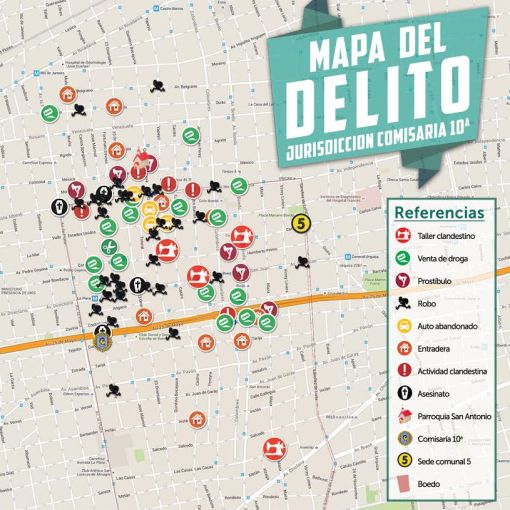
.
También podrían aumentar las consultas a los servicios de guardias de los hospitales de la zona, motivados por un creciente número de intoxicaciones por estupefacientes.
Todas estas pequeñas variaciones en los registros de datos podrían detectarse gracias al eficaz empleo de la inteligencia de negocios, que permite relacionar múltiples bases de datos haciendo evidente la anomalía generada por el nuevo invernadero clandestino.

.
Es interesante prestar atención a que no fue necesario realizar acciones tradicionales de inteligencia criminal, ni disponer de informantes o agentes encubiertos, que realicen las usuales tareas de inteligencia en búsqueda de los narcotraficantes. Tan solo fue preciso disponer de un sistema de información que relacione distintas bases de datos, que registran en forma habitual y monótona inmensas cantidades de información, y de esta forma poner en evidencia la “perturbación” generada por el accionar de los malvivientes.
Vemos como la superposición de inteligencia de negocios con inteligencia criminal permite obtener resultados en forma casi automática y a mucho menor costo.
También puede tomarse como ejemplo el cruce de datos de llamadas telefónicas que nos permite evidenciar relaciones entre distintas personas y prácticamente descubrir acciones conspirativas, sin necesidad de conocer el contenido de las comunicaciones y sin tener que recurrir a escuchas judiciales (ej: asesinato del fiscal Alberto Nisman, enero 2015).
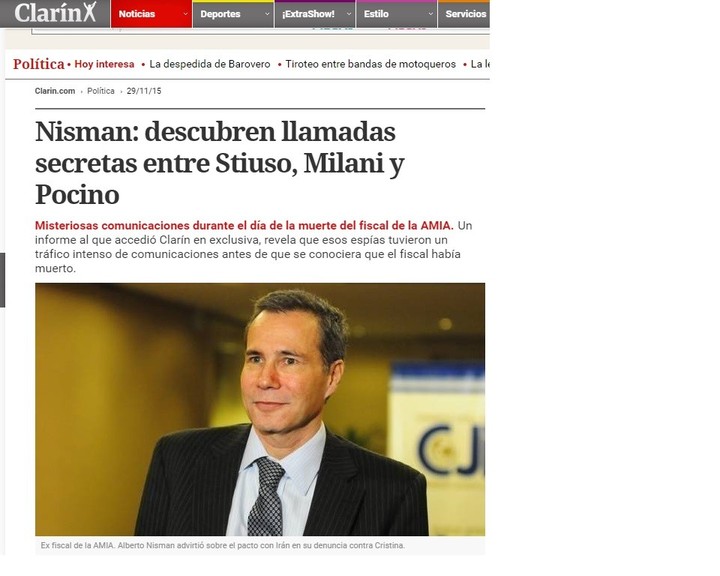
.
Evidentemente, la sociedad en general y la seguridad nacional pueden beneficiarse cada día más del empleo de sistemas avanzados de análisis de inteligencia, capaces de explotar de manera eficaz y eficiente los crecientes volúmenes de datos derivados de los omnipresentes sistemas de captación y procesamiento de información.
La inteligencia en todas sus variantes es indispensable para el desempeño óptimo de las empresas y organizaciones en general y el eficaz accionar de las agencias gubernamentales que persiguen al crimen organizado, los grupos terroristas y cualquier otra amenaza contra la nación.
Fuente: Ediciones EP, 2019.
Información sobre Gustavo Ibáñez Padilla
Más información:
¿Qué es la inteligencia criminal?
La geolocalización y la investigación policial
Antecedentes del Ciclo de Inteligencia de Sherman Kent
Business Intelligence aplicada en el análisis de Inteligencia Criminal
______________________________________________________________________________
Vincúlese a nuestras Redes Sociales: LinkedIn YouTube Twitter
______________________________________________________________________________

.
.
.
¿Qué es la Inteligencia Turística?
junio 15, 2023
Por Inteligencia Turística hacemos referencia a la utilización de los análisis de datos globales y actualizados al proceso de toma de decisiones en el sector del turismo. Gracias a la utilización de esta información en tiempo real reducimos el margen de error en nuestras futuras iniciativas pudiendo prever futuros desenlaces.

.
La Inteligencia Turística por tanto es la aplicación directa del Big Data, una tecnología que ya desde hace años está teniendo una gran repercusión en las compañías.
Las empresas turísticas disponen día a día de una inmensa cantidad de datos a través de múltiples canales, pudiendo ahora gracias a esta tecnología aprovecharse de esta información valiosa para dar un mejor servicio a sus clientes, aumentar su satisfacción e incrementar los ingresos de la empresa.
Estos datos nos dan una oportunidad para identificar patrones de demanda del viajero a lo largo de todo su proceso de compra, pudiendo adaptarse de esta forma el propio destino.
Gracias a este tipo de herramientas podemos entender el tráfico de turistas y comprender a su vez la cantidad y la calidad de la demanda. Ahora podemos conocer sus pautas de comportamiento digital y a través de estos datos decidir las posteriores estrategias.
La capacidad de medición del Big Data puede ser fundamental para los destinos y para todos los negocios que forman parte de él. Así, cualquier punto de interacción con el viajero puede ser un punto de recogida de datos de satisfacción de nuestros clientes.
El éxito en la gestión de un destino depende en gran parte de la gestión de la información, ya que la calidad del proceso de toma de decisiones se encuentra condicionado por la calidad de la información que tenemos. Frecuentemente, no se toma una decisión adecuada por carecer de datos adecuados, o por la dificultad de analizarlos a tiempo.

.
Para un destino, la cuestión ya no es sólo de disponer de información de valor sobre el entorno, sino disponer de la misma antes que sus potenciales competidores.
Por tanto para competir con otros destinos tenemos la necesidad de diferenciarnos, apoyándonos en el análisis ad hoc de la información para generar conocimiento y crear ventajas competitivas y nuevas oportunidades.
Conociendo el Customer Journey de nuestro huésped podremos personalizar nuestro trato y servicio, fidelizándole y acompañándole desde el momento en que decide viajar, su método de transporte, alojamiento y recomendando servicios/lugares en el destino.
Hay que tener en cuenta que el comportamiento de los viajeros está cambiando, más aún tras el impacto del COVID-19 que ha afectado en gran medida al sector turístico. Tenemos por un lado a los viajeros de negocios y a los vacacionales, o por ejemplo el de las familias, parejas o personas que viajan solas que son diferentes perfiles. Además tenemos dos grandes grupos a tener en cuenta: los resilientes (viajeros que están activamente buscando para poder viajar tan pronto como les sea posible) y los conservadores (que están inseguros y se les tendrá que volver a ganar la confianza para conseguir que tengan ganas de viajar).
Fuente: curieplatform.com, 2021
La Inteligencia Turística es la aplicación del concepto de Inteligencia de Negocios en el área del Turismo.
www.economiapersonal.com.ar

.
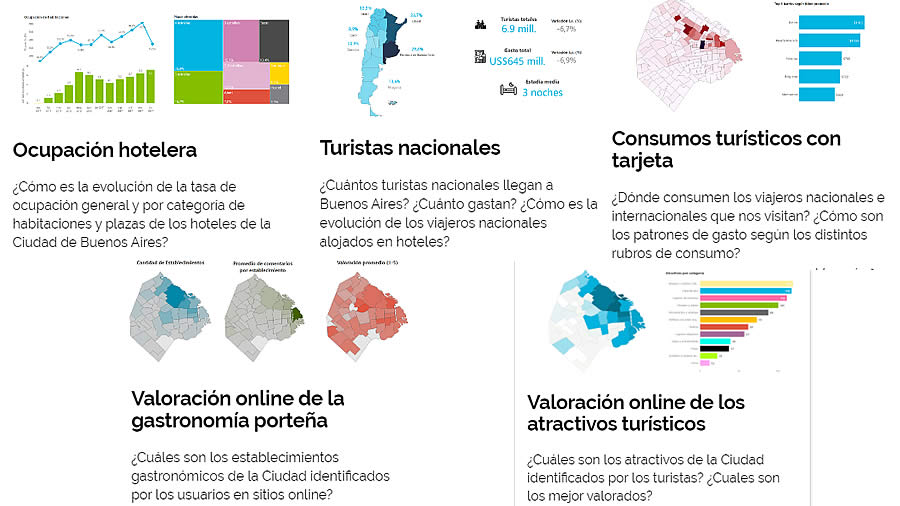
¿Qué clases de datos turísticos se analizan?
Existe un enorme y creciente caudal de datos que pueden ser utilizados para identificar y predecir las tendencias turísticas. Éstos se complementan con datos históricos y estadísticos que ya se empleaban tradicionalmente.
En tiempo real se trabaja para agregar fuentes de datos que aportan una visión global y representativa del turismo a nivel mundial. Las siguientes son algunas de las tipologías de datos turísticos estudiadas:
- Datos de Conectividad Aérea: programaciones de vuelos, precios, búsquedas y reservas de vuelos.
- Datos de Comportamiento turístico en Redes Sociales: interacciones espontáneas en Redes que nos muestran tendencias de percepciones e intereses turísticos.
- Datos de Alojamiento: hoteles, alquiler vacacional, precios y comentarios.
- Datos de Gasto: gasto turístico a través de tarjetas de crédito, débito y otros canales de pago.
- Datos de Movilidad: conectividad de dispositivos móviles a las antenas de un destino para cuantificar visitantes y movilidad real de los turistas.
La superposición de todas estas capas de datos permite construir un conocimiento sin precedentes a cerca de las dinámicas turísticas, facilitando las decisiones de los operadores turísticos y mejorando el retorno directo de la inversión.
EP.
Más información:
Inteligencia de Negocios
La Inteligencia y sus especialidades en la Sociedad del conocimiento
La Ciudad de Buenos Aires presentó un nuevo sistema de inteligencia turística
Tableros de Control: https://turismo.buenosaires.gob.ar/es/observatorio
Presentación del sistema: https://youtu.be/C1LBAH2gq2A (Ver desde el minuto 31)
___________________________________________________________________
.
.
.
Propaganda y Contrapropaganda
febrero 16, 2022
El objetivo de la Propaganda es la consecución, mantenimiento o refuerzo de una posición de poder por parte de un sujeto emisor; la ideología desempeña un papel funcional en el cumplimiento de ese objetivo en tanto que contenido discursivo de la comunicación propagandística.
.

.
La propaganda es una forma de comunicación que pretende influir en la actitud de las personas respecto a alguna causa o posición, presentando solamente un lado de un argumento.
.

.
La Propaganda es un discurso de poder.
.
.

.

.

.

.

Más información:
Rumores y mentiras al estilo Goebbels
Desinformación versus Decepción
Manipulación mediática
Un mundo que cambia. César Vidal
Ciberespionaje, influencia política y desinformación
.
.
Los sesgos cognitivos y la Inteligencia de Negocios
enero 26, 2022
Sesgos Cognitivos en la fase de obtención de Inteligencia
Por Cristina López Tarrida.
Analista e Investigadora especializada en Influencia, Desinformación y Propaganda.
.
Desde que la tecnología ha irrumpido con fuerza en el ámbito de la Inteligencia, cada vez es más frecuente observar cómo existe cierta tendencia en algunos círculos a considerar, equivocadamente, que las herramientas de software constituyen los cimientos sobre los que se sustenta el análisis, relegando a la mente del analista a un mero complemento de dichas herramientas.
Esta fe ciega en el software y en los programas automatizados de obtención y análisis, no deja de ser consecuencia de algunos de los sesgos cognitivos de nuestra mente, donde el inesperado beneficiario del error de juicio ha cambiado de protagonista, mutando del humano a la máquina. Sin ir más lejos, el sesgo por exceso de confianza ha experimentado una metamorfosis, de modo que ese exceso de confianza no es ya en la propia capacidad de evaluación, como en el heurístico tradicional, sino en la capacidad de las herramientas. Pero no es éste el único caso. Si pensamos, por ejemplo, en el sesgo del intruso, referido a la tendencia a valorar la consulta realizada a terceros como más objetiva y confiable por el hecho de suponerla más imparcial y libre de intereses, nos daremos cuenta de que la máquina es ahora el tercero en “concordia”, de modo que no es de extrañar que, sumado al deslumbramiento que ya de por sí provocan las capacidades demostradas por los algoritmos, este sesgo nos impida evaluar con mejor criterio la fiabilidad de los resultados proporcionados por los mismos. No podemos obviar que esos algoritmos no dejan de ser cajas negras de las que ignoramos, entre otras cosas, sus reglas de filtrado y priorizado de información. ¿Cómo selecciona los datos uno de estos algoritmos? ¿Qué criterio hay detrás de la categorización de esta información?
No podemos obviar que esos algoritmos no dejan de ser cajas negras de las que ignoramos, entre otras cosas, sus reglas de filtrado y priorizado de información.
Si nos centramos en los motores de búsqueda de información, la cuestión se vuelve ya de por sí mucho más compleja. Hay quienes creen que realizar las búsquedas desde el anonimato o la privacidad que permite el llamado “modo incógnito” nos libra de obtener una información sesgada por nuestro perfil de intereses, por nuestro filtro burbuja. Puede que logremos evadir el cerco de nuestras propias preferencias, pero, ¿acaso el orden de los resultados de las búsquedas no sigue obedeciendo a criterios de preferencias o intereses de la mayoría, aunque estos sean más genéricos? ¿Acaso no responden a los resultados de búsqueda consultados con mayor frecuencia por los usuarios?
Y donde el analista ha de tener mayor cuidado, si cabe, es en los criterios de búsqueda. Es ahí donde aparece un sesgo que considero que ha de ser especialmente vigilado por parte de cualquier profesional que se dedique a la investigación o al análisis. He dado en bautizarlo como sesgo de proyección en la búsqueda o sesgo de búsqueda condicionada, y consiste en la proyección de la propia opinión, prejuicio o tendencia ideológica en los términos que se emplean para realizar las consultas, de modo que los resultados proporcionados por los motores de búsqueda responderán de acuerdo a este filtro. Un simple ejemplo de cómo funciona la activación de este sesgo podemos deducirlo pensando en la sustancial diferencia de resultados que podríamos obtener a partir de los términos de búsqueda “proceso secesionista” y “proceso independentista”. El analista ha de cuidarse de que sus búsquedas no supongan ya de antemano un filtro ideológico para el análisis. ¿Somos lo suficientemente pulcros a la hora de seleccionar los conceptos con los que abordamos la obtención de información? ¿Reflejan de alguna manera nuestra forma de pensar o creer?
El analista ha de cuidarse de que sus búsquedas no supongan ya de antemano un filtro ideológico para el análisis.
Después de todo, quizás debamos admitir que la obtención de inteligencia de fuentes abiertas (OSINT), especialmente cuando ésta se circunscribe a Internet, medios web y sociales es, de todas, la más sesgada, ya que, a los sesgos habituales del analista, se suman nuevos sesgos donde lo tecnológico implica un nuevo reto cognitivo. En cualquier caso, no deja de ser todo esto únicamente una primera aproximación a la cuestión, una breve reflexión «en voz alta»; un intento de que abordemos el uso de las herramientas con la cautela debida, con el sentido crítico exigible en el ámbito de la Inteligencia. Este asunto, sin duda, requiere de un debate profundo del que esta deliberación sólo pretende ser un preámbulo. Sin embargo, sirva de alegato final la defensa fehaciente de que las herramientas son un complemento del trabajo del analista, no el analista un complemento del software. Cuando el analista se convierte en un mero recolector de información, deja de ser analista. Que las herramientas no nos cieguen.
Fuente: opinionmakers.es, 09/12/21.

Más información:
Cómo los sesgos cognitivos afectan nuestro juicio
.
.
El Analista de inteligencia
enero 26, 2022
«Cuando los analistas son demasiado precavidos al hacer juicios estimativos sobre amenazas, se los culpa de no haber avisado. Sí son demasiado agresivos al lanzar la advertencia, se les critica por alarmistas.» Jack Davis
Artículo recomendado:

Qué es el análisis de inteligencia
El análisis de inteligencia es el proceso de evaluar y transformar los datos e información en conocimiento útil. Este conocimiento útil es solicitado y se genera para tomar una decisión.
El análisis de inteligencia comparado con el método científico
Aunque el análisis de inteligencia se base en el método científico, no son lo mismo. Tienen bastantes diferencias, principalmente por las temáticas que suelen analizarse: estrategias a largo plazo, nivel de riesgo o amenaza, probabilidad de que ocurra un evento social o político, etc.
En este tipo de análisis e investigaciones, normalmente llevados a cabo por empresas, gobiernos, organismos públicos y organizaciones diversas, se encuentran con:
- Elevada incertidumbre.
- Escasez de información contrastada y objetiva.
- Multitud de fuentes de información con diferentes grado de credibilidad.
- Diversidad de variables y multitud de actores.
- Falta de relaciones causales objetivas sobre la temática analizada.
- Necesidad de inmediatez o urgencia para llegar a conclusiones.
- Obligatoriedad de discreción y secreto.
Todas las organizaciones toman decisiones, especialmente aquellas que están más expuestas a riesgos, amenazas u oportunidades. En estos casos la no decisión no es una opción viable.
Para poder tomar una buena decisión, es necesario analizar previamente la información disponible e incluso la no disponible. Para ello se presentan dos opciones: el método científico o el análisis de inteligencia.
El análisis de inteligencia tiene muchas ventajas ya que permite racionalizar procesos de decisión complejos, con multitud de variables, diversidad de fuentes de información de diferentes grados de confianza cada una, en entornos con una alta incertidumbre.
Por otro lado, tiene algunos inconvenientes. El análisis de inteligencia, al depender de personas, no es absolutamente objetivo ni exacto, ni permite tomar una decisión correcta con seguridad ya que se basa en intuición y sus conclusiones no tienen la integridad y solidez empírica del método científico.
Por este motivo, los informes de inteligencia usualmente terminan ofreciendo una serie de estimaciones y probabilidades que reducen la incertidumbre y permiten tomar decisiones de forma más racional, pero nunca totalmente objetiva.
Si el análisis de inteligencia no es un método 100% válido para tomar decisiones objetivas, ¿por qué no se utiliza el método científico para tomar decisiones?
El método científico no resulta una técnica viable para la toma de decisiones objetivas ya que necesita de información totalmente confiable y contrastada así como tiempo para validar o refutar las hipótesis. Esas características dificilmente se disponen en el mundo empresarial o institucional, que es donde más se emplea el análisis de inteligencia.
Por tal motivo cada vez son más las organizaciones que buscan y demandan profesionales de la inteligencia, especialmente Analistas de Inteligencia para Unidades y Departamentos de Estrategia, Análisis o Seguridad, tanto en grandes empresas como en instituciones públicas.
Más información:
Inteligencia Estratégica
Una Taxonomía del concepto Inteligencia
El uso de la Inteligencia en los negocios
La Inteligencia y sus especialidades en la Sociedad del conocimiento
.
.
La inteligencia estratégica en las organizaciones políticas y empresariales. Seminario Internacional. Julio 2021
junio 16, 2021
SEMINARIO INTERNACIONAL
“LA INTELIGENCIA ESTRATÉGICA EN LAS ORGANIZACIONES POLÍTICAS Y EMPRESARIALES”
FECHAS: 16 y 17 de julio
- De 18:00 Hs. a 21:00 Hs.
- De 09:00 Hs. a 12:00 Hs.
Medio: Plataforma Zoom
Responsable: ITAJU COMUNICACIONES CONSULTORÍA
INVITADOS ESPECIALES: Dr. Euclides Acevedo – Dr. Horacio Galeano Perrone
AGENDA
SUBTEMAS:
Viernes 16-07-21
18:00 a 18:10: Saludo a los ponentes e invitados especiales – mensaje de bienvenida
Dra. María Amelia Britos Bogado
18:10 a 18:30 Hs. La inteligencia estratégica, una herramienta necesaria para la toma decisiones, un imperativo del mundo actual. Dr. Ricardo Spadaro. Argentina.
18:30 a 19:00 Hs. Aplicación de la inteligencia en organizaciones empresariales y el valor que implica: Ing. Gustavo Ibáñez Padilla. Argentina
19:00 a 19:30 Hs. La inteligencia estratégica y el crimen organizado. Desafíos para el Siglo XXI: Prof. Mg. Marcelo Luis Martinengo. Argentina
19:30 a 20:00 Hs. La inteligencia estratégica y la seguridad interna: Crio. Antonio Gamarra. Paraguay
20: 00 a 20:30 Hs. La inteligencia estratégica y la construcción de escenarios prospectivos: Cnel. Hugo Vera. Paraguay
20:30 a 21:00 Hs. Preguntas del auditorio – Conclusiones.
Sábado 17-07-21 Moderadores: Lic. José María Condomí (Analista de Inteligencia Estratégica Militar – 2005. Escuela de Inteligencia de las Fuerzas Armadas Argentinas y Dra. María Amelia Britos Bogado (Máster en Planificación Estratégica nacional – Ministerio de Defensa Nacional de Paraguay – año 2006)
09:00 a 09:15. Saludo e introducción a los temas. Dr. Horacio Galeano Perrone
09:15 a 09:40. La inteligencia política en las instituciones gubernamentales. Mg. Alessandra Martin. México.
09:40 a 10:20. La inteligencia y la comunicación política: Dr. Ricardo Amado Castillo. Venezuela – Mg. Alejandra Cáceres. Argentina.
10:20 a 11: 00. La inteligencia artificial aplicada al sector público y privado. Lic. Facundo Armas. Argentina
11:00 a 11:20. Herramientas de la inteligencia humana. La comunicación no verbal – inteligencia comportamental: Mg. Marisa Barrera. Argentina.
11:20 a 11:40. Debate con el auditorio. Conclusiones
11: 40 a 12: 00. Entrega virtual de Certificados.
Agradecimiento.

.

.
.
.
.
El Teorema de Bayes en el Análisis de Inteligencia
julio 1, 2020
“Bayes ingenuo” en apoyo del análisis de inteligencia
Por José-Miguel Palacios.
Un interesante artículo de Juan Pablo Somiedo[1], aparecido a finales de 2018, nos recordaba que el teorema de Bayes[2], en su versión más elemental (lo que se suele llamar “Bayes ingenuo”) puede seguir siendo útil en análisis de inteligencia.
El teorema de Bayes en el análisis de inteligencia
Se puede argumentar que todo análisis de inteligencia es bayesiano en su naturaleza. En esencia consiste en obtener unas evidencias iniciales, simples fragmentos de una realidad bastante compleja, para formular después hipótesis explicativas, recolectar más evidencia y verificar cuál de nuestras hipótesis se ajusta mejor a la evidencia disponible. Algo que no es esencialmente distinto de la “lógica bayesiana”, es decir, de ir modificando nuestras valoraciones subjetivas iniciales a medida que vamos recibiendo evidencias más o menos consistentes con ellas.
En las décadas de 1960 y 1970 hubo varios intentos de utilizar directamente el teorema de Bayes para fines de análisis de inteligencia. Algunos de ellos han sido documentados en las publicaciones del Centro para el Estudio de la Inteligencia de la CIA[3]. Los resultados, sin embargo, no llegaron a ser plenamente convincentes. Y una de las razones principales fue que el mundo real resultó ser demasiado complejo para los modelos elementales que deben considerarse al utilizar “Bayes ingenuo”. Y es que estos modelos presuponen la invariabilidad de la situación inicial (oculta a nuestros ojos), así como la independencia absoluto de los sucesos que vamos considerando. Este problema puede resolverse mediante el uso de “redes bayesianas”[4] y los resultados son matemáticamente correctos, aunque aquí el principal problema radica en conseguir modelar correctamente la realidad. Es el enfoque que fue seleccionado para el programa Apollo[5] y otros similares.
A pesar de todo, y con las debidas precauciones, el uso de “Bayes ingenuo” puede ayudarnos en algunos casos a valorar la evidencia de que disponemos. Para que ello sea así, tendríamos que prestar atención a neutralizar las principales debilidades del método. A saber:
a) Deberíamos utilizar únicamente evidencia relativamente “reciente” (algo que, medido en tiempo, puede tener distintos significados dependiendo de los casos). El problema es que Bayes nos da información sobre una situación preexistente y oculta (por ejemplo, la decisión que puede haber adoptado un determinado líder político) fijando nuestra atención en sus manifestaciones visibles. Si la evolución de la situación es bastante lenta (por ejemplo, la soviética durante el brezhnevismo medio y tardío), podemos asumir que no cambia sustancialmente durante años, por lo que el momento de obtención es escasamente relevante para la valoración de la evidencia. En situaciones más dinámicas, como suelen ser la actuales, las posiciones de los líderes se están modificando continuamente como consecuencia de los cambios que se producen en el entorno. Evidencia relativamente antigua puede referirse a una “situación oculta” que ya no es actual. Por ello, deberíamos utilizar solo evidencia bastante nueva y, si la crisis continúa, prescindir de la más antigua en beneficio de otra más reciente.
b) En la medida de lo posible, el conjunto de las hipótesis debería cubrir la totalidad de las posibilidades existentes, y no debería existir ningún solape entre las diferentes hipótesis. En la práctica, este objetivo es casi imposible de alcanzar, aunque cuanto más nos acerquemos a él, más fiables serán los resultados que obtengamos al aplicar “Bayes ingenuo”.
c) Las evidencias (“Sucesos”) deberían ser de un “peso similar” y no estar relacionadas entre sí[6].

En la práctica
Hemos elaborado una hoja de Excel[7], con la esperanza de que pueda ayudar con los cálculos matemáticos que esta técnica requiere. Para rellenarla, seguiremos los siguiente pasos, sugeridos por Jessica McLaughlin[8]:
1) Creamos un conjunto de hipótesis mutuamente excluyentes y colectivamente exhaustivas relativas al fenómeno incierto que queremos investigar. Como ya hemos explicado, es, quizá, uno de los pasos más difíciles. En general, resulta complicado imaginar hipótesis que sean por completo mutuamente excluyentes (sin ningún solape entre ellas). Y no lo es menos conseguir que el conjunto de ellas agote todas las posibilidades.
2) Asignamos probabilidades previas (pr.previa, en nuestra hoja de cálculo) a cada una de las hipótesis. La probabilidad previa es nuestra estimación intuitiva de la probabilidad relativa de cada una de las hipótesis. Dado que son mutuamente excluyentes y que cubren todas las posibilidades, la suma de las probabilidades previas debe ser 1. En nuestra tabla, expresamos las probabilidades en tantos por ciento.
3) Ahora debemos ir incorporando los “Sucesos” que nos servirán para valorar las hipótesis. El método reajusta las probabilidades de las hipótesis después de cada suceso, por lo que estos pueden añadirse secuencialmente, según se van produciendo o según tenemos noticia de ellos. Una buena elección de sucesos es muy importante para que el método produzca resultados aceptables. Los sucesos deben tener valor diagnóstico (es decir, deben ser más o menos probables según cuál de las hipótesis es la correcta) y, en lo posible, de un “peso” (importancia) similar.
4) Según incorporamos “Sucesos” a la tabla, les asignamos “verosimilitudes” (“verosim.”, en nuestra hoja de cálculo), relativas a cada una de las hipótesis. Se trata para cada caso de la probabilidad estimada por el analista de que el suceso ocurra, suponiendo que la hipótesis que estamos considerando sea correcta. En la tabla, esta probabilidad la expresamos por un entero entre 0 y 100, siendo 0 la imposibilidad total, y 100 la seguridad completa (de que el suceso se producirá suponiendo que la hipótesis se verifica). Obviamente, la suma de todas las verosimilitudes no tiene por que ser la unidad (100% o, según la notación que utilizamos en nuestra tabla, 100).
La propia tabla recalculará las probabilidades de las hipótesis una vez que hayamos computado cada “Suceso”. En nuestra tabla, podemos encontrar estas probabilidades recalculadas en la columna G (“probab.”).
5) Reiteraremos el proceso según añadimos nuevos sucesos. En nuestra tabla, cada nuevo suceso está representado 10 filas más abajo del anterior. Si agotamos los predefinidos en la tabla, podemos añadir más copiando el último “bloque” diez filas más abajo.
Un ejemplo: Crisis de Crimea, marzo de 2020
El proceso puede verse mucho más claro con la ayuda de un ejemplo. Utilizaremos el de la crisis de Crimea de 2014, en particular las dos semanas que siguieron a la caída del Presidente ucraniano Yanukovich, el 21 de febrero. Hemos rellenado la hoja Excel con una serie de “Sucesos” y el resultado puede encontrarse en la hoja prueba_crimea.xlsx[9]. Se trata, evidentemente, de un supuesto didáctico en el que la elección su “Sucesos” y la determinación de las verosimilitudes están condicionados por el interés en ilustrar algunos de los posibles resultados.
Como vemos, la técnica nos permite calcular en todo momento las probabilidades de las diversas hipótesis, y mantener este cálculo actualizado según vamos recibiendo nueva información. Algunas observaciones interesantes:
- a) A fecha 6 de marzo de 2014, consideraríamos casi seguro (probabilidad del 90%) que la intención rusa sea anexionar la península de Crimea.
- b) Sin embargo, unos días antes (según la tabla) no estaría tan claro. El 1 de marzo la hipótesis de la anexión era ya la más probable (55%), pero aún calculábamos una probabilidad notable (39%) de que los rusos estuvieran intentando crear una república virtualmente independiente sin poner en cuestión (formalmente) las fronteras reconocidas (modelo “Transnistria”).
- c) Tan solo unos días antes, hacia el 25-26 de febrero, la hipótesis más probable era aún que los rusos estuvieran intentando impedir que el nuevo gobierno de Kiev tomara el control efectivo de Crimea (probabilidad del 63-68%).
Con la tabla, podemos fácilmente excluir como sospechoso de desinformación un suceso que hemos aceptado previamente, modificar la verosimilitud de sucesos pasados a la luz de nueva evidencia, o cambiar las probabilidades previas de las que hemos partido. En todos estos casos, la tabla nos recalcula automáticamente todas las probabilidades.
Bayes ingenuo y Análisis de Hipótesis Alternativas (ACH)
En el fondo, la técnica de Bayes ingenuo no es muy diferente del Análisis de Hipótesis Alternativas (ACH) de Heuers. La lógica subyacente es la misma (conocer una realidad oculta gracias al estudio de sus manifestaciones visibles) y la diferencia principal radica en la forma de atacar el problema: mientras Bayes ingenuo calcula las probabilidades relativas, ACH intenta descartar hipótesis por ser inconsistentes con la evidencia.
Para ilustrar mejor las diferencias entre estas dos técnicas, hemos elaborado una matriz (prueba ach_crimea.xlsx[10]) con los sucesos y las hipótesis del ejemplo sobre Crimea. Como sabemos, las diversas variantes de ACH se diferencian entre sí por la manera de contabilizar los resultados. En nuestro caso, marcaremos CC y contaremos 2 puntos cuando el suceso sea altamente consistente con la hipótesis, C (1 punto) cuando sea consistente, I (-1) cuando sea inconsistente y X (rechazo de la hipótesis) cuando sea incompatible. Con estas reglas, hemos llegado a los resultados que a continuación se indican:
a) La hipótesis de la Anexión parece la más probable, aunque seguimos atribuyendo una probabilidad considerable a la hipótesis del Caos. Las dos primeras hipótesis (Evitar el control de Kiev sobre la península y el modelo Transnistria) podrían ser descartadas.
b) Si elimináramos la última fila, es decir, si no tomáramos en consideración el suceso del 6 de marzo, las cuatro hipótesis seguirían siendo verosímiles, con dos de ellas (Anexión y Transnistria) vistas como claramente más probables.
Vemos, pues, que partiendo de una lógica similar, las dos técnicas nos conducen a resultados ligeramente distintos. Y en el proceso podemos apreciar algunos de los inconvenientes que cada una de ellas tiene:
a) En ACH el principal problema es que no siempre resulta fácil encontrar sucesos que desmientan alguna de las hipótesis (“coartadas”) por ser completamente incompatibles con ella. Y, en ocasiones, sucesos muy interesantes pueden ser sospechosos de desinformación.
b) En ausencia de “coartadas”, la puntuación en ACH depende mucho de la metodología de cálculo que se siga. La que hemos elegido es, quizá, excesivamente simple. Otras más complejas pueden resultar difíciles de aplicar (aunque hay programas informáticos que pueden servir de ayuda) y resultar en cierta medida arbitrarias.
c) El problema con Bayes ingenuo es que para muchos analistas no resulta intuitivo. El uso de la hoja Excel ayuda mucho a realizar los cálculos, pero puede oscurecer la lógica que hay detrás de ellos.
A modo de conclusión
a) El Teorema de Bayes no sirve para predecir el futuro, sino que nos ayuda a conocer una realidad pasada o presente que permanece oculta a nuestros ojos. Es obvio que si el Presidente del país X ha decidido invadir el país vecino Y, acabará haciéndolo, de no mediar alguna circunstancia que le haga cambiar de opinión. Pero lo que averiguamos no es el hecho futuro (que invadirá), sino el pasado (que ha tomado la decisión de hacerlo).
b) Bayes ingenuo (como también ACH) es más efectivo cuando se usa para estudiar una situación estable, cuando la evidencia se puede recolectar durante un período de tiempo suficientemente largo sin que la “incógnita” que intentamos resolver cambie apreciablemente. Porque cuando la “incógnita” cambia con relativa rapidez, como suele ser el caso durante las crisis actuales, diferentes observaciones realizadas en momentos distintos pueden ser producto de una “realidad oculta” que se ha modificado, que ya no es la misma. Por eso, si queremos que Bayes ingenuo funcione razonablemente bien con situaciones dinámicas, la recogida de datos debe realizarse en plazos de tiempo relativamente cortos. O debemos descartar los “sucesos” más antiguos, que pueden responder a una “realidad oculta” que ya no es real.
c) Más importante que las dos técnicas que hemos examinado en este post es la “lógica bayesiana” que subyace a ambas. En inteligencia (sobre todo, en inteligencia estratégica) es raro conseguir evidencias directas sobre la realidad que nos interesa. Esa realidad siempre permanece oculta a nuestros ojos y lo que podemos averiguar sobre ella es gracias a sus manifestaciones visibles.
d) Quien quiera ocultar una información valiosa no solo intentará protegerla de intentos directos de acceder a ella, sino que tendrá también en cuenta esas manifestaciones visibles, tan difíciles de ocultar. Y lo hará utilizando desinformación. Este es el principal problema para utilizar Bayes ingenuo (o ACH): distinguir la información correcta de la inexacta y de la desinformacón.
Y es que no resulta nada fácil ser un analista inteligente.
[1] SOMIEDO, J.P. (2018). El análisis bayesiano como piedra angular de la inteligencia de alertas estratégicas. Revista de Estudios en Seguridad Internacional, 4, 1: 161-176. DOI: http://dx.doi.org/10.18847/1.7.10. Para una lista de las interesantes aportaciones de Somiedo al estudio de la metodología del análisis de inteligencia, ver https://dialnet.unirioja.es/servlet/autor?codigo=3971893.
[2] Para una explicación rápida del teorema de Bayes, véase https://es.wikipedia.org/wiki/Teorema_de_Bayes.
[3] Puede verse, por ejemplo, FISK, C.F. (1967). The Sino-Soviet Border Dispute: A Comparison of the Conventional and Bayesian Methods for Intelligence Warning. CIA Center for the Study of Intelligence. https://www.cia.gov/library/center-for-the-study-of-intelligence/kent-csi/vol16no2/html/v16i2a04p_0001.htm (acceso: 08.062020).
[4] Los no familiarizados con las redes bayesianas pueden encontrar una introducción elemental de este concepto en https://es.wikipedia.org/wiki/Red_bayesiana.
[5] Ver STICHA, P., BUEDE, D. & REES, R.L. (2005). APOLLO: An analytical tool for predicting a subject’s decision making. En Proceedings of the 2005 International Conference on Intelligence Analysis. https://cse.sc.edu/~mgv/BNSeminar/ApolloIA05.pdf (acceso: 08.06.2020).
[6] Los que conozcan el histórico concurso de televisión Un, dos, tres, responda otra vez recordarán que una táctica muy eficaz para responder consistía en repetir un “objeto”, alterando alguna de sus características. Por ejemplo, si pedían “muebles que puedan estar en un comedor”, ir diciendo sucesivamente “silla blanca”, “silla negra”, “silla roja”, etc. Esta táctica aplicada a la técnica de “Bayes ingenuo” nos acabaría conduciendo inexorablemente a una hipótesis predeterminada. Claro que sería como hacernos trampas al solitario…
[7] El nombre de la hoja es bayes_excel.xlsx, y puede encontrarse en https://bit.ly/2An58uc.
[8] MCLAUGHLIN, J., & PATÉ-CORNELL, M.E. (2005). A Bayesian approach to Iraq’s nuclear program intelligence analysis: a hypothetical illustration. En 2005 International Conference on Intelligence Analysis. https://analysis.mitre.org/proceedings/Final_Papers_Files/85_Camera_Ready_Paper.pdf (acceso: 27.10.2018). También, MCLAUGHLIN, J. (2005). A Bayesian Updating Model for Intelligence Analysis:A Case Study of Iraq’s Nuclear Weapons Program. Honors Program in International Security Studies Center for International Security and Cooperation Stanford University.
[9] Puede accederse a ella en la siguiente dirección: https://bit.ly/30veoY3.
[10] Puede encontrarse en https://bit.ly/3dUsENL.
Fuente: serviciosdeinteligencia.com, 2020
Algoritmos Naive Bayes: Fundamentos e Implementación
¡Conviértete en un maestro de uno de los algoritmos mas usados en clasificación!
Por Víctor Román.
Victor RomanFollowApr 25, 2019 · 13 min read

Introducción: ¿Qué son los modelos Naive Bayes?
En un sentido amplio, los modelos de Naive Bayes son una clase especial de algoritmos de clasificación de Aprendizaje Automatico, o Machine Learning, tal y como nos referiremos de ahora en adelante. Se basan en una técnica de clasificación estadística llamada “teorema de Bayes”.
Estos modelos son llamados algoritmos “Naive”, o “Inocentes” en español. En ellos se asume que las variables predictoras son independientes entre sí. En otras palabras, que la presencia de una cierta característica en un conjunto de datos no está en absoluto relacionada con la presencia de cualquier otra característica.
Proporcionan una manera fácil de construir modelos con un comportamiento muy bueno debido a su simplicidad.
Lo consiguen proporcionando una forma de calcular la probabilidad ‘posterior’ de que ocurra un cierto evento A, dadas algunas probabilidades de eventos ‘anteriores’.

Ejemplo
Presentaremos los conceptos principales del algoritmo Naive Bayes estudiando un ejemplo.
Consideremos el caso de dos compañeros que trabajan en la misma oficina: Alicia y Bruno. Sabemos que:
- Alicia viene a la oficina 3 días a la semana.
- Bruno viene a la oficina 1 día a la semana.
Esta sería nuestra información “anterior”.
Estamos en la oficina y vemos pasar delante de nosotros a alguien muy rápido, tan rápido que no sabemos si es Alicia o Bruno.
Dada la información que tenemos hasta ahora y asumiendo que solo trabajan 4 días a la semana, las probabilidades de que la persona vista sea Alicia o Bruno, son:
- P(Alicia) = 3/4 = 0.75
- P(Bruno) = 1/4 = 0.25
Cuando vimos a la persona pasar, vimos que él o ella llevaba una chaqueta roja. También sabemos lo siguiente:
- Alicia viste de rojo 2 veces a la semana.
- Bruno viste de rojo 3 veces a la semana.
Así que, para cada semana de trabajo, que tiene cinco días, podemos inferir lo siguiente:
- La probabilidad de que Alicia vista de rojo es → P(Rojo|Alicia) = 2/5 = 0.4
- La probabilidad de que Bruno vista de rojo → P(Rojo|Bruno) = 3/5 = 0.6
Entonces, con esta información, ¿a quién vimos pasar? (en forma de probabilidad)
Esta nueva probabilidad será la información ‘posterior’.

Inicialmente conocíamos las probabilidades P(Alicia) y P(Bruno), y después inferíamos las probabilidades de P(rojo|Alicia) y P(rojo|Bruno).
De forma que las probabilidades reales son:

Formalmente, el gráfico previo sería:

Algoritmo Naive Bayes Supervisado
A continuación se listan los pasos que hay que realizar para poder utilizar el algoritmo Naive Bayes en problemas de clasificación como el mostrado en el apartado anterior.
- Convertir el conjunto de datos en una tabla de frecuencias.
- Crear una tabla de probabilidad calculando las correspondientes a que ocurran los diversos eventos.
- La ecuación Naive Bayes se usa para calcular la probabilidad posterior de cada clase.
- La clase con la probabilidad posterior más alta es el resultado de la predicción.
Puntos fuertes y débiles de Naive Bayes
Los puntos fuertes principales son:
- Un manera fácil y rápida de predecir clases, para problemas de clasificación binarios y multiclase.
- En los casos en que sea apropiada una presunción de independencia, el algoritmo se comporta mejor que otros modelos de clasificación, incluso con menos datos de entrenamiento.
- El desacoplamiento de las distribuciones de características condicionales de clase significan que cada distribución puede ser estimada independientemente como si tuviera una sola dimensión. Esto ayuda con problemas derivados de la dimensionalidad y mejora el rendimiento.
Los puntos débiles principales son:
- Aunque son unos clasificadores bastante buenos, los algoritmos Naive Bayes son conocidos por ser pobres estimadores. Por ello, no se deben tomar muy en serio las probabilidades que se obtienen.
- La presunción de independencia Naive muy probablemente no reflejará cómo son los datos en el mundo real.
- Cuando el conjunto de datos de prueba tiene una característica que no ha sido observada en el conjunto de entrenamiento, el modelo le asignará una probabilidad de cero y será inútil realizar predicciones. Uno de los principales métodos para evitar esto, es la técnica de suavizado, siendo la estimación de Laplace una de las más populares.
Proyecto de Implementación: Detector de Spam
Actualmente, una de las aplicaciones principales de Machine Learning es la detección de spam. Casi todos los servicios de email más importantes proporcionan un detector de spam que clasifica el spam automáticamente y lo envía al buzón de “correo no deseado”.
En este proyecto, desarrollaremos un modelo Naive Bayes que clasifica los mensajes SMS como spam o no spam (‘ham’ en el proyecto). Se basará en datos de entrenamiento que le proporcionaremos.
Haciendo una investigación previa, encontramos que, normalmente, en los mensajes de spam se cumple lo siguiente:
- Contienen palabras como: ‘gratis’, ‘gana’, ‘ganador’, ‘dinero’ y ‘premio’.
- Tienden a contener palabras escritas con todas las letras mayúsculas y tienden al uso de muchos signos de exclamación.
Esto es un problema de clasificación binaria supervisada, ya que los mensajes son o ‘Spam’ o ‘No spam’ y alimentaremos un conjunto de datos etiquetado para entrenar el modelo.
Visión general
Realizaremos los siguientes pasos:
- Entender el conjunto de datos
- Procesar los datos
- Introducción al “Bag of Words” (BoW) y la implementación en la libreria Sci-kit Learn
- División del conjunto de datos (Dataset) en los grupos de entrenamiento y pruebas
- Aplicar “Bag of Words” (BoW) para procesar nuestro conjunto de datos
- Implementación de Naive Bayes con Sci-kit Learn
- Evaluación del modelo
- Conclusión
Entender el Conjunto de Datos
Utilizaremos un conjunto de datos del repositorio UCI Machine Learning.
Un primer vistazo a los datos:

Las columnas no se han nombrado, pero como podemos imaginar al leerlas:
- La primera columna determina la clase del mensaje, o ‘spam’ o ‘ham’ (no spam).
- La segunda columna corresponde al contenido del mensaje
Primero importaremos el conjunto de datos y cambiaremos los nombre de las columnas. Haciendo una exploración previa, también vemos que el conjunto de datos está separado. El separador es ‘\t’.
# Importar la libreria Pandas
import pandas as pd# Dataset de https://archive.ics.uci.edu/ml/datasets/SMS+Spam+Collection
df = pd.read_table('smsspamcollection/SMSSpamCollection',
sep='\t',
names=['label','sms_message'])# Visualización de las 5 primeras filas
df.head()
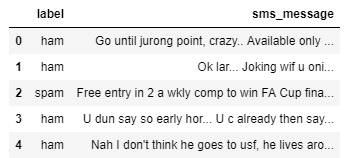
Preprocesamiento de Datos
Ahora, ya que el Sci-kit learn solo maneja valores numéricos como entradas, convertiremos las etiquetas en variables binarias, 0 representará ‘ham’ y 1 representará ‘spam’.
Para representar la conversión:
# Conversion
df['label'] = df.label.map({'ham':0, 'spam':1})# Visualizar las dimensiones de los datos
df.shape()

Introducción a la Implementación “Bag of Words” (BoW) y Sci-kit Learn
Nuestro conjunto de datos es una gran colección de datos en forma de texto (5572 filas). Como nuestro modelos solo aceptará datos numéricos como entrada, deberíamos procesar mensajes de texto. Aquí es donde “Bag of Words“ entra en juego.
“Bag of Words” es un término usado para especificar los problemas que tiene una colección de datos de texto que necesita ser procesada. La idea es tomar un fragmento de texto y contar la frecuencia de las palabras en el mismo.
BoW trata cada palabra independientemente y el orden es irrelevante.
Podemos convertir un conjunto de documentos en una matriz, siendo cada documento una fila y cada palabra (token) una columna, y los valores correspondientes (fila, columna) son la frecuencia de ocurrencia de cada palabra (token) en el documento.
Como ejemplo, si tenemos los siguientes cuatro documentos:
['Hello, how are you!', 'Win money, win from home.', 'Call me now', 'Hello, Call you tomorrow?']
Convertiremos el texto a una matriz de frecuencia de distribución como la siguiente:

Los documentos se numeran en filas, y cada palabra es un nombre de columna, siendo el valor correspondiente la frecuencia de la palabra en el documento.
Usaremos el método contador de vectorización de Sci-kit Learn, que funciona de la siguiente manera:
- Fragmenta y valora la cadena (separa la cadena en palabras individuales) y asigna un ID entero a cada fragmento (palabra).
- Cuenta la ocurrencia de cada uno de los fragmentos (palabras) valorados.
- Automáticamente convierte todas las palabras valoradas en minúsculas para no tratar de forma diferente palabras como “el” y “El”.
- También ignora los signos de puntuación para no tratar de forma distinta palabras seguidas de un signo de puntuación de aquellas que no lo poseen (por ejemplo “¡hola!” y “hola”).
- El tercer parámetro a tener en cuenta es el parámetro
stop_words. Este parámetro se refiere a las palabra más comúnmente usadas en el lenguaje. Incluye palabras como “el”, “uno”, “y”, “soy”, etc. Estableciendo el valor de este parámetro por ejemplo enenglish, “CountVectorizer” automáticamente ignorará todas las palabras (de nuestro texto de entrada) que se encuentran en la lista de “stop words” de idioma inglés..
La implementación en Sci-kit Learn sería la siguiente:
# Definir los documentos
documents = ['Hello, how are you!',
'Win money, win from home.',
'Call me now.',
'Hello, Call hello you tomorrow?']# Importar el contador de vectorizacion e inicializarlo
from sklearn.feature_extraction.text import CountVectorizer
count_vector = CountVectorizer()# Visualizar del objeto'count_vector' que es una instancia de 'CountVectorizer()'
print(count_vector)

Para ajustar el conjunto de datos del documento al objeto “CountVectorizer” creado, usaremos el método “fit()”, y conseguiremos la lista de palabras que han sido clasificadas como características usando el método “get_feature_names()”. Este método devuelve nuestros nombres de características para este conjunto de datos, que es el conjunto de palabras que componen nuestro vocabulario para “documentos”.
count_vector.fit(documents)
names = count_vector.get_feature_names()
names
A continuación, queremos crear una matriz cuyas filas serán una de cada cuatro documentos, y las columnas serán cada palabra. El valor correspondiente (fila, columna) será la frecuencia de ocurrencia de esa palabra (en la columna) en un documento particular (en la fila).
Podemos hacer esto usando el método “transform()” y pasando como argumento en el conjunto de datos del documento. El método “transform()” devuelve una matriz de enteros, que se puede convertir en tabla de datos usando “toarray()”.
doc_array = count_vector.transform(documents).toarray()
doc_array

Para hacerlo fácil de entender, nuestro paso siguiente es convertir esta tabla en una estructura de datos y nombrar las columnas adecuadamente.
frequency_matrix = pd.DataFrame(data=doc_array, columns=names)
frequency_matrix

Con esto, hemos implementado con éxito un problema de “BoW” o Bag of Words para un conjunto de datos de documentos que hemos creado.
Un problema potencial que puede surgir al usar este método es el hecho de que si nuestro conjunto de datos de texto es extremadamente grande, habrá ciertos valores que son más comunes que otros simplemente debido a la estructura del propio idioma. Así, por ejemplo, palabras como ‘es’, ‘el’, ‘a’, pronombres, construcciones gramaticales, etc. podrían sesgar nuestra matriz y afectar nuestro análisis.
Para mitigar esto, usaremos el parámetro stop_words de la clase CountVectorizer y estableceremos su valor en inglés.
Dividiendo el Conjunto de Datos en Conjuntos de Entrenamiento y Pruebas
Buscamos dividir nuestros datos para que tengan la siguiente forma:
X_trainson nuestros datos de entrenamiento para la columna ‘sms_message’y_trainson nuestros datos de entrenamiento para la columna ‘label’X_testson nuestros datos de prueba para la columna ‘sms_message’y_testson nuestros datos de prueba para la columna ‘label’. Muestra el número de filas que tenemos en nuestros datos de entrenamiento y pruebas
# Dividir los datos en conjunto de entrenamiento y de test
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(df['sms_message'], df['label'], random_state=1)print('Number of rows in the total set: {}'.format(df.shape[0]))print('Number of rows in the training set: {}'.format(X_train.shape[0]))print('Number of rows in the test set: {}'.format(X_test.shape[0]))

Aplicar BoW para Procesar Nuestros Datos de Pruebas
Ahora que hemos dividido los datos, el próximo objetivo es convertir nuestros datos al formato de la matriz buscada. Para realizar esto, utilizaremos CountVectorizer() como hicimos antes. tenemos que considerar dos casos:
- Primero, tenemos que ajustar nuestros datos de entrenamiento (
X_train) enCountVectorizer()y devolver la matriz. - Sgundo, tenemos que transformar nustros datos de pruebas (
X_test) para devolver la matriz.
Hay que tener en cuenta que X_train son los datos de entrenamiento de nuestro modelo para la columna ‘sms_message’ en nuestro conjunto de datos.
X_test son nuestros datos de prueba para la columna ‘sms_message’, y son los datos que utilizaremos (después de transformarlos en una matriz) para realizar predicciones. Compararemos luego esas predicciones con y_test en un paso posterior.
El código para este segmento está dividido en 2 partes. Primero aprendemos un diccionario de vocabulario para los datos de entrenamiento y luego transformamos los datos en una matriz de documentos; segundo, para los datos de prueba, solo transformamos los datos en una matriz de documentos.
# Instantiate the CountVectorizer method
count_vector = CountVectorizer()# Fit the training data and then return the matrix
training_data = count_vector.fit_transform(X_train)# Transform testing data and return the matrix. Note we are not fitting the testing data into the CountVectorizer()
testing_data = count_vector.transform(X_test)
Implementación Naive Bayes con Sci-Kit Learn
Usaremos la implementación Naive Bayes “multinomial”. Este clasificador particular es adecuado para la clasificación de características discretas (como en nuestro caso, contador de palabras para la clasificación de texto), y toma como entrada el contador completo de palabras.
Por otro lado el Naive Bayes gausiano es más adecuado para datos continuos ya que asume que los datos de entrada tienen una distribución de curva de Gauss (normal).
Importaremos el clasificador “MultinomialNB” y ajustaremos los datos de entrenamiento en el clasificador usando fit().
from sklearn.naive_bayes import MultinomialNB
naive_bayes = MultinomialNB()
naive_bayes.fit(training_data, y_train)

Ahora que nuestro algoritmo ha sido entrenado usando el conjunto de datos de entrenamiento, podemos hacer algunas predicciones en los datos de prueba almacenados en ‘testing_data’ usando predict().
predictions = naive_bayes.predict(testing_data)
Una vez realizadas las predicciones el conjunto de pruebas, necesitamos comprobar la exactitud de las mismas.
Evaluación del modelo
Hay varios mecanismos para hacerlo, primero hagamos una breve recapitulación de los criterios y de la matriz de confusión.
- La matriz de confusión es donde se recogen el conjunto de posibilidades entre la clase correcta de un evento, y su predicción.
- Exactitud: mide cómo de a menudo el clasificador realiza la predicción correcta. Es el ratio de número de predicciones correctas contra el número total de predicciones (el número de puntos de datos de prueba).
- Precisión: nos dice la proporción de mensajes que clasificamos como spam. Es el ratio entre positivos “verdaderos” (palabras clasificadas como spam que son realmente spam) y todos los positivos (palabras clasificadas como spam, lo sean realmente o no)
- Recall (sensibilidad): Nos dice la proporción de mensajes que realmente eran spam y que fueron clasificados por nosotros como spam. Es el ratio de positivos “verdaderos” (palabras clasificadas como spam, que son realmente spam) y todas las palabras que fueron realmente spam.
Para los problemas de clasificación que están sesgados en sus distribuciones de clasificación como en nuestro caso. Por ejemplo si tuviéramos 100 mensajes de texto y solo 2 fueron spam y los restantes 98 no lo fueron, la exactitud por si misma no es una buena métrica. Podríamos clasificar 90 mensajes como no spam (incluyendo los 2 que eran spam y los clasificamos como “no spam”, y por tanto falsos negativos) y 10 como spam (los 10 falsos positivos) y todavía conseguir una puntuación de exactitud razonablemente buena.
Para casos como este, la precisión y el recuerdo son bastante adecuados. Estas dos métricas pueden ser combinadas para conseguir la puntuación F1, que es el “peso” medio de las puntuaciones de precisión y recuerdo. Esta puntuación puede ir en el rango de 0 a 1, siendo 1 la mejor puntuación posible F1.
Usaremos las cuatro métricas para estar seguros de que nuestro modelo se comporta correctamente. Para todas estas métricas cuyo rango es de 0 a 1, tener una puntuación lo más cercana posible a 1 es un buen indicador de cómo de bien se está comportando el modelo.
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_scoreprint('Accuracy score: ', format(accuracy_score(y_test, predictions)))print('Precision score: ', format(precision_score(y_test, predictions)))print('Recall score: ', format(recall_score(y_test, predictions)))print('F1 score: ', format(f1_score(y_test, predictions)))

Conclusión
- Una de las mayores ventajas que Naive Bayes tiene sobre otros algoritmos de clasificación es la capacidad de manejo de un número extremadamente grande de características. En nuestro caso, cada palabra es tratada como una característica y hay miles de palabras diferentes.
- También, se comporta bien incluso ante la presencia de características irrelevantes y no es relativamente afectado por ellos.
- La otra ventaja principal es su relativa simplicidad. Naive Bayes funciona bien desde el principio y ajustar sus parámetros es raramente necesario.
- Raramente sobreajusta los datos.
- Otra ventaja importante es que su modelo de entrenamiento y procesos de predicción son muy rápidos teniendo en cuenta la cantidad de datos que puede manejar.
Fuente: medium.com, 2019

Vincúlese a nuestras Redes Sociales:
LinkedIn YouTube Facebook Twitter
.
.
Para saber más sobre Big Data
mayo 9, 2020
Big Data. Conceptos, tecnologías y aplicaciones

El libro que tengo en las manos es una excelente aportación para el conocimiento del público en general del gran paradigma que conmueve los cimientos de nuestro mundo, el Big Data. Se trata de Big Data. Conceptos, tecnologías y aplicaciones, en la colección Qué sabemos de, escrito por dos expertos, David Ríos Insúa y David Gómez Ullate.
Comentaremos brevemente el contenido de este libro, aunque en entradas sucesivas seguiremos hablando de algunos de los temas que, al menos a mí, me han resultado tan interesantes como para querer saber más sobre ellos.
Una de las cuestiones más preocupantes del big data es que una gran parte de ese tsunami de datos lo estamos proporcionando nosotros mismos de manera gratuita y casi sin darnos cuenta, como si no nos importara. Y con esos datos, hay compañías que hacen negocios. Google recibe 4 millones de peticiones por minuto, en Facebook compartimos 2 millones y medio de piezas por minuto, cada día enviamos 400 millones de tuits.

La importancia de los datos y su análisis tiene un origen comercial, como conocer mejor a los clientes, sus gustos, como llegar mejor a ellos. Y si antiguamente (por ejemplo, Gallup) había que hacer encuestas, los avances tecnológicos (internet, móviles, GPS, …) han facilitado la tarea. Se dice que hay unos 15.000 millones de sensores distribuidos en el mundo, y no paran,
Pero estos datos se dan en bruto, tenemos que pulirlos y almacernarlos para poder usarlos. Y después tenemos que aplicar diferentes tecnologías para extraer información útil de los mismos. Y ahí es donde entran las matemáticas. Los autores muestran como una de las bases claves es la Estadística. El otro pilar es la Infomática. A lo largo del libro describen ampliamente como estas dos disciplinas interactúan en el Big Data. Y ello les lleva a hablar del aprendizaje automático (machine learning), redes neuronales, inteligencia artificial, ciberseguridad, y muchos otros temas.
Es muy relevante como las administraciones públicas están tan lejos de las grandes corporaciones empresariales y no están utilizando estas nuevas herramientas en beneficio de la sociedad; hay un enorme potencial en su uso, por ejemplo, en la medicina, tal y como detallan en uno de sus capítulos.
Aunque a veces la lectura nos produce el temor al Gran Hermano, los aspectos positivos son muchos, como ocurre casi siempre con la ciencia. El Big Data no es la panacea a todos los problemas de este mundo pero si que nos ofrece un gran cantidad de oportunidades. Enhorabuena a los autores por este magnífico libro que en apenas 134 páginas no nos da respiro.

{kind=link}
David Ríos Insúa. Es AXA-ICMAT Chair en Análisis de Riesgos Adversarios en el ICMAT-CSIC y numerario de la Real Academia de Ciencias Exactas, Físicas y Naturales. Es catedrático de Estadística e Investigación Operativa (en excedencia). Previamente ha sido profesor o investigador en Manchester, Leeds, Duke, Purdue, Paris-Dauphine, Aalto, CNR-IMATI, IIASA, SAMSI y UPM. Entre otros, ha recibido el Premio DeGroot de la ISBA por su libro Adversarial Risk Analysis. Es asesor científico de Aisoy Robotics. Ha escrito más de 130 artículos con revisión y 15 monografías sobre sus temas de interés que incluyen la inferencia bayesiana, la ciencia de datos, el análisis de decisiones y el análisis de riesgos, y sus aplicaciones, principalmente, a seguridad y ciberseguridad.
{kind=link}
David Gómez-Ullate Oteiza. Es investigador en la Universidad de Cádiz y profesor titular de Matemática Aplicada en la Universidad Complutense de Madrid. Su labor reciente se centra en la transferencia de conocimiento al sector industrial en ciencia de datos e inteligencia artificial. Dirige proyectos en el sector aeronáutico, seguros y biomédico aplicando técnicas de visión artificial y procesamiento de lenguaje natural.
___
Manuel de León (CSIC, Fundador del ICMAT, Real Academia de Ciencias, Real Academia Canaria de Ciencias, Real Academia Galega de Ciencias).
Fuente: madrimasd.org, 2020.
Vincúlese a nuestras Redes Sociales:
LinkedIn YouTube Facebook Twitter
.
.